Flink实战之运行架构
本文章:重点是分析清楚运行架构以及并行度与slot的分配
1、JobManager和TaskManager
Flink中的节点可以分为JobManager和TaskManager。
JobManager处理器也称为Master,用于协调分布式任务执行。他们用来调度task进行具体的任务。TaskManager处理器也称为Worker,用于实际执行任务。
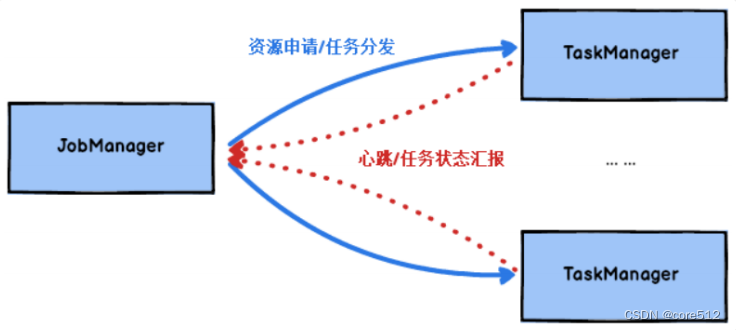
一个有效的Flink集群中可以包含多个JobManager组成高可用集群,也可以有多个TaskManager进行并行计算。他们可以直接在物理机上启动,也可以通过像Yarn这样的资源调度框架启动。
每一个处理器都是一个单独的JVM进程,也可以通过配置的方式管理他们占用的内存资源。在flink-conf.yaml配置文件中,可以通过jobmanager.memory.process.size属性配置jobmanager占用的内存大小,taskmanager.memory.process.size属性配置每个taskmanager占用的内存大小。这个内存大小包含了JVM占用的堆内存以及堆外的元数据区和堆外直接内存的大小。这些参数也可以在提交任务的时候进行干预。
而JobManager在接收到任务时,整体执行的流程会是这样。
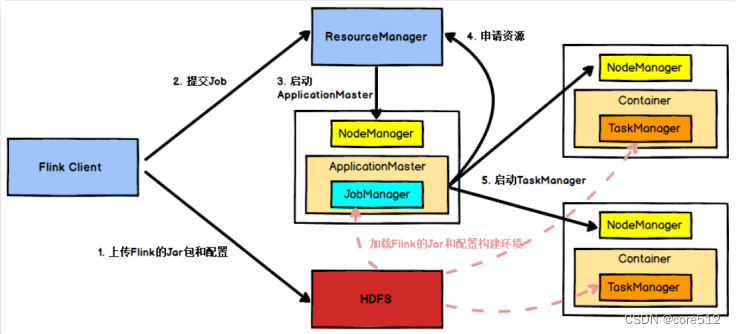
客户端会往JobManager提交任务,JobManager会往ResouceManager申请资源,当资源足够时,再将任务分配给集群中的TaskManager去执行。
只不过在Standalone模式下,这个ResourceManager是由Flink自己担任的。而在Yarn模式下,则是转为由Yarn来担任ResourceManager角色。
2、并发度与Slots
每一个TaskManager是一个独立的JVM进程,他可以在独立的线程上执行一个或多个任务task。为了控制一个taskManager能接收多少个task,TaskManager上就会划分出多个slot来进行控制。 每个slot表示的是TaskManager上拥有资源的一个固定大小的子集。flink-conf.yaml配置文件中的taskmanager.numberOfTaskSlots属性就配置了配个taskManager上有多少个
slot。默认值是1,所以我们之前搭建的集群,有3个taskManager,集群内总共就只有3个slot。这些slot之间的内存管理也就是数据是相互隔离的。而这些slot其实都是在同一个JVM进程中,所以这里的隔离并不涉及到CPU等其他资源的隔离。
