BGP路由知识点
目录
BGP(Border Gateway Protocol)是一种用于自治系统(AS)之间的路由选择协议。它是互联网中最常用的外部网关协议,负责在不同自治系统之间交换网络前缀信息,以便实现跨网络的数据转发。
我们首先应当弄清,在不同自治系统AS 之间的路由选择为什么不能使用内部协议,如RIP或OSPF?
我们知道,内部网关协议(如RIP或OSPF)主要是设法使数据报在一个AS 中尽可能有效地从源站传送到目的站。在一个 AS内部也不需要考虑其他方面的策略。然而 BGP使用的环境却不同。这主要是因为以下的两个原因:
第一,互联网的规模太大,使得自治系统AS之间路由选择非常困难。连接在互联网主干网上的路由器,必须对任何有效的 IP 地址都能在转发表中找到匹配的网络前缀。目前在互联网的主干网路由器中,一个转发表的项目数甚至可达到50万个网络前缀。如果使用链路状态协议,则每一个路由器必须维持一个很大的链路状态数据库。对于这样大的主干网用Dikstra 算法计算最短路径时花费的时间也太长。另外,由于自治系统AS各自运行自己选定的内部路由选择协议,并使用本 AS 指明的路径度量,因此,当一条路径通过几个不AS时,要想对这样的路径计算出有意义的代价是不太可能的。例如,对某 AS来说,代价为1000可能表示一条比较长的路由。但对另一AS,代价为 1000却可能表示不可接受的坏路由。因此,对于自治系统AS之间的路由选择,要用“代价”作为度量来寻找最佳路由也是很不现实的。比较合理的做法是在自治系统之间交换“可达性”信息(即“可到达”或“不可到达”)。例如,告诉相邻路由器:“到达网络前缀N可经过自治系统”。
第二,自治系统AS之间的路由选择必须考虑有关策略。由于相互连接的网络的性能相差很大,根据最短距离(即最少跳数)找出来的路径,可能并不合适。也有的路径的使用代价很高或很不安全。还有一种情况,如自治系统AS1要发送数据报给自治系统AS2,本来最好是经过自治系统AS3。但AS3不愿意让这些数据报通过本自治系统的网络,即使AS1愿意付一定的费用。但另一方面,自治系统 AS3 愿意让某些相邻自治系统的数据报通过自己的网络,特别是对那些付了服务费的某些自治系统更是如此。因此,自治系统之间的路由选择协议应当允许使用多种路由选择策略。这些策略包括政治、安全或经济方面的考虑。例如,我国国内的站点在互相传送数据报时不应经过国外兜圈子,特别是,不要经过某些对我国的安全有威胁的国家。这些策略都是由网络管理人员对每一个路由器进行设置的,但这些策略并不是自治系统之间的路由选择协议本身。还可举出一些策略的例子,如:“仅在到达下列这些地址时才经过 ”,“
和
相比时应优先通过
”,等等。显然,使用这些策略是为了找出较好的路由而不是最佳路由。
所以边界网关协议 BGP 只能是力求选择出一条能够到达目的网络目比较好的路由(不能兜圈子)而并非要计算出一条最佳路由。这里所说的 BGP路由,是指经过哪些自治系统AS 可以到达目的网络前缀。当然,这选择出的比好的路由,也有时不严格地称为最佳路由。BGP采用了路径向量(path vector)路由选择协议,它与距离向量协议(如RIP)和链路状态协议(如 OSPF)都有很大的区别。
1.BGP的工作原理:
在一个自治系统 AS中有两种不同功能的路由器,即边界路由器(或边界网关)和内部路由器,一个AS至少要有一个边界路由器和相邻 AS 的边界路由器直接相连。
当两个边界路由器(如图(a)中的 R1和 R2)进行通信时,必须先建立TCP连接(端口号为 179),这种TCP 连接又称为半永久性连接(即双方交换完信息后仍然保持着连接状态)。像 R1和 R2之间的这种连接称为 eBGP 连接,e表示外部 extemal。现在,边界路由器 R1 可通过 eBGP 向对等端R2发送BGP路由“X,AS1,R1”,意思是“从R1经AS1可到达X”。这样,通过eBGP连接,AS2中的边界路由器R2,就知道了到达AS1中的前缀X的BGP路由。

