kafka详解
说说你对kafka的理解
kafka是一个流式数据处理平台,他具有消息系统的能力,也有实时流式数据处理分析能力,只是我们更多的偏向于把他当做消息队列系统来使用。
如果说按照容易理解来分层的话,大致可以分为3层:
第一层是Zookeeper,相当于注册中心,他负责kafka集群元数据的管理,以及集群的协调工作,在每个kafka服务器启动的时候去连接到Zookeeper,把自己注册到Zookeeper当中
第二层里是kafka的核心层,这里就会包含很多kafka的基本概念在内:
record:代表消息
topic:主题,消息都会由一个主题方式来组织,可以理解为对于消息的一个分类
producer:生产者,负责发送消息
consumer:消费者,负责消费消息
broker:kafka服务器
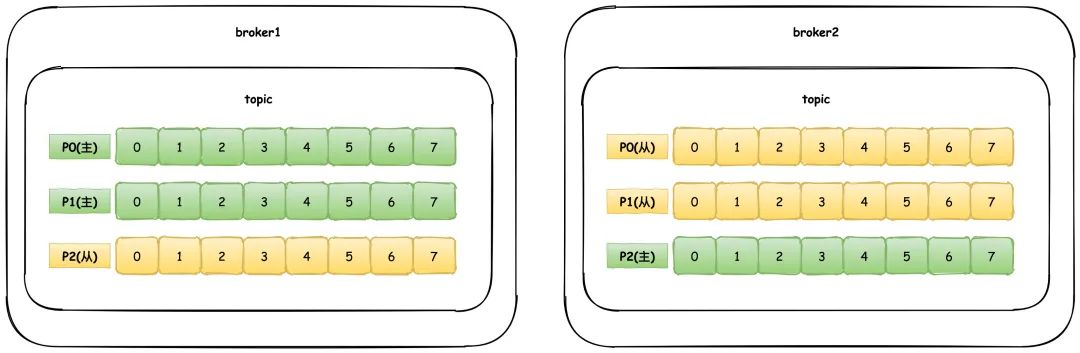
partition:分区,主题会由多个分区组成,通常每个分区的消息都是按照顺序读取的,不同的分区无法保证顺序性,分区也就是我们常说的数据分片sharding机制,主要目的就是为了提高系统的伸缩能力,通过分区,消息的读写可以负载均衡到多个不同的节点上
Leader/Follower:分区的副本。为了保证高可用,分区都会有一些副本,每个分区都会有一个Leader主副本负责读写数据,Follower从副本只负责和Leader副本保持数据同步,不对外提供任何服务
offset:偏移量,分区中的每一条消息都会根据时间先后顺序有一个递增的序号,这个序号就是offset偏移量
Consumer group:消费者组,由多个消费者组成,一个组内只会由一个消费者去消费一个分区的消息
Coordinator:协调者,主要是为消费者组分配分区以及重平衡Rebalance操作
Controller:控制器,其实就是一个broker而已,用于协调和管理整个Kafka集群,他会负责分区Leader选举、主题管理等工作,在Zookeeper第一个创建临时节点/controller的就会成为控制器
第三层则是存储层,用来保存kafka的核心数据,他们都会以日志的形式最终写入磁盘中。
如果想学Java项目的,强烈推荐我的??项目消息推送平台Austin(8K stars),可以用作毕业设计,可以用作校招,可以看看生产环境是怎么推送消息的。
仓库地址(可点击阅读原文跳转):https://gitee.com/zhongfucheng/austin
消息队列模型知道吗?kafka是怎么做到支持这两种模型的?
对于传统的消息队列系统支持两个模型:
- 点对点:也就是消息只能被一个消费者消费,消费完后消息删除
- 发布订阅:相当于广播模式,消息可以被所有消费者消费
上面也说到过,kafka其实就是通过Consumer Group同时支持了这两个模型。
如果说所有消费者都属于一个Group,消息只能被同一个Group内的一个消费者消费,那就是点对点模式。
如果每个消费者都是一个单独的Group,那么就是发布订阅模式。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- canvas创建图像数据,并在画布上展示
- 使用克魔助手进行iOS数据抓包和HTTP抓包的方法详解
- UI功能6大流程、接口测试8大流程这些你真的全会了吗?
- 中科院罗小舟团队提出 UniKP 框架,大模型 + 机器学习高精度预测酶动力学参数
- 扫描全能王启动鸿蒙原生应用开发,系HarmonyOS NEXT智能扫描领域首批
- SpringCloud之OpenFeign调用解读
- 在centos系统安装mqtt
- MongoDB存储原理
- 【华为OD机试真题2023C&D卷 JAVA&JS】机场航班调度程序
- JAVA数学区间计算,支持开闭区间、百分比、-∞、+∞