Task Slot是一个静态的概念,代表的是TaskManager具有的并发执行能力。另外还有一个概念并行度parallelism就是一个动态的概念,表示的是运行程序时实际需要使用的并发能力。这个是可以在flink程序中进行控制的。如果集群提供的slot资源不够,那程序就无法正常执行下去,会表现为任务阻塞或者超时异常。
程序运行时的parallelism管理有三个地方可以配置,优先级最低的是在flinkconf.yaml文件中的parallelism.default这个属性,默认值是1。优先级较高的是在提交任务时可以指定任务整体的并行度要求。这个并行度可以在提交任务的管理页
面和命令行中添加。 优先级最高的是在程序中指定的并行度。在flink的应用程序中,几乎每一个分布式操作都可以定制单独的并行度。这到底是是怎么回事呢?那现在我们就开发一个简单的flink应用了解一下。
3、开发环境搭建
flink提供了java和scala两套客户端API,我们这里采用java进行演示。
首先创建一个maven工程,在pom.xml文件中,引入客户端的依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.12.5</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.12.5</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.12.5</version>
</dependency>
后面这个依赖中最后的2.12表示是对应的scala版本。
然后就可以开发一个简单的flink应用程序。
package com.roy.flink.streaming;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SerializationSchema;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.nio.charset.StandardCharsets;
public class SocketWordCount {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
final ParameterTool parameterTool = ParameterTool.fromArgs(args);
String host = parameterTool.get("host");
final int port = parameterTool.getInt("port");
