服务熔断(Hystrix)
服务雪崩
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其他的微服务,这就是所谓的“扇出”,如果扇出的链路上某个微服务的调用响应时间过长,或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,所谓的“雪崩效应”。
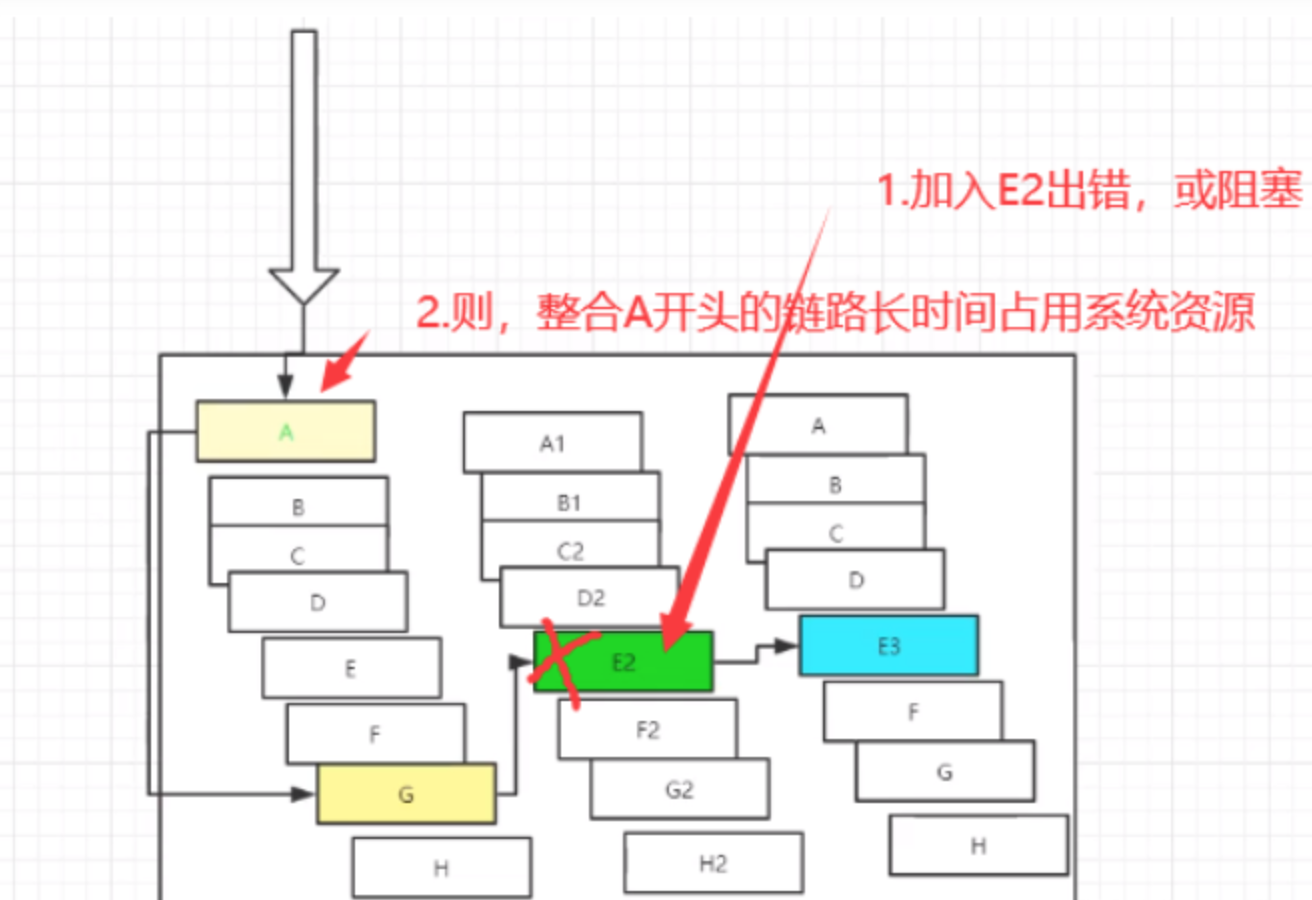
对于高流量的应用来说,单一的后端依赖可能会导致所有服务器上的所有资源都在几十秒内饱和。比失败更糟糕的是,这些应用程序还可能导致服务之间的延迟增加,备份队列,线程和其他系统资源紧张,导致整个系统发生更多的级联故障,这些都表示需要对故障和延迟进行隔离和管理,以达到单个依赖关系的失败而不影响整个应用程序或系统运行。
我们需要,弃车保帅!