但是,仅有边界路由器 R2 知道“到AS1的前缀X的BGP 路由”是远远不够的。边界路由器R2应当把获得的 BGP路由,再转发给AS内部的其他路由器。为此,协议 BGP 规定,在AS 内部,两个路由器之间还需要建立 iBGP(也就是 BGP 连接,i表示内部ntemal),iBGP也使用TCP连接传送 BGP报文。如图(b)中表示边界路由器 R2 在三个iBGP 连接上,向 AS2内部的其他三个路由器转发自己收到的 BGP 路由。至此,AS2内的所有路由器都知道了这条 BGP 路由信息。由此可见,协议 BGP 并非仅运行在AS之间,而且也要运行在AS的内部。
注:
这里要说明一下。图(a)中的边界路由器 R1 通告给边界路由器 R2的 BGP 路由可能有很多条(在图中只画出了一条)。但 R2根据本 AS 管理员所规定的策略,可以拒绝某些由(收到这种路由后即删除掉),而在 iBGP连接上仅转发符合规定策略的 BGP路由。
协议BGP规定,在一个AS 内部所有的 iBGP 必须是全连通的。即使两个路由器之间没有物理连接,但它们之间仍然有iBGP 连接。

iBGP和eBGP的关联:
从 eBGP 对等端收到的BGP路由,可通过iBGP告诉同一AS内的对等端。反过来也是可以的,即从iBGP对等端收到的 BGP 路由,可通过 eBGP 告诉在不同AS的对等端。但是,从 iBGP 对等端收到BGP路由,不能转告给同一个AS内不同iBGP的对等端。

上图中,每一个AS都必须运行本AS选择的内部网关协议IGP,例如OSPF或RIP。而协议BGP是在iBGP连接和eBGP连接之上运行的。
还有一个问题,当AS2内的路由器R4在收到BGP路由“X,AS1,R1”后,知道了“从R1出发就能到达AS1中的前缀X”,但是路由器R4应当怎样构造自己的转发表呢? 这需要经过两次递归查找。
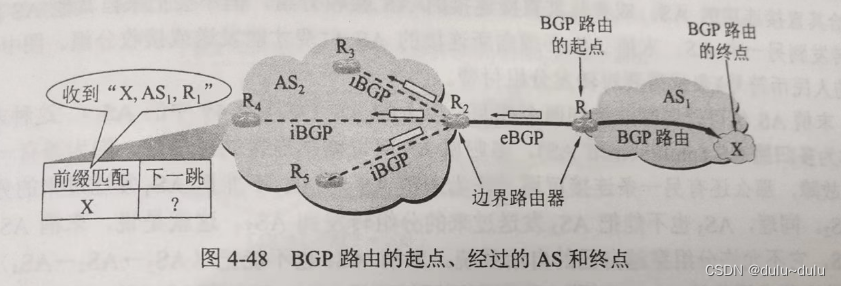
首先,R4要把这条 BGP 路由的起点进行转换。原来的 BGP 路由是“R1一>X”,路由的起点 R1 并不在 AS2中。AS2中的路由器都不能识别 R1。因此现在 R4 要把 BGP 路由的起点改为R1 的对等端R2,把BGP 路由变为“R2一>R1一>X”。由于R2位于AS2中,因此AS,里面的所有路由器都能把分组转发到R2,然后就能再经过 R1,最后到达前缀X。
其次,R4要利用内部网关协议,找到从 R4到 R2的最佳路由中的下一跳。在本例中,查出下一跳是 R3,于是R4在转发表中增加了到达前缀X的下一跳是 R3这一项目。

