mysql-锁
文章目录
概念
计算机协调多个进程或线程并发访问某一资源的机制
防止多事务并发造成数据不统一,避免脏写、脏读、不可重复读、幻读等问题
脏写:事务A和事物B同时改一行数据,最后的更新覆盖了其他事务所做的更新
脏读:事务A读取到了事务B已经修改但尚未提交的数据
不可重复读:事务A内部的相同查询语句在不同时刻读出的结果不一致,不符合隔离性
幻读:事务A读取到了事务B提交的新增数据,不符合隔离性
隔离级别
// 查看当前数据库的事务隔离级别
show variables like 'tx_isolation';
// 设置事务隔离级别
set tx_isolation = 'REPEATABLE-READ';
Mysql默认隔离级别为可重复读

未提交读(READ UNCOMMITTED)
事务B可以读到事务A未提交的数据
提交读(READ COMMITTED)
事务B可以读到事务A提交的数据
可重复读(REPEATABLE READ)
事务B连接之后,读到的一直是连接开始的数据
可重复读的隔离级别下使用了MVCC(multi-version concurrency control)机制,select操作不会更新版本号,是快照读(历史版本);insert、update和delete会更新版本号,是当前读(当前版本)。
可串行化(SERIALIZABLE)
事务A操作未提交,事务B查询将一直处于等待状态
并发性很低,开发中很少会用到
锁分类
按性能
乐观锁(用版本对比来实现)
悲观锁
按照锁定机制
全局锁
作用范围:库(database)
实现层:SQL layer层
影响:整个库处于只读状态,所有更新操作都将阻塞
使用场景:全库逻辑备份(会影响业务运行,正常业务数据无法写入,无法同步,不推荐)
// 加锁
flush tables with read lock;
// 释放锁,或者断开事务连接,自动释放全局锁
unlock tables;
表锁
作用范围:表
实现层:SQL layer层
优点:开销小、加锁快,不会出现死锁
缺点:锁定粒度大,发生锁冲突的概率最高,并发度最低
场景:一般用在整表数据迁移
读S/写X锁——悲观锁
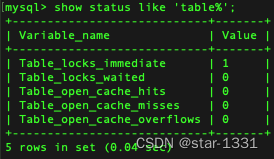
查看表锁状态变量
show status like 'table%';
- table_locks_immediate:产生表级锁定的次数;
- table_locks_waited:出现表级锁定争用而发生等待的次数
表锁两种表现形式:表共享读锁(Table Read Lock)、表独占写锁(Table Write Lock)
// 手动增加表锁
lock table tblname read(write);
// 查看表锁情况
show open tables;
// 删除表锁
unlock tables;
读锁影响:
1、自身和其他事务都能读
2、自身无法读取其他表,其他事务可以
3、自身写入或更新表会报错,其他事务将处于等待状态
写锁影响:
自身查询和写入都没问题,其他事务处于等待状态
元数据锁(meta data lock, MDL)
不需要显示使用,访问一个表的时候会自动加上,保证读写的正确性
增删改查操作加MDL读锁,表结构变更操作加MDL写锁
读锁之间不互斥
读写、写写之间互斥
意向锁(Intention Locks)(InnoDB)
mysql内部使用,不需要用户干预
意向锁和行锁可以共存
作用:为了全表更新数据时的性能提升,协调行锁与表锁的关系,判断表中有没有行锁
自增锁(AUTO-INC LOCKS)
涉及AUTO_INCREMENT列的事务性插入操作时产生
行锁
作用范围:某行 或者 行之间的间隙
实现层:存储引擎
InnoDB行锁:通过给索引上的索引项加锁来实现的,只有通过索引条件检索的数据才能使用,其他将使用表锁
优点:锁定粒度最小,发生锁冲突的概率最低,并发度最高
缺点:开销大、加锁慢、会出现死锁
// 查看行锁争夺情况
show status like 'innodb_row_lock%';
Innodb_row_lock_current_waits: 当前正在等待锁定的数量
Innodb_row_lock_time: 从系统启动到现在锁定总时间长度(等待总时长)
Innodb_row_lock_time_avg: 每次等待所花平均时间(等待平均时长)
Innodb_row_lock_time_max:从系统启动到现在等待最长的一次所花时间
Innodb_row_lock_waits:系统启动后到现在总共等待的次数(等待总次数)
按照锁定范围划分:
记录锁(Record Locks)
锁定索引中一条记录,锁住的是索引,而不是记录本身
// 记录共享锁
select * from tblname where id = 1 lock in share mode;
// 记录排他锁
select * from tblname where id = 1 for update;
间隙锁(Gap Locks)
锁住一个索引区间(开区间,不包括双端端点)
要么锁住索引记录中间的值,要么锁住第一个索引记录前面的值或者最后一个索引记录后面的值。
作用:防止幻读,保证索引间不会被插入数据
在可重复读隔离级别下才会生效
select * from tblname where id > 4 for update;
临键锁(Next-Key Locks)
索引记录上的记录锁和在索引记录之前的间隙锁的组合(间隙锁+记录锁)(左开右闭区间)
插入意向锁(Insert Intention Locks)
做insert操作时添加的对记录id的锁。
按功能划分:
共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。
select * from tblname where ... lock in share mode;
排他锁(X):允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享读锁和排他写锁。
select * from tblname where ... for update;
按照功能
共享锁Shared Locks(S锁)
加了S锁的记录,允许其他事务再加S锁,不能再加X锁
select ... lock in share mode
排他锁Exclusive Locks(X锁)
加了X锁的记录,不允许其他事务再加锁
select ... for update
死锁
两个或多个事务在同一资源上相互占用,并请求锁定对方占用的资源。锁定之后,双方都需要等待对方释放锁,同时又持有对方需要的锁,则陷入死循环。
产生死锁的情况
1、多个事务试图以不同的顺序锁定资源
2、多个事务同时锁定同一个资源
和存储引擎相关
set tx_isolation='repeatable-read';
Session_1执行:select * from account where id=1 for update;
Session_2执行:select * from account where id=2 for update;
Session_1执行:select * from account where id=2 for update;
Session_2执行:select * from account where id=1 for update;
解决死锁
1、检测到死锁的循环依赖,立即返回一个错误
2、当查询的时间达到锁等待超时的设定后放弃锁请求(不好)
3、将持有最少行级排他锁的事务进行回滚
锁优化建议
- 尽可能让所有数据检索都通过索引来完成,避免无索引行锁升级为表锁
- 合理设计索引,尽量缩小锁的范围
- 尽可能减少检索条件范围,避免间隙锁
- 尽量控制事务大小,减少锁定资源量和时间长度,涉及事务加锁的sql尽量放在事务最后执行
- 尽可能低级别事务隔离
mysqldump数据库备份
支持事务引擎(innodb)
使用–single-transaction参数,利用mvcc提供一致性视图
不会影响业务的正常运行
不支持事务引擎(MyISAM)——全局锁
使用–lock-all-tables参数
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- zookeeper的优化配置
- 自定义拖拽表单的优势表现在哪里?
- 深入了解Spring MVC工作流程
- web组态--新一代全流程低代码物联网平台
- 一向高调的万达,今年为何如此低调?2024最受欢迎的创业项目,2024新的创业机会
- Redis如何做内存优化?
- 【Linux】探索Linux进程优先级 | 环境变量 |本地变量 | 内建命令
- 计算三叉搜索树的高度 - 华为OD统一考试
- 1500千头养猪场污水处理设备技术方案
- javafx可视化java编程入门教程