高可用架构去中心化重要?
1 背景
在互联网高可用架构设计中,应该避免将所有的控制权都集中到一个中心服务,即便这个中心服务是多副本模式。
对某个中心服务(组件)的过渡强依赖,那等同于把命脉掌握在依赖方手里,依赖方的任何问题都可能成为你不稳定的因素。
而弱化强依赖,实现可降级交互,是一种设计理念和架构模式,目的是将系统的控制权分散到各个节点,避免出现单点故障或中心化控制的问题。
这一点,我们称之为『去中心化』。
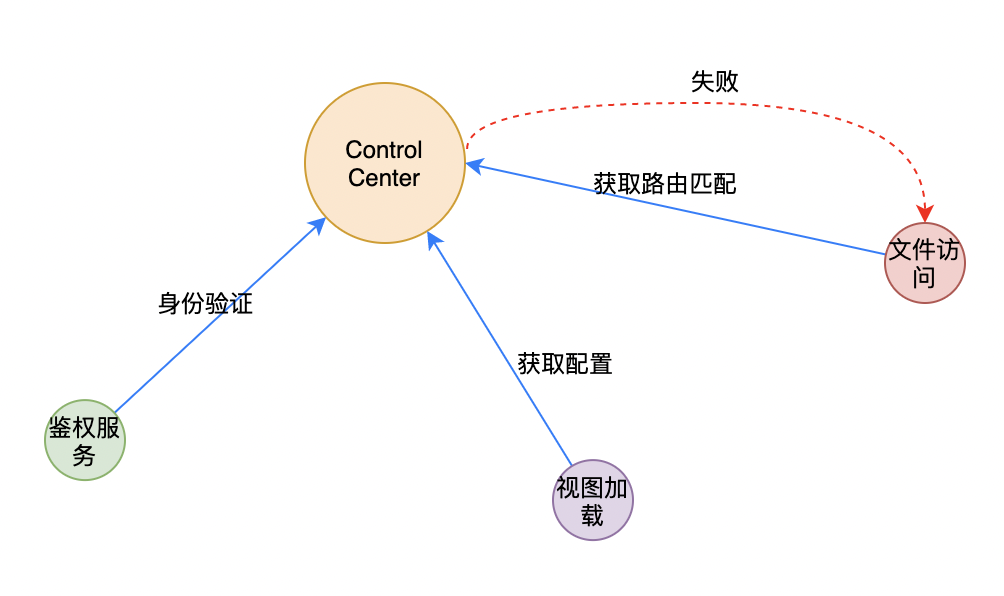
具体来说,去中心化架构中的每个节点都具有自主性,可以独立地处理和存储数据,并且节点之间通过特定的协议或机制进行通信和协作。这种架构可以提高系统的可用性和可扩展性,降低对单个节点的依赖性,增强系统的可靠性和容错能力。
2 经典去中心化架构设计
我们去分析业内的很多经典的软件设计,都可以看到他们为了实现降低对中心服务(组件)的依赖,做了很多方案优化。
2.1 微服务注册中心
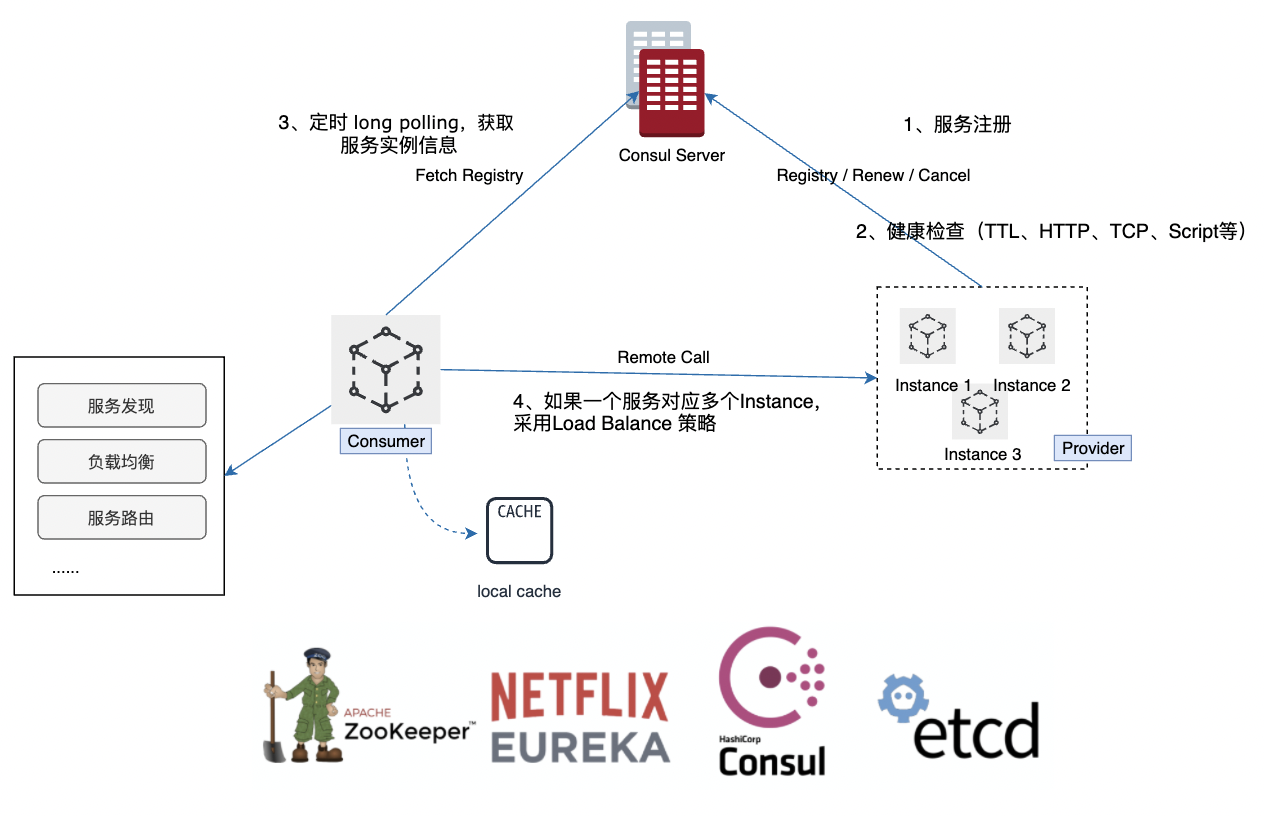
如上图所示:
1、Provider 服务提供者:服务向注册中心注册服务信息,即 服务 -> 服务实例 数据模型, 同时定时向注册中心汇报健康检查,如果一定时间内(一般90s)没有进行心跳汇报,则会被注册中心剔除。
