关联规则分析(Apriori算法
1.关联规则:
什么是关联规则?
可以归纳为X->Y,就是X发生的情况下很可能会发生Y
比如:啤酒和尿布,就是 尿布->啤酒 这么一个强关联规则,含义是:如果顾客购买尿布,那么他很有可能买啤酒。
啤酒和尿布的关联规则故事
沃尔玛公司数据仓库里集中了其各门店的详细原始交易数据。在这些原始交易数据的基础上,沃尔玛公司利用数据挖掘方法对这些数据进行分析和挖掘个意外的发现是:跟尿布一起购买最多的商品竟是啤酒。经过大量实际调查和分析,揭示了一个隐藏在“尿布与啤酒”背后的消费模式,一年轻父亲下班后经常要到超市去买婴儿尿布,而他们中有 30%~40%的人同时也为自己买一些啤酒。产生这一现象的原因是:太太们常叮嘱她们的文夫下班后为小孩买尿布,而丈夫们在买尿布后又随手带回了他们喜欢的啤酒。
2.关联规则算法:
关联规则算法有哪些呢?
有Apriori、FP-growth和EClat等
本章主要讲解Apriori算法
3.Apriori算法原理:
Apriori算法原理是什么?
关联规则挖掘的基本思路:
1)先找出频繁项集
2)然后将他们处理为关联规则
频繁项集:项集是一个类似于{A, B, C}的集合,频繁项集是支持度(support)大于最小支持度阈值的项集。
稍等一下,我们先得知道Apriori的两个假设
Apriori算法包含两条重要的先验性质。
- 如果一个集合是频繁项集,则它的所有子集也都是频繁项集;例如:集合 {A, C} 是频繁项集,则它的子集 {A}, {C} 都是频繁项集。
- 如果一个集合不是频繁项集,则它的所有超集都不是频繁项集;例如:集合 {A, B} 不是频繁项集,则它的子集 {A, B, C},{A, B, D}都不是频繁项集。
好,我们回归到算法的流程
3.1 先找出频繁项集
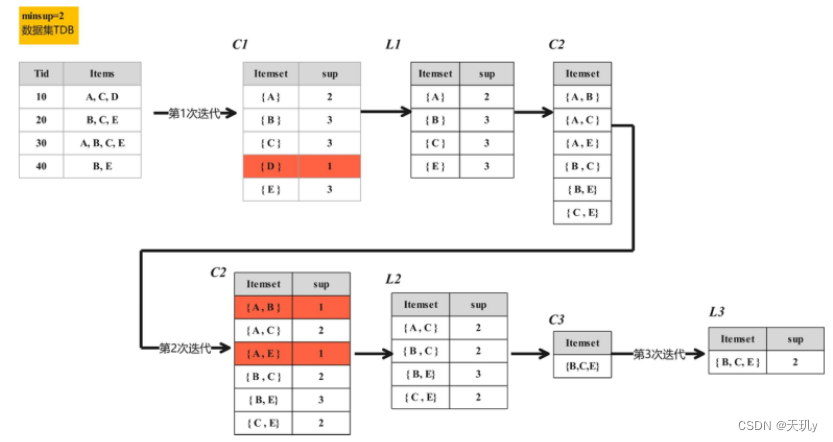
参考上图
- 第一次迭代,对整个数据集进行遍历,得到“1-项集”的候选项集合及出现频次。即{A}的出现频次为2,{B}的出现频次为3,{C}的出现频次为3,{D}的出现频次为1,{E}的出现频次为3。
- 剔除小于最小支持度的项集,得到频繁1-项集。这里的最小支持度为2,表示最小的出现频次为 2,因此{D}不符合最小支持度,筛选得到的频繁1-项集为{A}, {B}, {C}, {E}
- 第二次迭代:将频繁1-项集自连接得到“2-项集”的候选项集合(当然,自连接的集合都是属于已存在的集合),即得到{A、B},{A,C},{A,E},{B,C},{B,E},{C,E}接着剔除小于最小支持度2 的项集,得到的频繁 2-项集
- 直到频繁项集为空,即“4-项集”为空,便得到了所有的频繁项集
总结就是自连接和剔除迭代操作,直到下一次迭代(下一维度)中自连接不出来
3.2 是否能被设置为关联规则
将频繁项集Z划分为非空子集X和Y,其中Y=Z-X,接着计算规则X->Y是否满足最小置信度 (Confidenee),若不满足则删去这项规则,迭代得到最终的关联规则。例如对于频繁项集{B,C,E},它的非空子集有{B},{C},{E},{B},{C},{B,E},{C,E},关联规则{B}->{C, E}的置信度为sup({B,C,E})/sup({B}) = 2/3,若设定最小置信度为50%,则该项关联规则满足最小置信度,故保留。
总结就是将频繁项集的所有非空子集及其对应的补集建立关联规则,计算置信度(条件概率),与最小置信度比较,以确定是否保留
3.Apriori算法原理:
小结:
关注我给大家分享更多有趣的知识,以下是个人公众号,提供 ||代码兼职|| ||代码问题求解||
由于本号流量还不足以发表推广,搜我的公众号即可:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 解决apt下载速度慢问题
- Statistics with Python 统计学理论
- Docker(三)使用 Docker 镜像
- 全国人口普查管理系统(JSP+java+springmvc+mysql+MyBatis)
- nacos和gateway部署实践踩的坑
- windows电脑遇到“你的设备遇到问题,需要重启”应该如何解决
- 【ES】es介绍
- 理解 Proxy 和 Object.defineProperty:提升你的 JavaScript 技能(上)
- ‘千问初体验:启程你的首度探索之旅‘,问出你的第一个问题
- 基于Java SSM框架实现学生成绩管理系统项目【项目源码+论文说明】计算机毕业设计