物流项目话术(1.5w字精选)
物流项目的分类

技术架构图(面试时面试官会要求你画出技术架构图)

功能结构图

业务功能流程

流程说明:
-
用户在【用户端】下单后,生成订单
-
系统会根据订单生成【取件任务】,快递员上门取件后成功后生成【运单】
-
用户对订单进行支付,会产生【交易单】
-
快件开始运输,会经历起始营业部、分拣中心、转运中心、分拣中心、终点营业部之间的转运运输,在此期间会有多个【运输任务】
-
到达终点网点后,系统会生成【派件任务】,快递员进行派件作业
-
最后,用户将进行签收或拒收操作
?微服务调度关系

项目搭建提问
?在公司中使用几台服务器?
服务器这块我不是很清楚,因为我们是个大公司,在公司中我们的运维已经搭好了cicd的环境,我们后端人员主要使用jenkins发布写好的微服务模块。
权限认证步骤?
流程图:

数据校验
数据校验使用@Validated。(可以使用在方法,方法参数,类 上)
DTO类的数据校验?

?Controller层中的方法

为了使得DTO类中的校验注解生效,我们需要在controller中添加@Validated。
但是即使在contrller中设置了对应的注解,校验还是不会生效,为了使得注解生效,这里在方法参数位置添加@Validated注解。