final DataStreamSource<String> inputDataStream = environment.socketTextStream(host, port);
final DataStream<Tuple2<String, Integer>> wordcounts = inputDataStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
final String[] words = value.split(" ");
for (String word : words) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
})
.setParallelism(2)
.keyBy(value -> value.f0)
.sum(1)
.setParallelism(3);
wordcounts.print();
wordcounts.writeToSocket(host,port,new SerializationSchema<Tuple2<String, Integer>>(){
@Override
public byte[] serialize(Tuple2<String, Integer> element) {
return (element.f0+"-"+element.f1).getBytes(StandardCharsets.UTF_8);
}
});
environment.execute("stream word count");
}
}
这个程序的作用就是连接一个socket服务端,读取socketStream文本流,然后进行最为经典的WordCount操作。
首先,执行这个测试程序需要有一个socket服务端。 我们可以在找1台Linux机器centos7使用nc指令模拟一个。 nc -lk 7777 在本地7777端口建立一个socket服务端。
然后,在本地的IDEA运行配置页面,指令要连接的host和port。
配置完成后,就可以在本地直接运行这个示例了。这也就是Flink所谓的LOCAL模式。
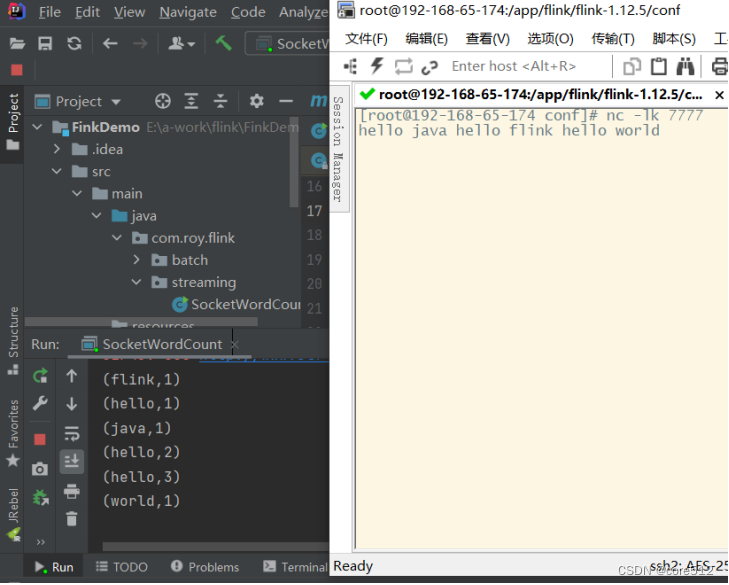
这个执行结果就是最终的wordcount结果。 但是,这里面有个有趣的现象。对hello的次数统计,是从1,一步一步统计到3的,而不是一次性统计到3。其实这也体现了流失计算的特点。这些词其实是一个一个统计的。
然后要注意一下我们代码中进行了多次setParallelism操作。在这个演示过程中,暂时没有体现出什么作用。在后续的演示中会有用。