所以这边注意,注册中心感知到应用下线并进行剔除这个过程可能比较长。
2、Consumer 服务消费者:服务向注册中心获取所需服务对应的服务实例信息。这边需要注意,在Spring Cloud生态中,一般通过实时订阅或者定时拉取方式从注册中心中获取所需的服务实例信息。
3、Remote Call 远程调用:Consumer从注册中心获取的Provider的实例信息,通过 Load Balance的策略,确定一个实际的实例,发起远程调用。
去中心化分析:很明显,我们的注册和订阅都依赖注册中心(Eureka、ZK、Etcd或者其他...),如果这个注册中心挂了,我们连对服务的访问路由地址都无法匹配,请求都没办法发出去。
所以现在一般Client端会缓存依赖服务的地址列表到本地,即便注册中心挂了,在短时间内也会正常运行,只是新增或者更新的服务实例无法获取到。
2.2 分布式存储系统
分布式存储系统是实现去中心化的一种重要实现方式。通过将数据分散存储在多个节点上,而不是集中存储在中心服务器上,分布式存储系统可以避免单点故障和中心化控制的问题,提高系统的可用性和可扩展性。
在分布式存储系统中,每个节点都有自己的存储设备和计算能力,可以独立地存储和检索数据。节点之间通过特定的协议或机制进行通信和协作,共同维护系统的数据和功能。这种架构可以降低对单个节点的依赖性,增强系统的可靠性和容错能力。
?