?在该项目中为了方便开发,直接使用aop进行环绕通知,自动设置@Validated。
import cn.hutool.core.collection.CollUtil;
import cn.hutool.core.util.ObjectUtil;
import cn.hutool.json.JSONUtil;
import com.sl.transport.common.exception.SLException;
import com.sl.transport.common.util.AspectUtil;
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.springframework.context.annotation.EnableAspectJAutoProxy;
import org.springframework.http.HttpStatus;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import javax.validation.ConstraintViolation;
import javax.validation.Validator;
import java.util.Set;
import java.util.stream.Collectors;
/**
* 请求参数校验切面,统一对Controller中@RequestBody映射的对象进行校验,在Controller方法中无需单独处理
* 通过aop保证对应参数的中的校验注解可以生效
* 该切面的作用就是自动在方法参数上添加@validated
*/
@Aspect //思想aop
@Slf4j
@EnableAspectJAutoProxy
@Component
public class ValidatedAspect {
@Resource
private Validator validator;
@Around("execution(* com.sl..controller.*Controller.*(..))") //设置前面切面为:每个Controller层中对应的每个方法,这里使用环绕通知
public Object around(ProceedingJoinPoint proceedingJoinPoint) throws Throwable {
// 获取@RequestBody映射的对象
Object body = AspectUtil.getBody(proceedingJoinPoint); //这里就是获取Controller方法中对应的参数
// 不为空的body进行拦截校验
//方法中的参数不为空就说明我们需要进行数据校验
if (!ObjectUtil.isEmpty(body)) {
// 进行校验
Set<ConstraintViolation<Object>> validateResult = validator.validate(body); //就等于在对应的方法参数上添加@Validated注解
if (CollUtil.isNotEmpty(validateResult)) {
//没有通过校验,抛出异常,由统一异常处理机制进行处理,响应400
String info = JSONUtil.toJsonStr(validateResult.stream()
.map(ConstraintViolation::getMessage).collect(Collectors.toList()));
throw new SLException(info, HttpStatus.BAD_REQUEST.value());
}
}
//校验通过,执行原方法
return proceedingJoinPoint.proceed(proceedingJoinPoint.getArgs());
}
}
全局异常处理
?问:你们是怎么处理异常的呢?
答: 在我们日常开发中,我,我们会创建一个全局的异常拦截器,通过使用@RestControllerAdvice , 创建一个全局异常处理类
通过@ExceptionHandler(对应的异常类)创建一个个处理对应异常类型的方法,最终返回友好的信息给前端。
微服务实现共享配置
对应的配置为下:
#设置共享配置所在的名字空间
#shared-config的值是一个数组
每个共享配配置需要设置:dataId, 分组
spring:
cloud:
nacos:
config:
namespace: ecae68ba-7b43-4473-a980-4ddeb6157bdc
shared-configs: #共享配置
- data-id: shared-spring-seata.yml
group: SHARED_GROUP
refresh: false
- data-id: shared-spring-mysql.yml
group: SHARED_GROUP
refresh: false
- data-id: shared-spring-mybatis-plus.yml
group: SHARED_GROUP
refresh: false双token身份认证
问:单token会存在什么安全问题?有什么方法可以提高安全性?其实现步骤是什么?
单token存在的问题:
1.设置token有效时间:设置有效时长短了会导致用户需要频繁的登录,设置有效时长过长,会被非法人员获取token,通过该token干坏事。
2.没有设置token的有效时间:如果没有设置token的有效时间,token永远是有效的,在token有异常时,也无法使其失效。(token的无状态性)
解决方案: 使用双token实现三检验。
双token实现三检验的步骤:
1.解决token有效时间的方案为:设置access_token(短token),refresh_token(长token),access_token做用户认证,而refresh_token会在access_token失效的时候,用于获取新的access_token和refresh_token。(当然在通过这个过程也会判断refresh_tolen的有效性)
2.解决token的无状态性: 设置refreish的有效性和只能使用一次。(这些操作在redis中可以完成)
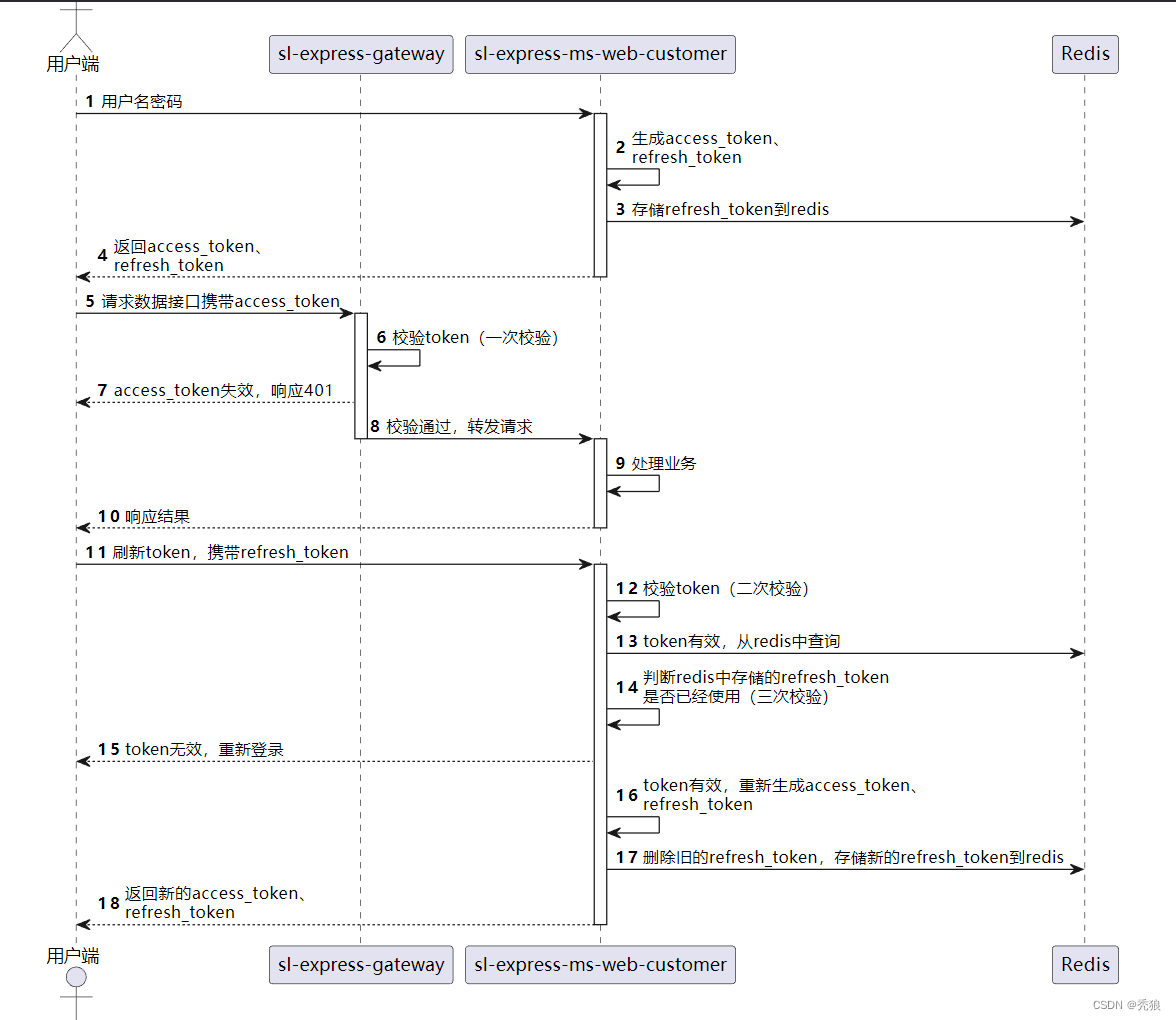
三次验证的流程图:
 ?具体流程为下:
?具体流程为下:
1.在用户第一次登录时会生成access_token和refresh_token,并将refresh_token存入redis中,设置refresh_token的有效时长,这里可以使用access_refresh当key,剩余的使用次数当value。(value默认是1)
如果次数用户有access_token或refresh_token
2.判断是否存在access_token, 存在时判断token的有效性,如果是无效的则返回错误信息。如果不存在则进入第二次验证(第一次验证)
3.判断是否存在refresh_token,通过redis判断token的有效性,如果有效进入第三次验证,如果无效则直接返回登录界面。(第二次验证)
4.判断refresh_token的使用次数通过redis,如果是第一次使用则通过该token获取新的access_token和refresh_token删除旧的refresh_token,如果旧的refresh_token不是第一次使用则此时refresh_tolen在redis中是查不到的,则返回登录界面。(第三次验证)
微信小程序登录流程
 ?登录会取code,通过调用微信接口传入code,appid,appsecret,会获取openId和session_key。
?登录会取code,通过调用微信接口传入code,appid,appsecret,会获取openId和session_key。
自定义登录态,该登录态要关联openId和session_id,获取通过该自定义态获取openId和session_key。
?最终项目的实现流程为下:
具体流程
1.通过微信小程序登录,会传入微信临时凭证,通过调用微信的查询接口即可查询出openid,在数据库中查询出对应的用户,如果该用户存在且传入的手机号(通过微信查询接口查询)不一样则就修改对应的手机号。如果用户不存在则就做插入操作(包括openId,手机号)。
2.将对应用户的id,通过jwt生成长短token,短token为15分钟,长token为2小时,主要是通过公钥和密钥生成token(在nacos的配置中心中配置),并且会将长token加密(MD5)后作为key,value为1(只能使用一次)存储到redis中(需要设置ttl,2个小时)。
用户登录,生成长短token。
3.刷新token方法,首先判断长token在redis中是否存在,通过jwt解析key对应的用户id,删除对应的键值对。生成新的长短token。(会在网关的配置中配置公钥)
第一次校验:判断短token有效性。(通过公钥解析)
第二次校验:判断长token (通过公钥解析)
第三次校验:判断长token在redis中是否存在。
项目不同用户权限隔离方案
我们物流项目中主要是基于RDAB模型实现的,我们做了一个权限的模块。数据库中对应了5张表。分别为:用户信息表,角色表,权限表,用户和角色关联表(多对多的关系),角色和权限关联表(多对多关系)。通过结合springSecurity使用链式编程做权限的判断。
gateway配置规则
主要就是保证访问对应的微服务,通过设置对应的匹配路径,路由到对应的微服务。在此过程中达到负载均衡的效果。然后再gateway还会配置对应的jwt的公钥,我们会去解析token。
支付模块总结?
问:支付方式你们是怎么设计的呢?
答:我们创建另一个表,专门用于存储对应的支付方式和支付的配置信息和商户的id。