4、提交到集群执行
这种本地执行的方式显然不具备生产使用的要求。我们可以使用maven进行编译,将这个代码编译成一个jar包,FlinkDemo-1.0.jar。
参考,我的这篇文章打包jar:https://core815.blog.csdn.net/article/details/135622599?spm=1001.2014.3001.5502
参考,我的这篇文章搭建Flink集群:https://core815.blog.csdn.net/article/details/135555285?spm=1001.2014.3001.5502
访问控制台,打开 Submit New Job页面,选择 +Add New 按钮,提交jar包。

单独提供一个jar包还并不足以启动任务,因为启动任务还需要指定任务的入口。选择这个FlinkDemo-1.0.jar,继续配置一个任务。
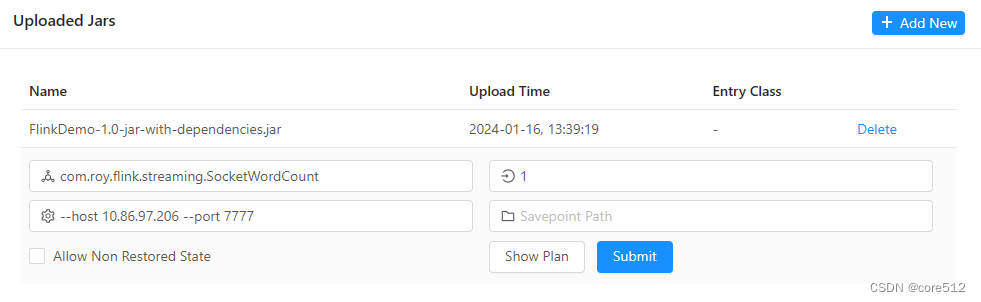
在这里注意下,提交任务时可以指定这个应用整体的Parallism 并行度。
点击提交,就可以开启一个任务。在running job页面就可以看到正在执行的任务stream word count。选择这个任务,就能看到任务的执行情况。
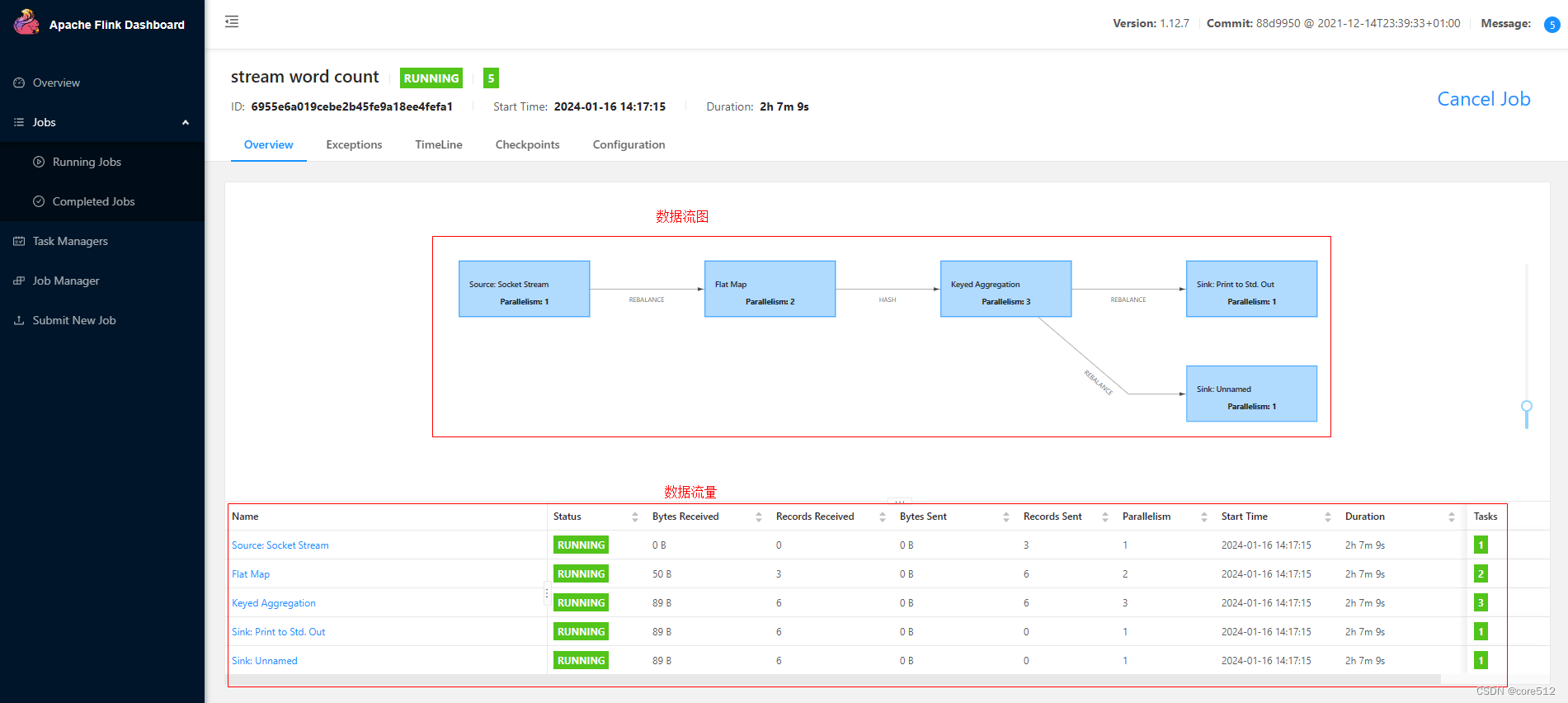
这个数据流图展示了整个这个应用的具体执行的步骤。这些步骤整体就构成了数据流图。下面的数据流量会统计每个步骤经过的数据流量。在centos7机器上的nc服务中敲入字符,这个数据流量与记录数就会不断增加。
最后应用中通过print打印出来的消息会输入到应用的标准输出控制台。控制台的内容可以在TaskManagers菜单中查看。
5、并行度分析
这里我们重点分析每个蓝色方块下面的Parallelism参数。这里列出了每个步骤所占用的slot数量。而这里统计出来的slot数量就是按照之前所说的优先级确定的。整体优先级是这样。
程序中指定 > 提交任务时指定 > flink-conf.yaml中指定。
然后,我们回到Overview页面,查看下整体的slot情况。
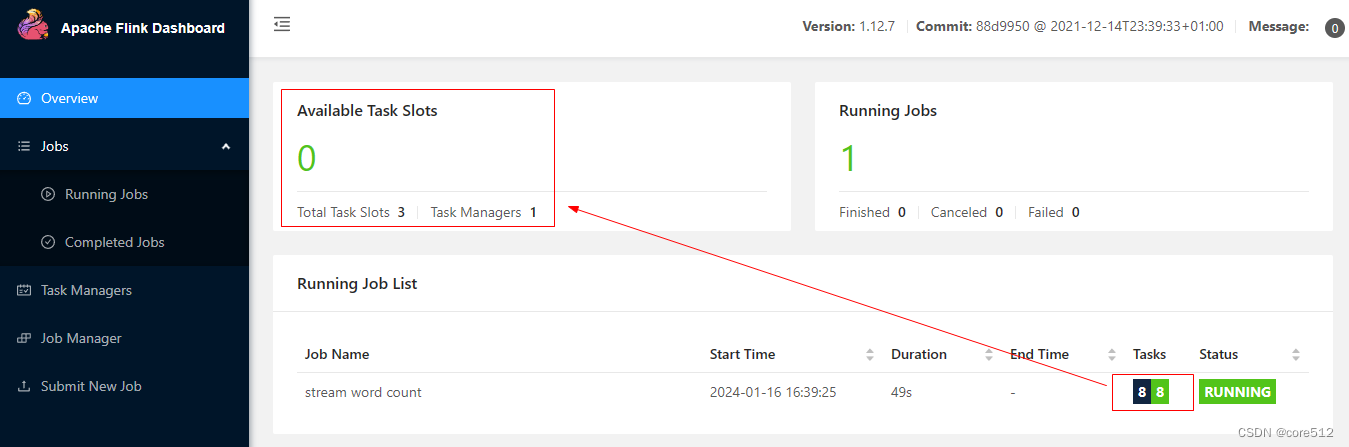
接下来可以看到,我们这个job总共需要8个slot,但是集群中只有3个slot,程序也正常执行起来了。这也体现了slot复用的效果。也就是说slot可以在不同的执行步骤中处理不同的任务。只要集群资源能够支撑应用最大的并行度要求,整个应用就可以运行起来。实际上,Flink对于这个数据流图还会有一些自己的优化,例如某些相邻的操作,他们的并行度相同,任务也不是很复杂时,flink会将这些相邻的步骤进行合并。