用类似的方法,路由器 R3 也在自己的转发表中增加了到达前缀X的项目。

这样,路由器R4只要收到要到达前缀X的分组,都按照R4-->R3-->R2-->R1-->X的路径最后到达前缀X。
总之,每一个路由器收到一条新的 BGP 路由通告后,必须经过上述步骤,才能在自的转发表中,增加到达终点的“下一跳”的相应项目。
在实际的转发表中,“前缀匹配”项目都用 CIDR 记法表示。由于路由器有两个以接口,因此“下一跳”项目用进入该路由器的接口的IP 地址来表示。
2.BGP路由的一般格式:

前缀就是通告的 BGP 路由终点(子网前缀)。
BGP属性有好几种类型,但最重要两个就是这里列出的AS-PATH和NEXT-HOP。
AS-PATH(自治系统路径)是通告的 BGP 路由所经过的自治系统。BGP 路由每经过一个AS,就将其自治系统号 ASN 加入到 AS-PATH 中。从这里可以清楚地看出,“BGP路由必须指出通过哪些自治系统AS,但不指出路由中途要通过哪些路由器。
NEXT-HOP(下一跳)是通告的 BGP 路由起点。
3.三种不同的自治系统AS
在互联网中自治系统 AS 的数量非常之多,其连接图也是相当复杂的。但归纳起来,可以把AS划分为图中所示的三大类,即末梢AS (stub AS)、穿越AS(transit AS)和对等AS(peering AS)。

末梢AS 是比较小的AS(如图中的AS4?,AS5和AS6,其特点是这些AS 或者把分组发送给其直接连接的 AS,或者从其直接连接的 AS 接收分组,但不会把来自其他 AS 的分再转发到另一个 AS。末梢 AS 必须向所连接的 AS 付费才能发送或接收分组。
末梢AS也可以同时连接到两个或两个以上的 AS(如图中的 AS5)。这种末梢AS就称为多归属AS(multihomed AS)。多归属AS可以增加连接的可靠性,因为若有一条连接出现故障,那么还有另一条连接可用。作为末梢AS的AS5不能把AS3发送过来的分组转发到AS2。同理,AS5也不能把 AS2发送过来的分组转发到 AS3。这就是说,末梢?AS 不是穿越?AS,它不允许分组穿越自己的自治系统。末梢 AS也不能把(AS5-->AS2-->AS4)这样的BGP路由信息通告给AS3。如果AS3有分组要转发给AS4,可以通过对等AS2转发,但不能通过末梢AS5。
如图所示的穿越AS1往往是拥有很好的高速通信干线的主干AS,其任务就是为其他的AS有偿转发分组。通常都会有很多的AS 连接到穿越AS上。
对等AS(如图中的AS2和AS3)是经过事先协商的两个 AS,彼此之间的发送或接收分组都不收费,这样大家转发分组都比较方便。
注:BGP 路由必须避免兜圈子的出现。AS3向AS1通告可到达 AS6 的 BGP 路由中的属性AS-PATH 是[AS3,AS6],AS1在收到的 BGP 路由的属性 AS-PATH 中的最前面,添加上自己的 AS,通报给 AS2:[AS1 AS3 AS6]。AS2收到 BGP 路由后,向AS3通报 BGP 路由属性AS-PATH是[AS2 AS1 AS3 AS6] 。当AS3收到BGP路由后,检查属性AS-PATH序列中已经有了自己的AS3,如果AS3接受这个路由,并添加上本 AS 号,则将在属性 AS-PATH 中出现两个 AS3 :[AS3 AS2 AS1 AS3 AS6 ]。这就构成了一个兜圈子的 BGP 路由,因此AS3应立即删除此BGP路由,因而避免了兜圈子路由的出现。也就是说,在属性 AS-PATH 中不允许出现相同的AS。
AS3还可向AS2通报可到达 AS6 的另一条 BGP 路由,其AS-PATH是[AS3 AS6]。因此AS2知道有两条BGP路由可到达AS6,其AS-PATH是[AS2 AS1 AS3 AS6]和[AS2 AS3 AS6]。
4.BGP的路由选择
假如从一个 AS到另外一个 AS 中的前缀X 只有一条 BGP 路由,那么就不存在选择BGP路由的问题,因为这时BGP路由是唯一的。
但如果到前缀X有两条或更多的 BGP 路由可供选择,那么就应当根据以下的原则,按照这里给出的先后顺序,选择一条较好的BGP路由。
(1)本地偏好LOCAL-PREF(LOCAL PREFerence)值最高的路由要首先选择。
在BGP路由中的属性里面有一个选项叫作本地偏好,在属性中记为 LOCAL-PREF。本地偏好也就是本地优先,“本地”的意思是指,从本 AS 开始的、到同一个前缀的不同 BGP路由中,挑选一个较好的(即偏好值最高的)路由。这可由路由器管理员或网络管理员根据政治上或经济上的策略来设置。
例如在图中,AS分别用高速和低速链路连接到AS2和AS3,并从这两个 AS获悉可通过AS2或AS3到达AS4。但AS1认为,若有分组要从AS1转发到AS4,应优先选择路由器R1离开AS1。于是就把从 R1离开AS1的BGP 路由的属性 LOCAL-PREF 值设为 300,而把从R2离开AS1的 BGP 路由的 LOCAL-PREF 值设为 200。这一信息通过i BGP通告AS1内部的所有路由器。这样,凡是有分组要转发到 AS4,都优先选择从R1离开AS1。

