Transformer简单理解
发布时间:2024年01月16日
目录
一、CNN存在的问题:
- 过拟合问题。
- 需要堆叠大量卷积层才能识别图片的整体特征,每层卷积层需要重复的实验和证明。而Transformer的Encoder只需要堆叠少量层就能识别图片的整体。
二.Transformer整理架构分析:
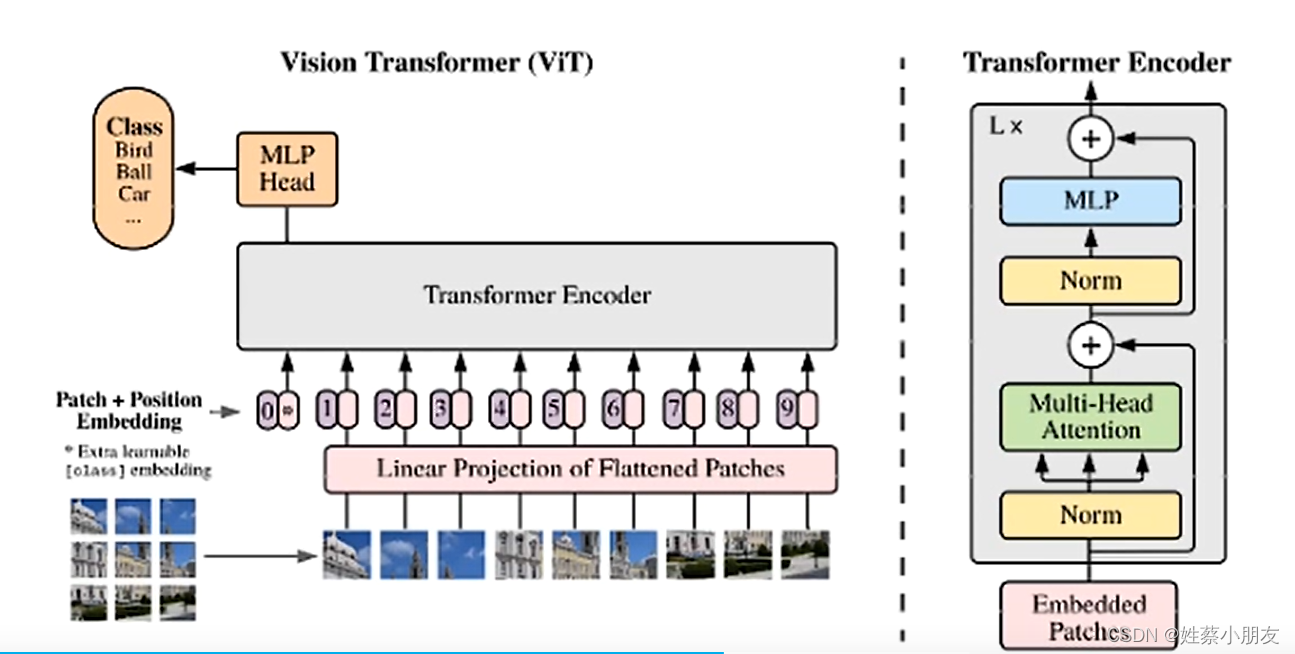
- 首先将图片分隔成小的图片,对每个小图片的矩阵(10103)进行拉长形成一个向量(300*1),作为输入序列。
- Linear Projection of Flattened Patches层对输入的向量(300*1)做一个特征整合形成多个新维度的向量Patch。
1.Linear Projection of Flattened Patches层形成Patch:
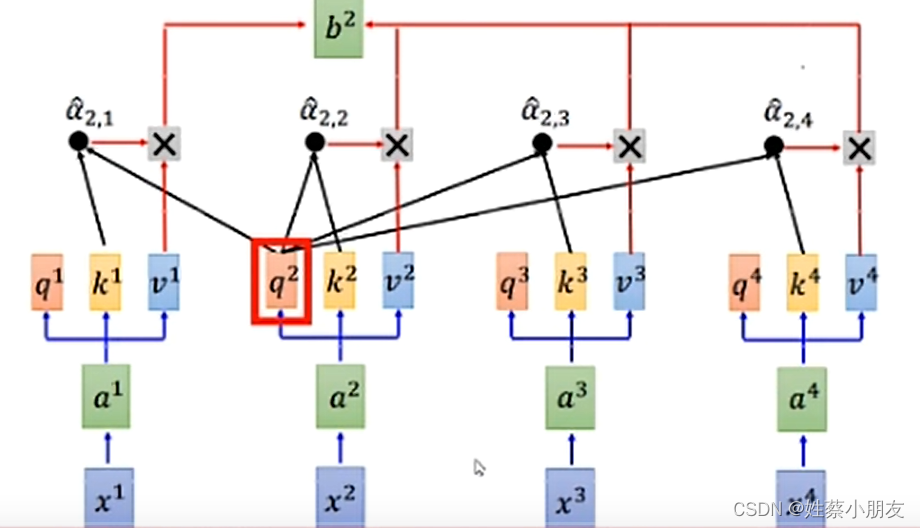
- 因为x1,x2,x3,x4之间是有联系的,首先对输入向量x1,x2,x3,x4进行特征提取,即把输入序列中的每个单元组合成比较好的新的特征。
- x1与x2,x3,x4之间的关系式由q1,k1,v1给出。
- q1为x1的查询向量,通过查询向量可以获得x1与x2,x3,x4之间的关系。
- k1为其他的xi调用qi查询x1时为qi提供的自身信息。
- v1为x1特征的代表,后续使用的是v1而不再使用x1。
- Transformer执行过程:首先各向量通过qi查询其余向量的k,获取自己与其余向量的关系,通过关系实际上得到了一组权重项,根据权重项把输入特征进行重新组合,形成比较好的新的特征。
2.对每个Patch进行位置编码Position Embedding:
- 有2种编码方式:
- 对小图片进行从上至下,从左至右进行1,2,3,4,5,6,7,8,9编码
- 对小图片进行(1,1),(1,2),(1,3),(2,1),(2,2),(2,3),(3,1),(3,2),(3,3)编码