在这个表中包含: 支付方式标签和名字,对应的支付宝或微信配置(如:app_id,公钥,密钥)
等等,当我们需要使用对应支付方式的配置信息时,通过名字的条件查询出对应的配置信息。
扫码支付的流程
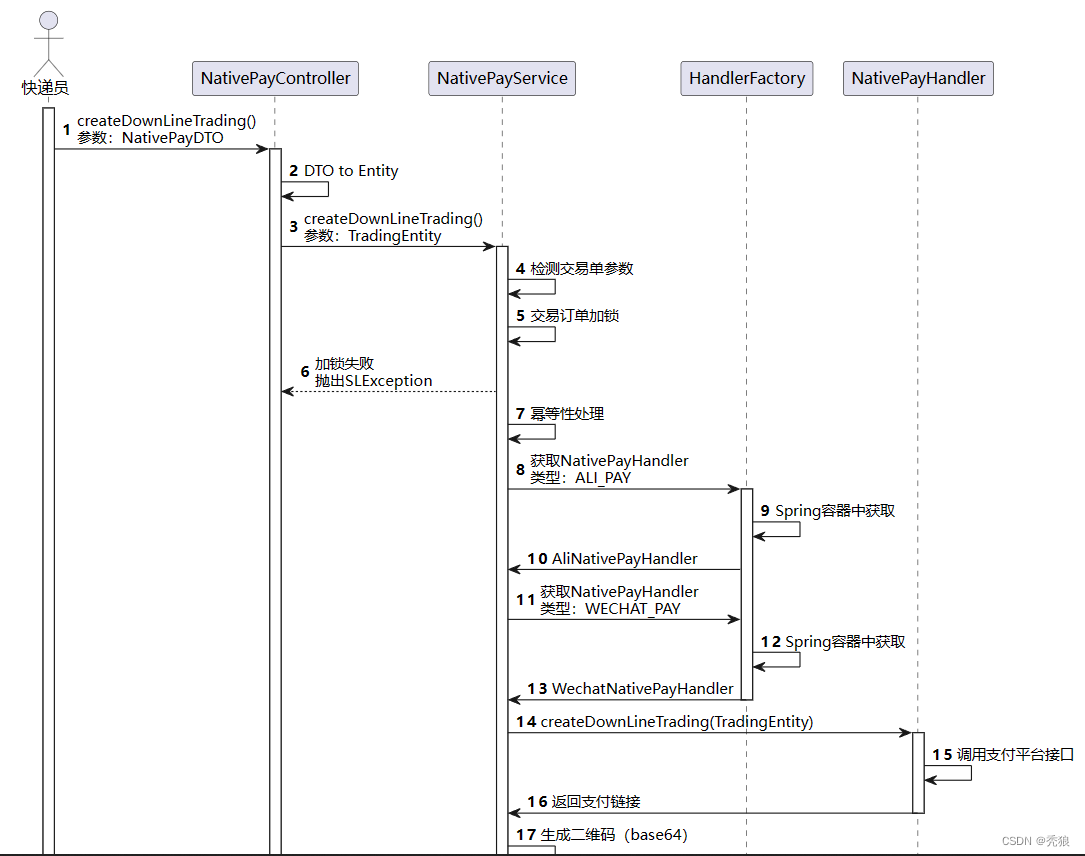

扫码支付模块?
问:在实现扫码支付的业务中我们需要考虑什么问题呢??
答:前端会传入业务订单的Id和对应的金额,?在业务中创建交易单,我们需要判断以下内容:
1.判断交易单中数据的有效性。
2.为了保证交易单状态的准确性,我们需要加分布式锁,防止其他业务修改当前交易单的状态,保证交易单状态的准确性。(使用redission)
3.判断幂等性,保证当前交易仅存在一次,防止用户进行多次支付。
4.使用hutool工具类将链接生成二维码。
问:拿你们在该业务中遇到说明难点,你们是怎么解决的?
答:为了耦合性,我们需要实现动态获取支付配置和操作类。
我们的解决方法就是使用: 自定义注解 + ioc + 反射 + 工厂模式。
1.创建自定义注解,该注解类中就一个标签属性,用于设置支付类型的标签。

2.创建一个Handler接口,各种支付方式的操作类都会实现该接口,并标记对应自定义注解,在注解中填写对应的支付方式标签,在该操作类中就是各种操作(包括:创建支付二维码,查询订单信息,退款订单 等等)