但是,即使所有的通信量都通过这条高速链路,使得链路负荷过重,协议 BGP 也无法把一些负载调整到负载较轻的那条低速链路上。
如果从几条 BGP路由中找不出本地偏好值最高的路由,则执行下一条。
(2)选择具有AS跳数最少的路由。
现观察图中的例子。从AS1到AS5共有两条 BGP 路由,即AS1-AS2-AS3-AS5和AS1一AS4一AS5。根据选择具有AS 跳数最少的原则,我们应选择只通过1个AS的BGP路由,即 AS1一AS4一AS5。但是没有想到,分组在 AS4 中反而要经过更多次数的转发(或许AS4是个很大的 AS),可能要花费更长的时间。可见选择经过 AS 数量最少的路 AS1一AS4一AS5未必更好。这个例子再次说明了协议 BGP 无法选择出最佳路由。

(3)使用热土都路由选择算法
如果按前两种方法都无法选择最好的路由,那么就在要进入 BGP路由的AS,执行热土豆路由选择算法。例如在图中,从AS1出发,共有两条BGP路由可到达AS3:
BGP路由1:从R3离开AS1,然后进入AS2,再到AS3。
BGP路由2:从R4离开AS1,然后进入AS2,再到AS3。

假定这两跳BGP路由的本地偏好相同,同时所经过的AS个数也相同。在这种情况下,AS1中的每一个路由器,就应采用热土豆路由选择算法。这种算法把分组比喻为烫手的热土豆,要尽快地转发出去。对于图中的例子,就是要使分组尽快离开 AS1,而不考虑从哪个路由器离开 AS1。或者说,要让分组经过最少的转发次数离开本 AS。这时要使用内部网关协议(如协议 OSPF或RIP)。对于不同的路由器,得出的选择结果是不同的。
例如,对于 AS1中的路由器 R1,若要使转发的分组尽快离开 AS1,应选择 R4作为其下一跳,因此应选择BGP路由2。这样,R1的转发路径应当是:R1一R4一BGP路由2。同理,对于 R2,若要使转发的分组尽快离开 AS1,应选择 R3 作为其下一跳,因此应选择BGP路由1。这样,R2的转发路径应当是:R2一R3一BGP路由1。
(4)选择路由器BGP标识符的数值最小的路由。
当以上几种方法都无法找出最好的 BGP路由时,就可使用BGP标识符来选择路由。在BGP进行交互的报文中,其首部有一 4 字节的字段,叫作 BGP 标识符,记为 BGP ID。这个字段被赋予一个无符号整数作为运行 BGP 的路由器的唯一标识符。具有多个接口的路由器有多个IP地址。BGP ID就使用该路由器的 IP 地址中数值最大的一个。
5.BGP的四种报文
在协议 BGP 刚运行时,BGP 连接的对等端要相互交换整个的 BGP 路由表。但需要在 BGP路由发生变化时,才更新有变化的部分。这样做对节省网络带宽和减少路的处理开销方面都有好处。
在RFC4271中规定了BGP-4的四种报文:
(1)OPEN(打开)报文,用来与BGP连接对等端建立关系。
(2)UPDATE(更新)报文,用来通告某一路由的信息,以及列出要撤销的路由。