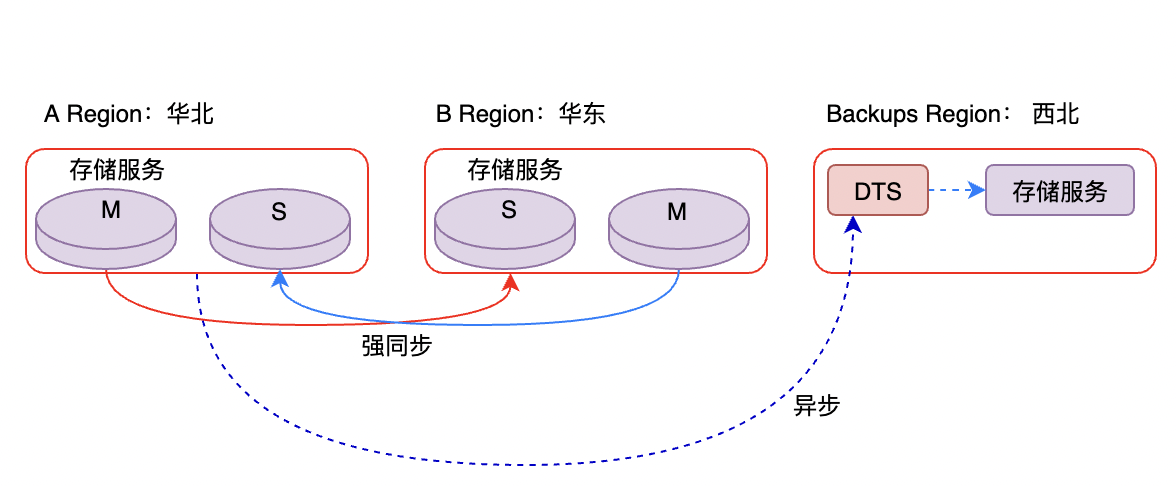
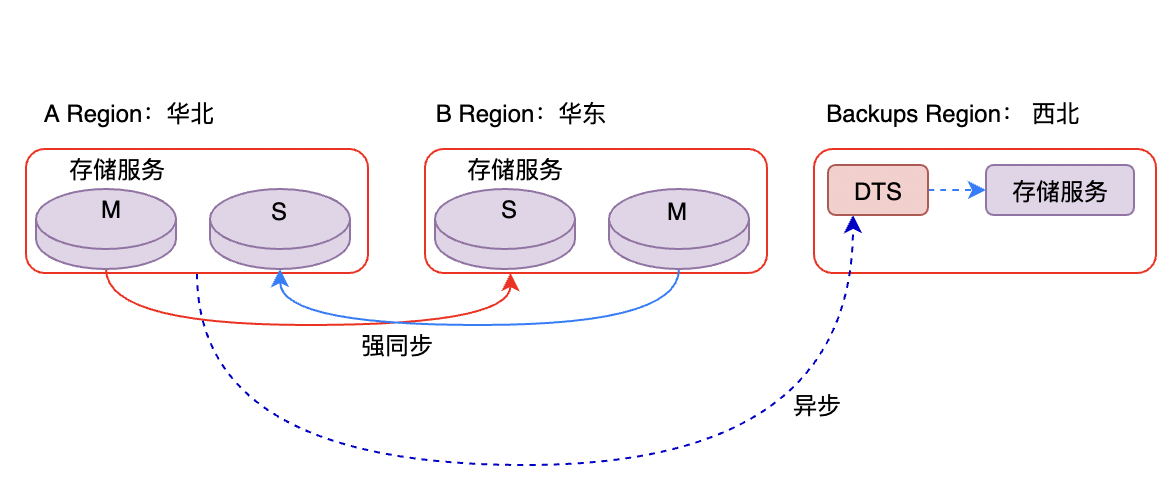
如图,B Region 如果挂了,流量会调度到A Region中,如果A、B均挂了,则会启动Backups Region,当然,数据可能会有一些延迟,但依然能保证系统正常提供服务。
3 常用的架构设计方案
业内有一些优秀的设计经验,用于规避中心故障导致的服务雪崩。
3.1 多副本模式+重试
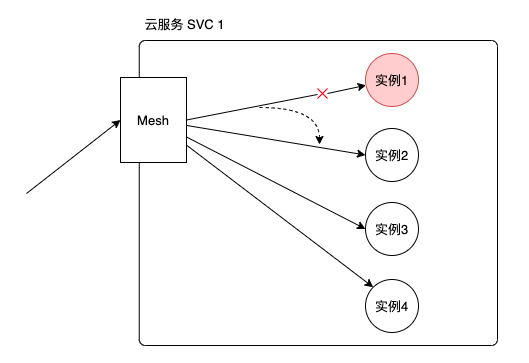
比如你的中心服务有20个副本(实例),其中一个副本(实例)出故障,导致执行返回5xx,那么第二次请求的时候大概会有 19/20 的成功概率。
负载均衡模式默认是RR,所以实例越多,实际上重试成功的概率会越高。
3.2 多副本模式+异常隔离
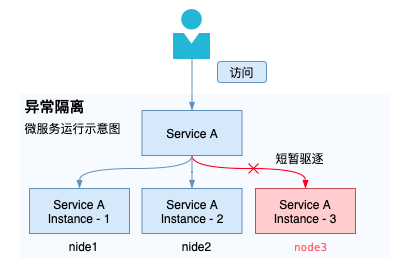
如果依赖的中心服务存在多副本,那么即使存在不健康副本(实例),只要是被自动驱逐之后,服务依旧是健康的。
但是驱逐需要保障剩余的副本能够支撑峰值流量的冲击。
3.3 强大的主备模式