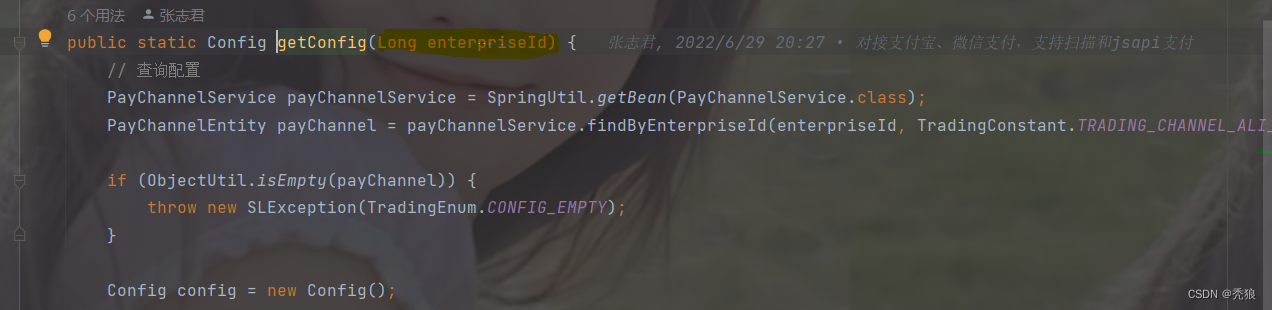
问:那怎么获取支付的配置信息呢?
答:前端会出来商户Id(商户就是收钱的人),因为该模块可以单独抽取出来,供其他项目使用,所以通过商户Id从数据库中查询对应的支付方式的配置信息。
3.创建应该工厂类,在该类中创建get方法,方法中需要传入支付标签和类的反射,通过hutool国家类中BeanUtil获取对应类.class的所有实例(这里就是handler.class),我们会获取到所有的支付方式实例,判断实例中自定义注解上的标签属性和传入的支付标签是否相同,相同最终就直接返回,不同就循环查找,最终没找到就返回null。
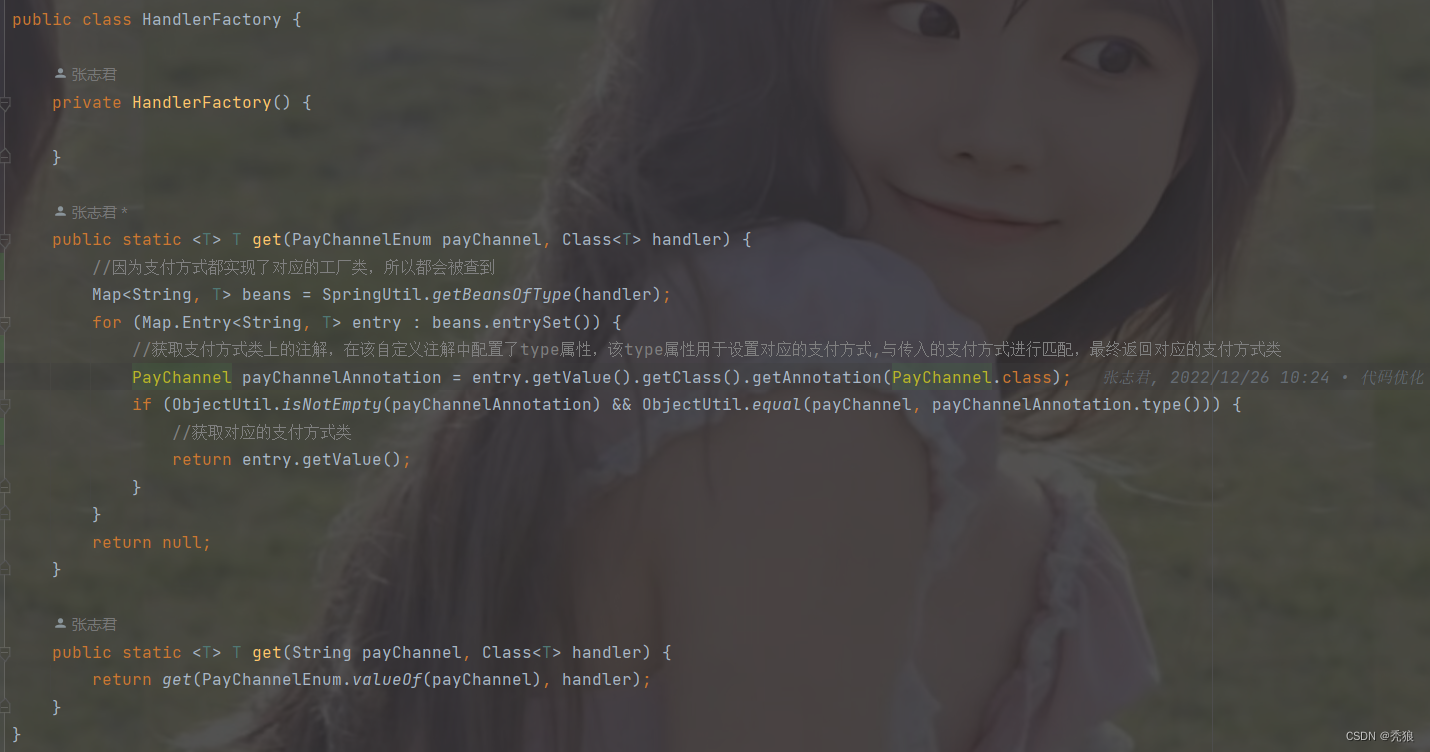
最终实现动态获取到支付和配置类。
问:你觉得获取动态获取配置这个过程很耗时该怎么解决呢?
答:直接在获取配置这个过程加个缓存即可,我们一般直接使用springCache。
问:刚刚你提到了会在该业务过程中添加分布式锁,可以说说是怎么实现的吗?
答:我们主要使用的是redis的分布式锁,使用其中的hash结构,使用业务订单+交易单作为大Key(一个交易单可能会被不同业务同时操作,所以也要作为大Key的一部分),使用线程Id作为小Key,当然使用线程Id还是不够保险,我们还会在其后添加UUID,value就是记录锁的次数,在业务中锁几次就要解锁几次。
问:那在幂等性中你们有考虑些什么问题呢?
答:
情况1:交易单不存在,直接生成交易单。
情况2:交易单存在,订单状态为免单或已结算,抛出异常。
情况3:交易单存在,订单状态为付款中,通过传入的支付标签和数据库中的支付标签相同,就返回错误信息,防止多次支付,如果支付标签不同,说明用户更改了支付方式,创建一个新的交易单号(交易单号用于查询订单),后续就会做新增操作。
情况四:交易单存在,订单状态为取消订单或挂账,创建一个新的交易单号,后续就会做新增操作。
订单查询模块
扫码模块中我们只能保证付款链接的生成,无法确定用户是否进行了支付,所以需要编写订单查询模块,查询的订单的状态。
在该模块中本质还是通过调用支付宝或前台支付方式的接口,通过传入订单号,查询状态,如果接口返回的是成功状态就将订单信息修改为已结算,如果如果返回的是失败则抛出异常。(在此过程中也会使用 动态获取支付配置和操作类,参数校验,加分布式锁,无需考虑幂等性)
退款模块(非重点,面试有问再答)
通过参数校验,加锁,判断幂等性(防止多次退款),动态获取支付配置和操作类,使用对应的退款接口,传入退款金额和订单号,实现退款服务。
同步支付状态模块
在生成支付的二维码后,我们不能保证发送一次查询订单就可以查询到对应的订单状态(因为在次过程中可能会出现查询失败的情况),所以我们需要做一个定时任务来查询订单状态。
通过做定时任务可以使用:异步通知或主动定时查询。
异步通知:我们需要在支付宝支付或其他的配置中设置好异步通知地址(地址不能直接暴露,需要走网关),当我们的支付请求成功后会调用该异步通知地址,在异步请求中会判断支付状态,并进行验签,最终修改交易单的状态或抛出异常, 通过mq发送消息,在订单模块中会会去消费该消息,最终修改订单的状态。?
day03下(P21)面试题?
问:?如果寄件人选择的是到付,你们又是怎么处理的呢?
答: 如果寄件人选择到付的话,那么只会生成运单的信息,并不会立刻调用支付服务生成交易单,并将运单设置为到付类型,在快递员派件的时候,按照业务的流程,再调用支付中台(我们将支付模块做成了支付中台,可以单独的抽取出来的),生成交易单,生成交易单后,收件人进行扫码支付。
运费微服务总结
整体流程