这些slot在同一个任务内部是可以不断复用的,但是在不同的任务之间,是不能共用的。所以,这时可以看到,集群中仅有的3个slot已经全部被这个stream wordcount应用给占满了,如果需要再启动应用,就无法执行了。这时jobmanager会不断的尝试重新申请slot,如果集群中有空出来的slot,那就可以分配给应用。如果一直申请不下来,jobmanager会不断重试,默认每重试10次就会休息一点时间,过后再继续申请。如果在attached模式下,在客户端可以很清晰的看到这个过程。
6、Flink整体运行流程
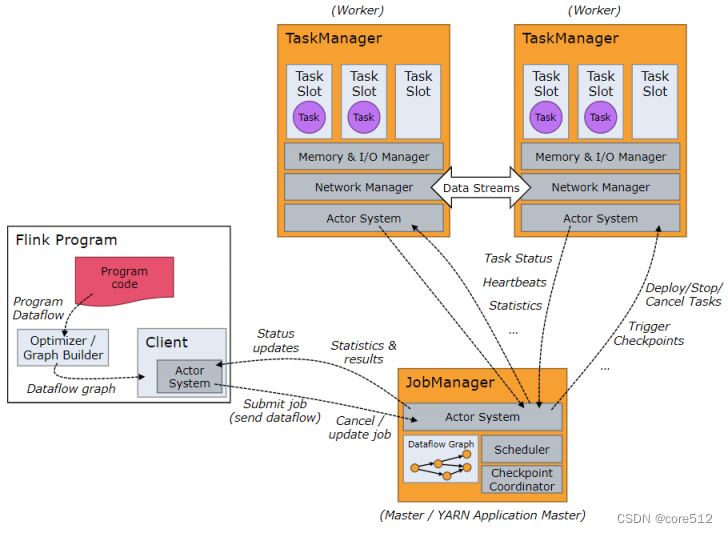
然后我们再回头来看Flink官方提供的集群结构图就比较清晰了。
客户端
对于Flink,可以通过执行一个Java/Scala程序,或者通过./bin/flink run … 指令启动一个客户端。客户端将把sataflow提交给JobManager。客户端的主要作用其实就是构建好一个Dataflow graph或者也称为JobGraph,然后提交给客户端。而这个JobGraph如果在客户端本地构建,这就是Per-job模式,如果是提交到JobManager由Flink集群来构建,这就是Application模式。然后将提交完成后,客户端可以选择立即结束,这就是detached模式。也可以选择继续执行,来不断跟踪JobManager反馈的任务执行情况,这就是默认的attached模式。
JobManager
JobManager会首先接收到客户端提交的应用程序。这个应用程序整体会包含几个部分:作业图JobGraph,数据流图logic dataflow graph以及打包了所有类库以及资源的jar包。这些资源都将分发给所有的TaskManager去真正执行任务。
JobGraph相当于是一个设计图,之前Yarn的Per-job模式,往集群提交的就是这个JobGraph。JobManger会把JobGraph转换成一个物理层面的数据流图,这个图被叫做执行图 ExecutionGraph,这其中包含了所有可以并发执行的任务,相当于是一个执行计划。接下来JobGraph会向资源管理器 例如Yarn的ResourceManager请求执行任务必要的资源,这些资源会表现为TaskManager上的slot插槽。一旦获得了足够多的资源,就会将执行图分发到真正运行任务的TaskManager上。而在运
行过程中,JobManager还会负责所有需要中央协调的操作,例如反馈任务执行结果,协调检查点备份,协调故障恢复等。
JobManager整体上由三个功能模块组成:
-