3.Transformer Encoder:
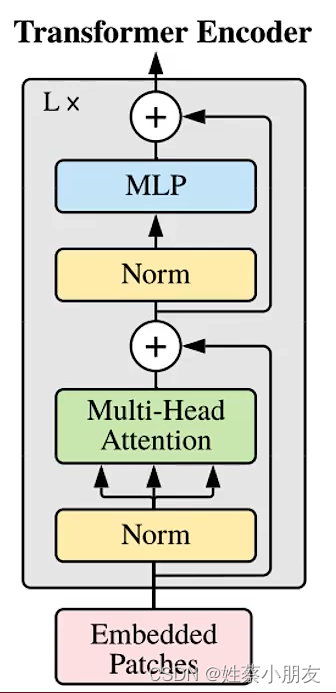
- Lx表示Transformer做了多次
- Embedded Patches输入序列
- Norm规划层
- ⊕为残差连接
- Multi-Head Attention多头注意力机制
- MLP全连接
三.公式解读:

- E为向量编码
- PP表示向量的个数,C为每个向量的维度(C,1)。特征图大小为PP*C
- D为全连接映射,xD即把(C,1)维向量映射为(D,1)维向量的规模
- Epos为位置编码,即对每个向量在位置上进行编码
- N+1中的1即为整体架构图中的0号patch,它的作用是方便对各个输入向量进行整合。
- z0作用是将各个向量与自身的位置进行组合(相加实现)
- xpE表示对E中每个向量,xclass为0号patch
- MSA为多头注意力机制
- LN表示对输入数据进行规划
- +为残差连接
- MLP为全连接
- LN为对上述操作执行n次
文章来源:https://blog.csdn.net/m0_53881899/article/details/135618767
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 大米API:实现大米供应链的智能化管理与优化
- 大数据爱好者福音:Kudu框架学习网站,助你一臂之力!
- 什么是transformer模型?
- Baumer工业相机堡盟工业相机如何通过NEOAPI SDK获取相机当前实时帧率(C#)
- 使用conda在Windows上建立虚拟环境
- 排障启示录-AP无法发现、离线类问题
- 常见的排序算法---快速排序算法
- 智慧校园大数据平台功能模块
- python使用ctypes访问Windows原生API
- golang文件内容覆盖问题