在我们会通过地点表查询起点和终点所属的运费模类型。
该模板分为: 同城,省内,经济区互寄,省外。
流程:
1.查询运费模板,判断其为:同城,省内,经济区互寄,跨省,模板对应不同的续重价格,这些续重价格可以进行修改,在后续变更可以直接修改。
2.计算物品的重量,将体积通对应的公式也就是体积除以轻抛系数,计算出对应的重量,和原来的重量进行比较去更大的重量值。
?3.计算运费,首重价格是固定的不同的是续重的价格,在最终为了方便计算,如果重量小于1kg就将重量设置为1kg,如果重量大于1小于10就保留一位小数并四舍五入,如果重量大于10小于100就判断小数部分是否大于0.5,如果小于就取0.5,如果大于就取1,大于100kg的话就不保留小数部分并进行四舍五入,最终计算运费就是:首重价格 + (重量 - 1) * 模板的价格。
最终计算出价格。
问: 你们的运费是怎么计算的?体积和重量怎么计算,到底以哪个为准?
答:?查询运费模板,判断其为:同城,省内,经济区互寄,跨省,模板对应不同的续重价格,体积通过公式 体积除以轻抛系数算出重量和原来的重量进行对比,以更重的重量为准。
问:?详细聊聊你们的运费模板是做什么的?
答:?判断其为:同城,省内,经济区互寄,跨省,模板对应不同的续重价格,通过模板计算出对应的价格。
问: 有没有针对运费计算做什么优化?
答: 在计算重量时结合体积取计算,通过对应的公式(体积除以轻抛系数)计算出重量,取更大的重量,在重量的四舍五入上我们做了优化,如果重量小于1kg就将重量设置为1kg,如果重量大于1小于10就保留一位小数并四舍五入,如果重量大于10小于100就判断小数部分是否大于0.5,如果小于就取0.5,如果大于就取1,大于100kg的话就不保留小数部分并进行四舍五入。
?路线规划总结
问:你们物流项目中的路线规划是怎么做的?
答:
在开始时我们开始想使用关系型数据库mysql,但是在获最短路径时需要一层一层的判断,性能十分的低下,所以我们决定使用neo4j(节点,关系,标签,属性),该非关系型数据库的特点就是能使得数据以图的形式进行存储和查询,非常符合我们的物流项目,其中节点就作为对应的站点,关系就作为路径。
我们将站点设置了不同的类型,这里包括 一级转运中心,二级转运中心,营业部。
通过SDN(Spring Data Neo4j)自定义构造查询最短路径的方法(在Cql中使用shoetedPath函数进行计算),我们接入了高德地图的接口(这个是公司自己封装的一个接口),并进行了二次封装,通过经纬度计算出距离,查询成本,通过公式计算出路线的最终运费。
问:? 如何确定路线的成本和距离?成本计算规则是什么?该成本会计算到公司利润核算中吗?
答:在站点间的关系中,我我们分为: 干线,?支线,接驳路线,分别对应一级转运中心向一级转运中心(双向的), 二级转运中心向一级转运中心(双向),营业点向二级转运中心。这三个线路对应的成本是不同的,通过改变线路的成本从而该改变利润。但其实在公司财务会有更加严谨的计算规则,分配怎么样的车,怎么样的司机,涉及的分解员和快递员等等会更复杂,这个我们不是我们的负责模块,由专门的财务系统负责。
问: 对于路线的往返你们是怎么设计的?为什么成对创建的?
答:
1.在为两个站点添加路线时,我们会生成往返的两条路线。
2我们的设计就是在每两个站点之间会有专门的司机进行配送,该司机就负责这条线路的来回。并且在物流常常存在往返的操作。
问: 路线支持修改起点或终点机构吗?请说明理由。
答:路线是不支持修改的,因为要该起点和终点是没有意义的,这样会导致路线完全发生改变,这还不如直接删除掉,新增新的路线。
智能调度总结

问: 能说说智能调度的核心业务逻辑吗?
答: 在用户下单调度中心会派快递员进行揽收,在揽收之后,会进行订单转运单,如果起始和结束节点相同时就发送派送消息和订单状态修改消息(这里我们使用rabbitMQ)派送微服务和订单服务会监听并完成对应的操作,如果起始和结束网点不一样的话就会进行路线规划,发送调度消息,调度相同监听到消息后,会将当前网点和下一网点信息相同的运单合并在一起,这里主要使用(redis中的list数据结构)作为待分配队列,通过定时任务查询对应的(起始点和终点)可用车辆,通过运力计算去消费待分配队列中的运单,并将这些运单调度状态改为已调度,司机出库,开始运输任务,更新运单的状态,并且更新车辆的状态。在运单送到后,司机就会进行入库,设置运单的下一个节点和其他信息,将运单设置为待调度,会向调度中心发送调度消息,司机端就会结束运输任务,做回车登记,更新车辆所在的新结构,将车辆设置为可用车辆。如果在起始点和终点相同会发送派送任务消息,调度中心会调度快递员微服务,创建派送信息,计算快递员的负载。也就是快递的总重量和体积,分配快递员,快递员派送快递,如果签收后则业务结束,如果为拒收,则需要将运单的起始点和终点进行调换,重新规划路线,并对路线进行拼接,这样用户才能准确的看到快递的位置,并发送调度任务消息,将快递进行送回。
智能调度之调度任务
问:你们的运单是怎么生成的呢?
答:我们的运单公式为 字母加13数字,而UUID不符合我们的要求,雪花算法则依赖时间戳,通过机器出问题了,可能会出现生成的Id的重复的情况。所以我们使用美团Leaf,美团Leaf中的号段模式就是每次从数据库中读出一定数量的Id,减少对数据库的查询,从而提高性能,其中为了提高效率,为了解决尖刺问题,其还有一个双Buffer模式,会存两个号段,在其中一个号段读取到10%时,另一个号段就会异步的去数据库更新号段,从而再一次提高性能,且在服务器宕机时还能正常使用10~20分钟,给技术人员有更多的修复时间。
美团leaf的数据表,通过该表的数据生成对应的id。?

问:能说一下订单转运单的业务逻辑吗?生成运单后如何与调度中心整合在一起的?