什么是熔断?
熔断简单来说就是在单个服务出现问题,不可用时,为了避免引发更严重的问题,导致整个服务链路不可用的情况下,可以采用熔断的方式来避免。熔断一般情况下意味着服务的降级,可以理解为是一种异常兜底策略,需要服务的上游调用方来实现。
在访问量比较高的情况下,客户端访问A节点,A节点一个依赖的服务节点B出现延迟(或者不可用),这种情况下,无论是重试策略(重试3次)也好,或者超时策略(超过1S返回失败或者默认结果)也好,都会比正常请求消耗更多的资源,这时在流量高的场景有可能造成A服务资源被沾满,从而导致A服务其他接口也出现延迟或者不可用情况,再严重一些可能会出现雪崩,A服务依赖的上游也不可用,进而整个集群链路崩溃。
因此,服务异常时可以通过熔断的方式来进行快速的失败,避免后续流量继续请求到服务B,避免雪崩。
熔断更多的是指服务之间的熔断,熔断通常都会有恢复策略。
什么是降级?
降级,其实也是一种兜底策略,可以理解为主方案行不通了,换一个备用方案。比如,查询缓存失败,改为查询数据库,查询数据库也失败,返回“系统繁忙”给到用户,这种就是降级。再比如,A服务调用B服务,调用失败,返回“系统繁忙”也算降级,如果此时进行重试,那么可以叫“容错”。
降级其实有很多方案:
- 被动降级:服务不可用时,返回备用数据,或者提示文案。比如,广告推送,正常推送查询用户感兴趣的,如果服务不可用,改为推送默认广告。
- 主动降级:人为的把服务设置为不可用。比如双十一,将评论,收藏等功能主动降级为不可用,避免用户请求占用服务资源。一般通过预制的降级开关实现。收到客户端请求后,不会真的去请求评论,收藏服务,直接返回用户,功能不可用。
- 自动降级:通过预制的规则,自动的实现降级,自动实现恢复。比如,熔断导致的降级,限流触发降级,超时降级等。
自动降级与被动降级区别主要是:是否可以自动恢复。
被动降级强调的是,不受控制。可以理解为简单的if、else每次请求过来都会进行判断。
自动降级强调的是,自动化。可以理解服务出现问题,达到阈值条件时拒绝后续请求,同时感知服务状态,达到可用条件时,再允许后续请求。
服务熔断(Hystrix)
在微服务架构中通常会有多个服务层调用,基础服务的故障可能会导致级联故障,进而造成整个系统不可用的情况,这种现象被称为服务雪崩效应。服务雪崩效应是一种因“服务提供者”的不可用导致“服务消费者”的不可用,并将不可用逐渐放大的过程。熔断器的原理很简单,如同电力过载保护器。它可以实现快速失败,如果它在一段时间内侦测到许多类似的错误,会强迫其以后的多个调用快速失败,不再访问远程服务器,从而防止应用程序不断地尝试执行可能会失败的操作,使得应用程序继续执行而不用等待修正错误,或者浪费 CPU时间去等到长时间的超时产生。熔断器也可以使应用程序能够诊断错误是否已经修正,如果已经修正,应用程序会再次尝试调用操作。