(3)KEEPALIVE(保活)报文,用来周期性地证实与对等端的连通性。
(4)NOTIFICATION(通知)报文,用来发送检测到的差错。
OPEN 报文是两个路由器之间建立了 TCP连接后接着就必须发送的报文。OPEN报的作用是相互识别对方,协商一些协议参数(如计时器的时间)。收到 OPEN 报文的路由就发回KEEPALIVE报文表示接受建立BGP连接。
UPDATE报文是BGP协议的核心,用来撤销它以前曾经通知过的路由,或宣布增加新的路由。撤销路由可以一次撤销许多条,但增加新路由时,每个更新报文只能增加一条。
虽然BGP连接的两端建立了 TCP连接,传输报文是可靠的,但TCP上层的BGP是否始终正常工作还无法确知。在对等端之间定期传送BGP路由表是不可取的,因为BGP路表往往过于庞大,这样做会使网络的通信量过大。因此协议 BGP 采用的方法是让 BGP连接的两个对等端之间,周期性地交换 KEEPALIVE 报文,以表示协议工作正常。KEEPALIVE报文只包含 BGP 报文的通用首部 (19 字节长),因此不会在网络上产生多少开销。
每个路由器都有一个保持时间计时器(Hold Timer)。路由器每收到一个BGP报文,这个计时器就重置一次,继续从0开始计时。如果在商定的保持时间内没有收到对等端发来的任何一种BGP报文,就认为对方已经不能工作了。发送 KEEPALIVE 报文的时间间隔取为双方事先商定的保持时间(Hold Time)的 1/3。例如,在 BGP 连接建立阶段,双方商定保持时间为180秒,那么KEEPALIVE 报文就每隔60秒发送一次。如果两个对等端选择的保持时间不一致,就选择数值较小的一个作为彼此使用的保持时间。保持时间也可选择为 0。在这种情况下就永远不发送KEEPALIVE 报文,表明这条BGP 连接总是正常工作的。
BGP 可以很容易地解决距离向量路由选择算法中的“坏消息传播得慢”这一问题。当某个路由器或链路出故障时,可以从不止一个邻站获得路由信息,因此很容易选择出新的路由。
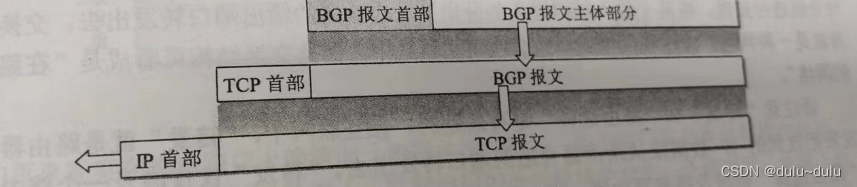
BGP报文是作为 TCP报文的数据部分来传送的(如图所示)。四种类型的BGP报文具有同样的首部。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 开源内容管理框架Drupal在Docker本地部署并实现公网远程访问
- 修改汽车的控制系统实现自动驾驶,基于一个开源的汽车驾驶辅助系统实现全自动驾驶
- 不同知识表示方法与知识图谱
- Mongodb基础知识详解(值得珍藏)
- Figma怎么设置中文,Figma有中文版吗?
- 磁盘性能测试
- 购买cdn节点怎么接入服务器-速盾网络
- Nginx服务器配置SSL证书
- SecuSphere:一款功能强大的一站式高效DevSecOps安全框架
- python爬虫