答: 在快递员揽收之后就会进行订单转运单,我们需要进行幂等性的校验,判断运单是否已经存在,判断订单是否存在,判断重量和体积是否存在,判断收发件人的位置。数据校验完毕之后就会生成运单,如果起始位置和终点位置是相同的。说明其无需进行调度,只需要做派送任务,所以发送一个派送消息和订单状态修改消息。如果起始位置和终点位置不相同的话,就说明需要进行调度,这时需要做路线规划,为运单设置对应的路线属性和起始位置,终点位置,下一站位置等信息,然后发送调度消息(调度中心会进行监听),最终完成订单转运单。
问:合并消息为什么考虑使用redis中的List数据结构,如何判断幂等性?
答:主要是使用List作为queue数据结构,因为List中有lpush(左插入)和rpop(右去除),符合先进先出的特点,使用两点的网点Id的拼接作为key,value是List结构,直接存储对应的运单Id即可,然后我们通过set数据结构做幂等性的判断,因为set是不可以重复的,所以正好适合做幂等性判断,使用起始网点Id和终点网点进行拼接作为key,vlaue就是set结构,存储对应的订单Id,在进行订单合并操作前判断对应key中是否存在当前运单Id,如果存在就说明已经做过运单合并,直接返回,达到判断幂等性的效果。
智能调度之运输任务
在我们完成对运单的合并后,我们会通过定时任务,先调用base服务查询有排班的司机,调用司机服务的运力计算方法,通过司机id查询车辆路线中的起始网点id和终点网点id做拼接操作到redis中查询对应的运单list,通过运单号查询物品的最终重量(这里还会使用体积/轻抛系数),做一个累加操作?,循环的做运力计算,但总重量大于车辆载重的80%就表时满载,然后从redis中查询出的运单的重量过大就将数据重新插入redis,这时我们使用rpush(又插入),我们规定载重到80%为满载,50%为半载,5%为空载。
问: 能说一下xxl-job的分片式调度是在什么场景下使用的吗?这样做的好处是什么?
答:在进行车辆运力计算的时候需要使用xxl-job,我们需要使用定时任务让调度中心定时去做计算运力的业务,到达在发车前装好运输的东西,我们对xxl-job做了集群,使用分片广播的策略,通过取模的方式轮流让xxl-job发送任务,达到负载均衡的效果。
问: 使用xxl-job做计算运力时需要有什么需要解决的难点吗?
答: 在使用xxl-job的时候我们需要加上分布式锁, 如果不加分布式锁会导致部分用户的物品会被装到不同车上,用户体验非常的不好,所以保证每次计算运力的时候只一个xxl-job在执行。
智能调度之作业范围
?问:MongoDB存储的数据结构与MySQL存储的数据结构有什么区别?
答:MongoDB中存入的一条条数据叫做Document,其是以BaseJson的形式进行存储,而Mysql则是关系型数据库,存的是一张张表。
问: 为什么会使用到MongoDB?MongoDB中如何存储坐标位置数据?如何实现附近的人查询?
答:在MongoDB中可以存在坐标数据也就是经纬度数据,其属性名:?polygon,在我们的业务中会给机构和快递员设置工作范围,这个工作范围是通过多个坐标点组成的,它会形成一个闭环,最终将这一组坐标已数组的方式存入MongDB中,在获取我们需要判断某件商品被谁负责可以使用MongoDB中query的方法intersects方法判断该坐标点是否与对应的作业范围有有交集,如果有就说明有此机构或快递员负责。
/**
* 查询附近的人的所有用户id
*
* @param userId 用户id,中心点用户
* @param metre 距离,单位:米
* @return 附近的人
*/
@Override
public List<Long> queryNearUser(Long userId, Double metre) {
//1、根据用户id,查询用户的位置信息
Query query = Query.query(Criteria.where("userId").is(userId));
UserLocation location = mongoTemplate.findOne(query, UserLocation.class);
if (location == null) {
return null;
}
//2、以当前用户位置绘制原点
GeoJsonPoint point = location.getLocation();
//3、绘制半径
Distance distance = new Distance(metre / 1000, Metrics.KILOMETERS);
//5、构建查询对象
NearQuery nearQuery = NearQuery.near(point).maxDistance(distance);
//6、执行查询,由近到远排序
GeoResults<UserLocation> geoResults = mongoTemplate.geoNear(nearQuery, UserLocation.class);
//7、获取结果对象,其中userLocationGeoResult.getDistance()可以获取目标点与中心点的位置
return geoResults.getContent().stream()
.map(userLocationGeoResult -> userLocationGeoResult.getContent().getUserId())
.collect(Collectors.toList());
}先查询当前用户的经纬度信息(坐标信息),通过Distance创建以当前位置中的圆形范围,通过NearQuery中的maxDistance方法构建条件最终通过MondoDBTemplate查询出在该范围中的其他用户的坐标,在MongoDB中会存储每个用户的坐标信息。
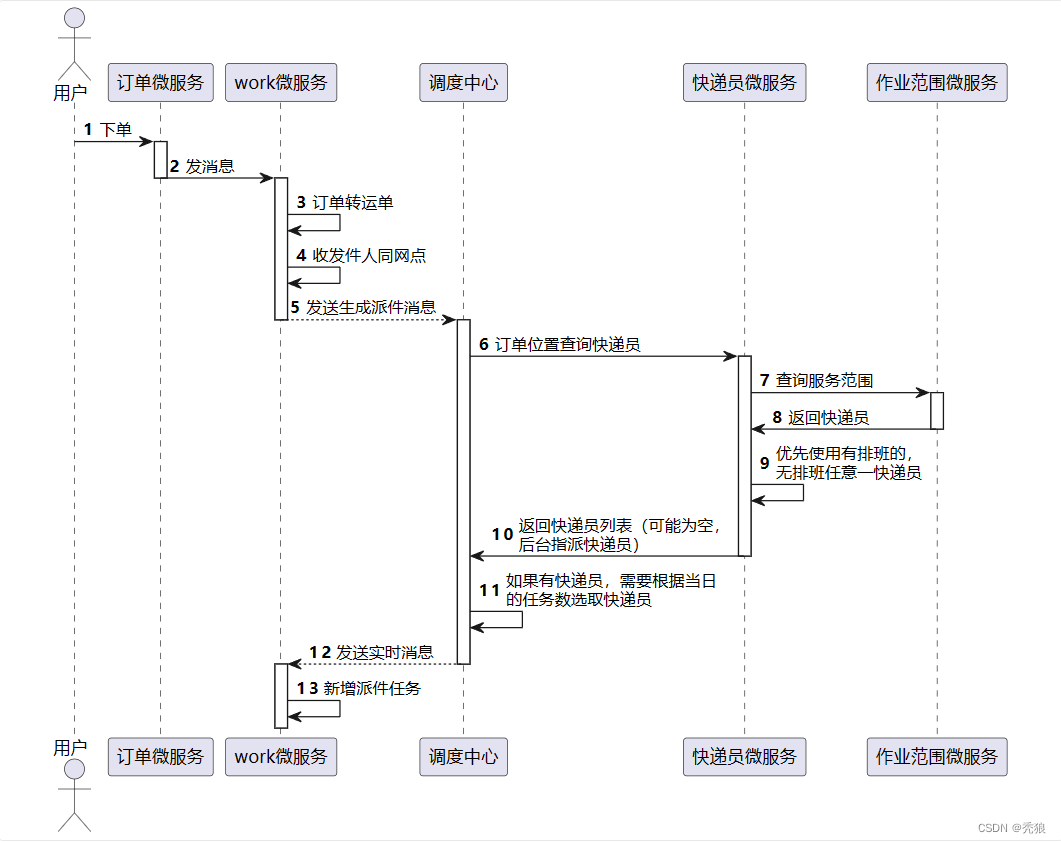
问:用户下单后如何确定为其服务的快递员??
答:通过Query中的intersects方法构建条件查询用户坐标有某个快递员的作用范围有交集。
问:作业范围如果不使用MongoDB,还可以使用其他技术实现吗?
答: 还可以使用es,在es中也可以存储经纬度数据,基本上通过特定方法就可以实现,但是具体什么方法,我目前不清楚。
智能调度之取派件调度
?取件调度图:

