MYSQL分表分库 详解
目录
一、垂直拆分于水平拆分的区别?
数据库拆分主要有两种方式:垂直拆分和水平拆分。
垂直拆分
按业务进行拆分,将不同业务功能相关的表放到不同的数据库中,也就是类似于微服务架构的积分数据库/订单数据库/支付数据库。
要注意分布式事务问题。
水平拆分
将一张数据量很大的表拆分成n多张不同的子表来进行存放。
当一张表的业务量行数超过500万行或者单表容量超过2GB,可以对同一张表数据实现拆分放到多个不同的表中存放(阿里巴巴开发手册推荐)。
二、分表分库有哪些策略?
(1)日期
(2)Hash
(3)范围
(4)枚举
Hash分片策略
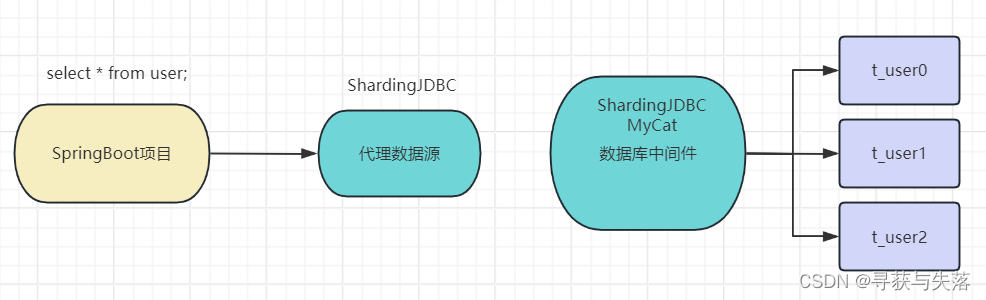
如何分表?
数据插入时:
1、定义一个全局ID,根据该全局ID采用分片算法,计算该条数据应该落地存放到具体哪张表。
2、该全局ID特点:有序且递增,推荐序列。
ID值%表数量比如:我们t_user分表的数量是3
? ? ? ? 1%3 = 1? 最后落到表t_user1
? ? ? ? 2%3 = 2??最后落到表t_user2
? ? ? ? ...
如何查询呢?
比如我们一开始是按照ID去分表的,那我在查询的时候,select * from user where id = 2; 这条语句会被数据库中间件拦截并解析这条SQL语句,将id%3进行计算,最后落到对应的表上。
优点:将数据可以分摊的形式存放,均匀的形式存放。
缺点:Hash分片策略有个很大的缺点就是无法支持新增表的扩容。比如你之前分了3张表,现在增加两张,那以前3%3的时候结果是0,查询t_user0表,现在3%5,结果肯定不一样了。
枚举分片策略
比如我们根据省份分表,黑龙江省一张表、辽宁省一张表、吉林省一张表。
那么我们查询的时候,就要带上省份条件,如:select * from user where?province = '黑龙江省' limit 0,2;
优点:好扩容。
缺点:数据分布不够均匀。
日期分片策略
比如我们2024年1月一张表,2024年2月一张表...以此类推。
优点:可以无限扩容。
缺点:有淡季有旺季,比如双11时,表的数据量会猛增,导致存放数据不均匀。
范围分片策略(用的较多)
假设一张表存放的数据 500 万。
以每张 500 万条数据的形式来进行分表。
t_user0表?0-500 万条数据。
t_user1表 500-1000 万条数据。
t_user2表 1000 1500 万条数据。
优点:这种方式的优点是可以无限扩容表,比如我插入更多的数据,直接再加一张t_user3表去存储1500?- 2000万的数据。
查询的时候也很简单,直接id值/500万,结果再进行向上取整即可。
缺点:数据分布不够均匀。
三、分表分库之后,如何查询的呢?
首先注意的是,查询语句需要带上分片的字段,也就是说,你当初用哪个字段分的片,现在就得带上那个字段去查询。
如果你当初用ID字段分片分表,我使用select * from user where name = 'CLAY';查询时,数据库中间件就会查询所有的表,现在查询t_user0,逐条查询,查询完再查t_user1,以此类推。
四、分表分库之后,分页如何做?
如果带上分片字段查询,很好想不用多说。
如果不带上分片字段查询,比如select * from user where address = '黑龙江省哈尔滨市' limit 0,2;
那么数据库中间件就会去每张表(t_user0、t_user1、t_user2)查询出符合条件的两条记录,总共就是6条,然后再选出两条记录返回。
五、分库分表之后,排序如何做?
会依次查询所有表,比如select * from user where age > 18 order by age desc;
(1)查询t_user0表,先按age排序,然后取出大于18岁的人,假如取出3条。
(2)查询t_user1表,先按age排序,然后取出大于18岁的人,假如取出2条。
(3)查询t_user2表,先按age排序,然后取出大于18岁的人,假如取出5条。
(4)数据库中间件会将这些数据合并成一个结果集,成为10条。
(5)然后再将这10条进行二次排序。
六、MyCat与ShardingJDBC比较
Mycat 是基于服务器端实现代理,需要单独部署,有独立的IP端口号,所以较安全,但效率差点,因为是走网络通讯的,SpringBoot项目走到MyCat需要网络进行通讯。
Shardingjdbc 是基于客户端改写 sql 语句代理,效率较高。
相对于来说 Shardingjdbc 效率比 Mycat 高。
Mycat 比 Shardingjdbc 更加安全。
如果数据量较大,还是建议使用MyCat,如果使用ShardingJDBC很容易内存溢出,影响到我们SpringBoot项目,因为这俩没有解耦。但MyCat挂了,至少不会影响我们的SpringBoot项目。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- js中Document的常用属性和方法
- Java二叉树的遍历以及最大深度问题
- 【Linux】不常用命令记录
- 在线负公差测径仪 生产场景智能化
- AI全栈大模型工程师(五)Prompt 的构成
- [自用代码]基于LSTM的广州车牌售价预测
- Vue - 使用XLSX插件进行文件导出
- SpringBoot+SSM项目实战 苍穹外卖(5)(Redis入门)
- 当一堆数据差异过大如何选?
- Visual Studio Code如何连接Gitee仓库进行代码管理——详细步骤