标准两地三中心建设(同城主、同城备、异地备),避免单机房故障,甚至区域自然灾害导致系统无法提供正常服务。
3.4 极限兜底:如缓存保证依赖可降级
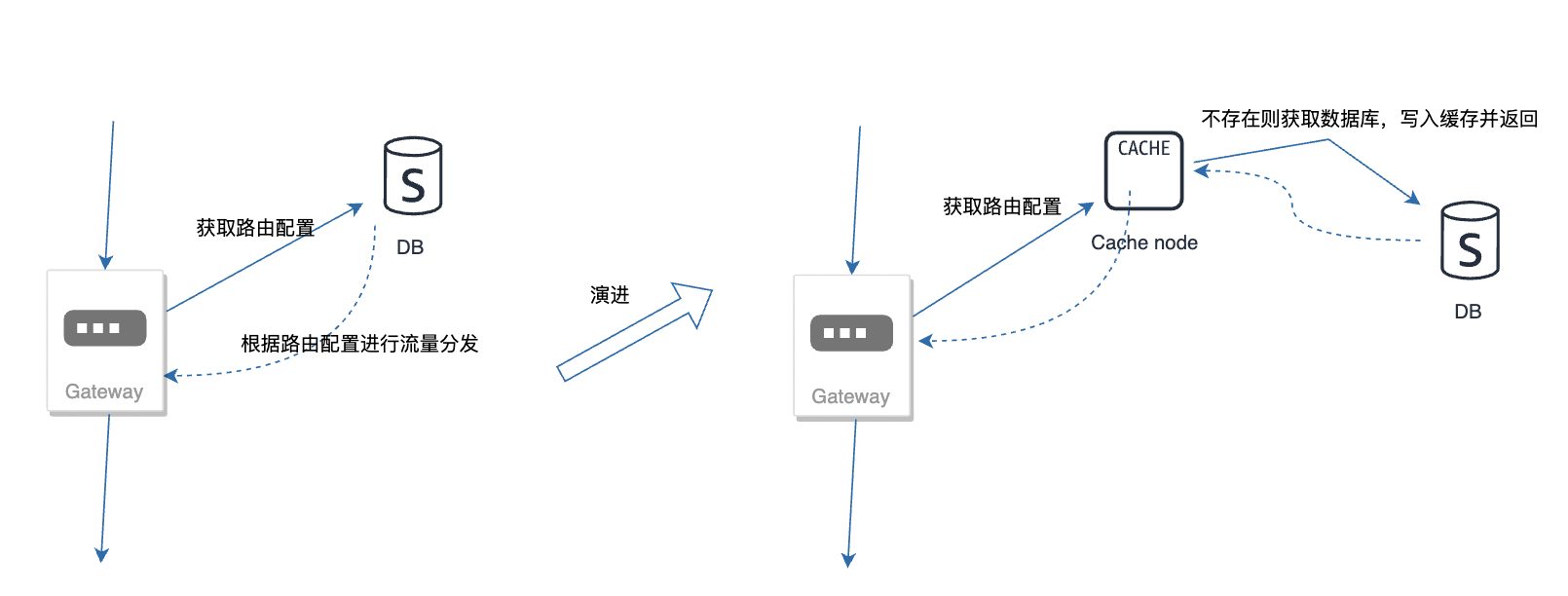
类似微服务注册中心的做法,用一层缓存做兜底,一般来说数据库跟缓存同时出故障的概率不高。
笔者的团队就有一个案例:依赖的Etcd服务,用于路由分发的配置信息存储,失联了4小时,靠着缓存保证了大部分流量的正常运行。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- vscode远程服务器中文显示为数字乱码,终端无法输入中文
- SaaS应用框架对比:Spring Boot vs Flask vs FastAPI
- 【51单片机系列】LCD1602液晶模块
- 一篇文章掌握SpringCloud与SpringCloud Alibaba的区别
- 【Java进阶篇】Java中Timer实现定时调度的原理(解析)
- matplotlib 使用,各种图形的绘制(含代码注释)
- 信息量&信息熵
- c语言基础知识(续)
- 3-4 D. DS堆栈--括号匹配
- 线性PID控制器