取件流程:
在用户下单会发消息到调度中心,调度中心会发送消息消息到快递员微服务,在该微服务监听到消息后,通过提供当前的位置查询出负责的快递员,此时查询的快递员都是今天有排班的,如果没有查到快递员的话就做分配状态标记,设置为后台分配,如果存在多个快递员,我们就提供查询出快递员当日的任务数,取任务数最小的快递员(这里查询出任务数量时,为0个的快递员是没有值的,所以需要遍历创建对应的数量将其设置为0),在获取快递员id后我们需要发送消息,如果当前时间和预计结束时间大于两个小时的话,就发送延迟消息,通过需要发送消息时间减去当前时间就是要延迟的时间,最终实现一延迟效果,如果小于两个小时的话就直接发送。(该发送的消息就是通知快递员取件的消息,也就是快递员微服务)
?派送任务图:
情景1:司机入库时,运单流转到最后一个节点,需要快递员进行派送。
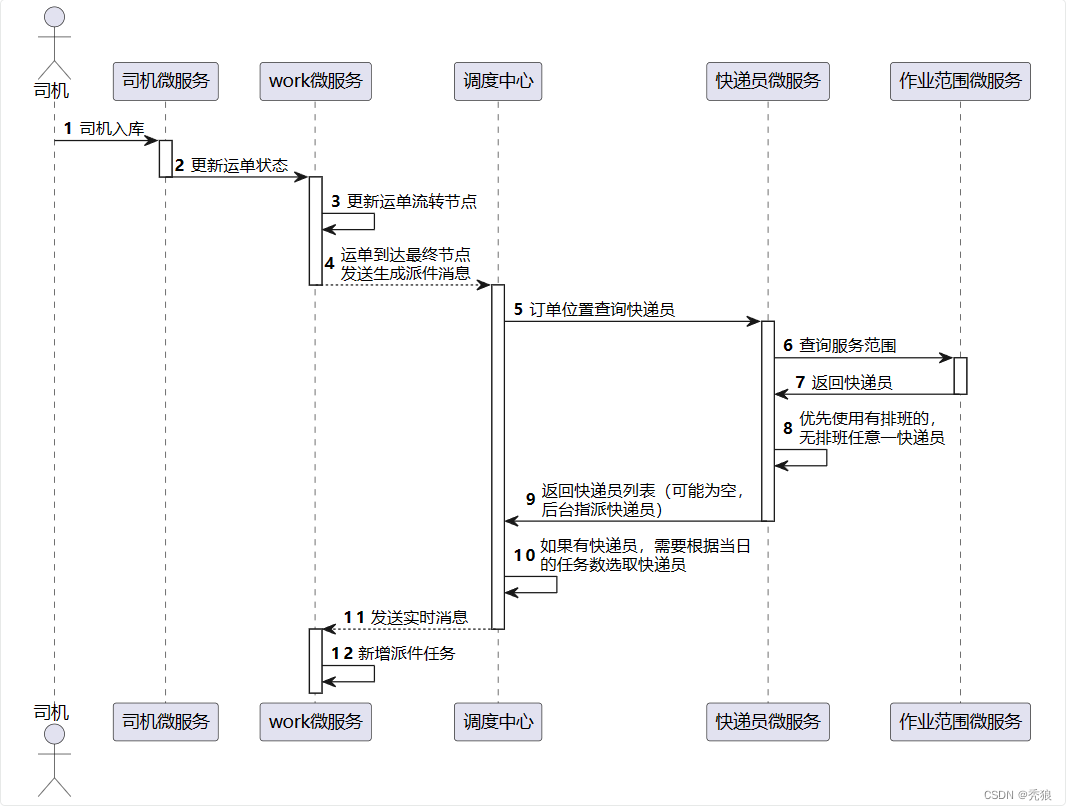
?情景2:在下单时,发件人与收件人的服务网点相同的时候需要进行派件任务。
派送流程:
与取件流程相似,在到达终点对应的网点之后,通过终点位置查询查询出负责该范围的有排班的快递员列表,通过获取快递员当前的任务数量进行排序,取任务数最小的快递员,如果快递员列表为空就需要后台手动分配快递员,最终查询到快递员id,通过实时发送消息到快递员微服务,通知快递员派送,并且发送消息到运单服务在该服务中新建派送任务。
取消任务
 ?取消任务流程:
?取消任务流程:
快递员可能会因为个人原因取消任务,那就需要重新发送区间任务,此时就会查询订单位置负责的排班的快递员列表(之前取消订单的快递员会取消排班,查不到他的),通过查询任务量进行排序,取任务量最小的快递员id,发送实时新建任务消息给work微服务(这个服务包含任务,运单的服务),最终实现新建任务。
问: 用户下单后,是如何确认上门取件的快递员的?如果有多个快递员怎么处理?
答: 根据下单位置的经纬度与快递员的作业范围做循环交集判断(这个过程咋在MongonDB中判断), 此时就能查到零个或多个快递员,如果没有快递员就需要后台手动配置快递员,如果只有一个快递员就直接返回,如果存在多个快递员,则我们需要通过快递员当日的任务数进行由低到高排序(在任务表中通过快递员id进行分组查询任务的个数使用聚合函数count),最终取任务量最小的快递员。
问: 系统分配给快递员的取件任务,快递员如果将任务取消后,该如何处理?
答: 在快递员取消任务后,会重新发送取件消息到调度中心微服务,此时就修改当前快递员的排班,继续根据下单的位置与快递员作业范围做循环交集的判断,如果查出0个就需要后台手动设置快递员,如果只有一个则直接返回,如果存在多个,需要通过快递员的当日任务数进行由低到高的排序,最终取任务量最小的快递员。
问:生成取件任务,为什么会用到延时队列?
答:如果太早发送消息,对用户体验不是很友好,一般取件的时间在两个小时,?需要我们在预计结束时间的前两个小时才发送延迟消息,如果小于两个小时就直接发送实时消息。
问:?生成取派件任务为什么不在work中直接生成,而是发消息到调度中心,再发消息到work中?
答:为了微服务单一职责的原则,我们将关于调度的方法全部放到调度微服务中,在调度服务中就是对mq的监听不会去操作数据库,而在work微服务中就是编写一些操作数据库的方法。
物流信息微服务总结
在该模块中我们使用Mongodb进行数据的存储,在数据库中一个运单对应一个物流信息,在document中会存储一个list该list中存储到达的网点,最终通过MongodbTemplate获取对应的数据。