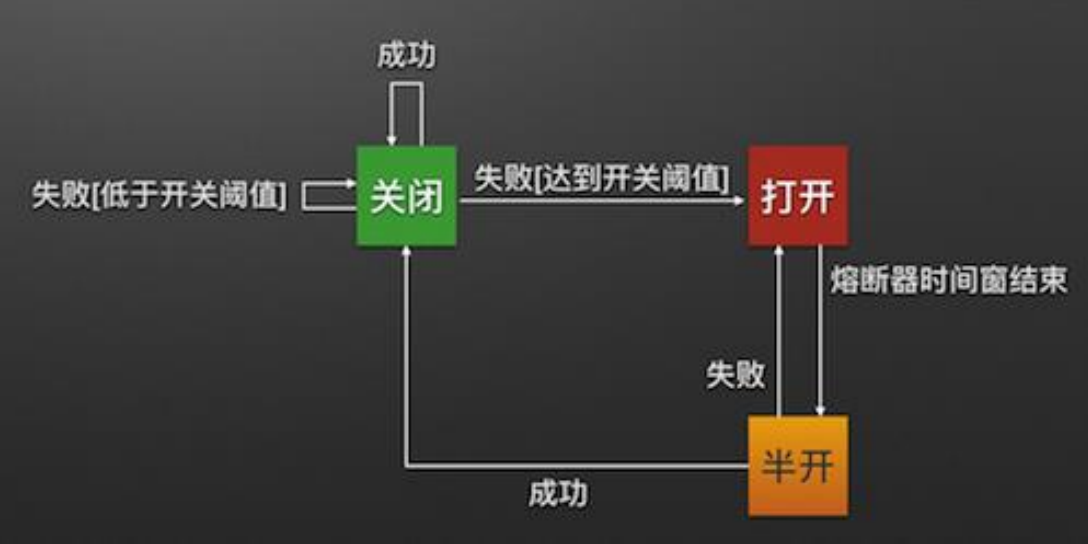
Hystrix 断路器机制
断路器很好理解, 当 Hystrix Command 请求后端服务失败数量超过一定比例(默认 50%), 断路器会切换到开路状态(Open). 这时所有请求会直接失败而不会发送到后端服务. 断路器保持在开路状态一段时间后(默认 5 秒), 自动切换到半开路状态(HALF-OPEN). 这时会判断下一次请求的返回情况, 如果请求成功, 断路器切回闭路状态(CLOSED), 否则重新切换到开路状态(OPEN). Hystrix 的断路器就像我们家庭电路中的保险丝, 一旦后端服务不可用, 断路器会直接切断请求链, 避免发送大量无效请求影响系统吞吐量, 并且断路器有自我检测并恢复的能力。
Hystrix 如何实现熔断
场景
服务调用者A,需要调用服务提供者B的接口。考虑到B服务如果出现超时不可用情况,要减轻对A服务的影响。比如:B服务接口响应时间超过1S,开启降级,提供 fall back方法(服务调用者自行根据业务创建该方法),返回默认信息(也可以默认失败),在B服务接口出现不稳定(10秒内调用20次失败率50%以上时,开启熔断,后续5秒的请求直接走降级fall back 方法 返回默认信息)
熔断的默认触发机制
使用Histrix 默认策略 10秒内 调用20次 失败率50%以上 触发熔断 默认熔断 5s
步骤
服务提供者
- 提供服务接口。
- 模拟超时失败。
- 启动服务
服务调用者
- 引入jar包。
- 开启熔断配置注解。
- 启动配Enable注解。@EnableCircuitBreaker
- 如果使用Fein 对Fein 需要开启Histrix 支持(yml 配置文件增加 feign.hystrix.enabled=true)
- 在调用服务提供者接口处进行配置。使用注解方式。
- @HystrixCommand
- 也可以使用默认的配置属性
- 创建与注解配置一致的fall back方法
- fall back 是作为一个降级的方法,我们也可以不使用降级。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 游泳耳机哪个品牌好?2024年游泳耳机十大品牌排行榜TOP4
- R语言的ggplot2绘制分组折线图?
- ? iOS技术博客:App备案指南
- springboot的配置文件,以及spring boot自动装配的原理,bean的管理。
- idea连接数据库(完整版教程)
- 带你学C语言-指针(4)
- Git 对项目更新的时候提示错误 repository not owned by current user
- RT-Thread学习
- 【Dart】P0 Win、Mac 使用与安装
- 相控阵天线阵元波程差相位差计算