ResourceManager
ResourceManager在Flink集群中负责申请、提供和注销集群资源,并且管理task slots。Flink中提供了非常多的ResourceManager实现,比如Yarn,Mesos,K8s和standalone模式。在standalone模式下,ResourceManager只负责在TaskManager之间协调slot的分配,而TaskManager的启动只能由TaskManager自己管理。 -
Dispatcher
Dispatcher模块提供了一系列的REST接口来提交任务,Flink的控制台也是由这个模块来提供。并且对于每一个执行的任务,Dispatcher会启动一个新的JobMaster,来对任务进行协调。 -
JobMaster
一个JobMaster负责管理一个单独的JobGraph。Flink集群中,同一时间可以运行多个任务,每个任务都由一个对应的JobMaster来管理。一个集群中最少有一个JobManager。而在高可用部署时,也可以有多个JobManager。这些JobManager会选举出一个作为Leader。而其他的节点就出于StandBy备用的状态。
TaskManager
TaskManager也成为Worker。每个TaskManager上可以有一个或多个Slot。这些Slot就是程序运行的最小单元。 在flink.conf.yaml文件中通过taskmanager.numberOfTaskSlots属性进行配置。
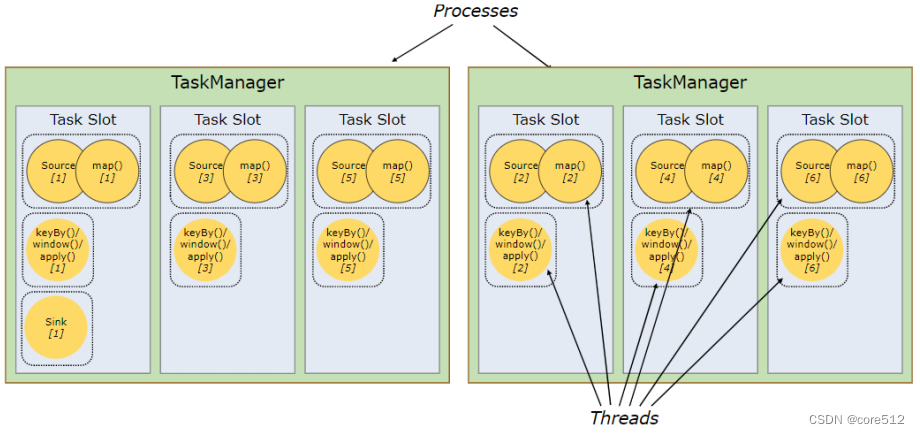
每一个TaskManager就是一个独立的JVM进程,而每个Slot就会以这个进程中的一个线程执行。这些Slot在同一个任务中是共享的,一个Slot就足以贯穿应用的整个处理流程。Flink集群只需要关注一个任务内的最大并行数,提供足够的slot即可,
而不用关注整个任务需要多少Slot。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- ABAP HR根据组织单元查询所有组织内人员
- PIG框架学习3——Redisson 实现业务接口幂等
- Java电子招投标采购系统源码-适合于招标代理、政府采购、企业采购、等业务的企业
- HLS + ffmpeg 实现动态码流视频服务
- QT day6
- Jmeter基础和概念
- SpringSecurity深度学习
- HP C7000 刀片服务器前/后视图
- layui 监听checkbox,checkbox全选,反选,日期使用,select赋值,图片预览上传
- CDGA,CDGP,CDMP有啥区别?考哪个好?