问: 你们项目中的物流信息那块存储是怎么做的?为什么要选择MongoDB?
答:
1. 在最开始的时候我们考虑使用mysql,但是物流信息到每个网点都需要创建一条数据进行记录,效率十分低下,所以我们引入了Mongodb。
2. 其可以存储json的数据,在数据中可以嵌套document,并且Mongodb的特点就是:事务级别低,非常适合存储大量的数据,通常存储一些不重要的数据,正好符合我们的要求(所以我们不使用redis)。
问:? 针对于查询并发高的问题你们是怎么解决的?有用多级缓存吗?具体是怎么用的?
答:
1.物流信息模块就会存在高并发的情况,因为经常会同时有大量恶的用户查询物流信息。所以我们使用二级缓存进行解决高并发的问题。
2. 一级缓存我们使用Caffeine,Caffeine的使用就是引入依赖,进行配置即可使用,二级缓存我们使用redis,redis通过使用SpringCache即可使用添加对应的注解在方法即可,常用的就是@Cacheable和@CachePut。
3.redis缓存和Caffeine缓存有什么区别:相比于redis,Caffeine是和代码写在一起的,其就是基于JVM的内存栈,在查询缓存时不需要网络开销,而redis需要手动部署,在查询时需要网络开销。
问:??多级缓存间的数据不一致是如何解决的?
答:
1. 二级缓存也就是redis我们只需要在增删改方法上添加注解@CachePut注解即可解决数据一致的问题。
2. 一级缓存也就是Caffeine,在最开始时在对应的增改操作的方法中最后会调用Caffeine对应key缓存的清空方法,但是在后续进行测试的时候发现两个相同微服务在数据做修改或新增操作时会出现数据不一致的情况(也就是清空微服务1的一级缓存后,微服务2的一级缓存还会存在),为了解决这个问题,我们先是使用Mq发送消息的形式,在微服务中做监听器,发现也只有其中一个微服务消费到消息,所以后来我们使用redis的发布订阅模式,其效果和Mq非常的相识,向对应的频道发送消息,让微服务订阅该频道进行消息的消费。
问:你说这个redis的发布与订阅模式和Mq非常的相似,那在微服务中我们为什么不大量使用redis进行消息的发送呢?
答:? redis发布与订阅没有可靠性处理,没有像Mq那样有重试机制,这就是不被大量使用的原因。
问:来,说说在使用Redis场景中的缓存击穿、缓存雪崩、缓存穿透都是啥意思?对应的解决方案是啥?实际你解决过哪个问题?
答:??
1.缓存击穿:某一个热点key,在高并发的场景下,该key过期了,导致大量的请求去访问数据库,压垮数据库。
解决方案:
- 不为热点key设置过期时间。
- 使用分布式锁,在请求查询数据库时需要获取锁,每次保证只有一个查询,在查询到数据后将其重新设置到redis里并解锁,其他请求会在查询数据库前再判断一次缓存对应的缓存是否存在。
2.缓存雪崩:大量的key设置了相同的过期时间,在同一时间同时过期,导致大量的请求去访问数据库。(情况1) redis宕机。(情况2)
解决方案:
- 情况1方案:错开设置过期时间,为每个key多设置(1~11分钟)时间。
- 情况1方案:设置服务降级。
- 情况2方案:搭建redis集群。
- 情况2方案:设置服务熔断。
- 情况2方案:设置二级缓存。
- 情况2方案:设置限流。
3.缓存穿透:查询的key在缓存和数据库中都不存在,每次查询数据库,导致压垮数据库。
解决方案:
- 在数据库中没有查到信息,也将key关联null的键值对存放到缓存中,这样在再次使用同样的key查找时就会从缓存中获取数据,但是这些缓存是没有用的,会白白占用空间。
- 使用布隆过滤器。
在实际中我遇到缓存雪崩的问题,在解决方法上我使用二级缓存。
问: 说说布隆过滤器的优缺点是什么?什么样的场景适合使用布隆过滤器?
答:
优点
- 存二进制的数据,不存储真实的数据,快且安全。
- 插入和查询速度快,类似HashMap,时间复杂度为O(n)
缺点?
- 判断数据的存在有误差。
- 不能删除,因为数据间可能有相同的Hash值,删除对导致其他数据无法查出。
在判断数据不存在上非常适合使用布隆过滤器,在此时没有误判的可能性。?
为了解决过滤器的缺点:我们可以使用多个哈希函数进行计算,计算出多个位置,在这些位置上设置值为1,就表示某数据存在,这仅仅也只是减低误判率。
分布式日志和链路追踪
?问:? 生产环境出现了问题,你们是如何排查的?
答: 在单体项目上我们通常使用Linux指令进行查询,这里就包括:tail 查询日志的尾部,head查询日志的头部,cat查询日志的全部。当然在我们的项目中我们使用分布式日志也就是Graylog。通过Graylog可视化面板查询错误日志,实现排查。?
?问:你们的日志是如何存储的?
答: 使用GrayLog将日志数据存储到es中。
问:?web接口性能比较差,你会如何排查?
答: 使用GaryLog面板可以查看每个接口的调用时间,通过时间的长短来判断接口的性能,从而进行排查。
问:? 微服务间的调用关系比较复杂,你会如何梳理?
答: 使用Skywalking可以查看微服务间恶的调用情况,以拓扑的结构展示出来。
问:? 你们项目中使用什么性能监控工具?
答: 使用Skywalking。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!