设计模式——1_5 享元(Flyweight)
今人不见古时月,今月曾经照古人
——李白
文章目录
定义
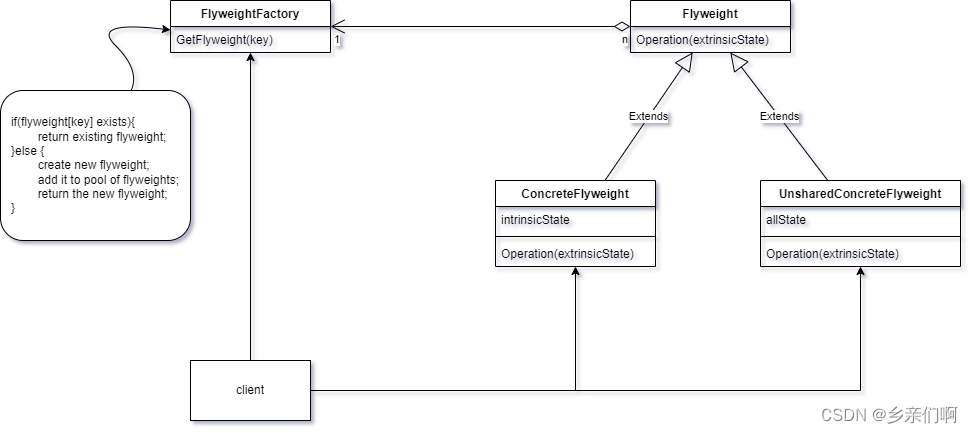
运用共享技术有效地支持大量颗粒度对象
享元 真是一个非常非常优秀的翻译
如果你单看 四人组 对享元的定义,那很容易就会把他理解成类似 连接池 那种对对象进行共享的模式。但是如果享元就是对对象池的管理的话,那他的元字如何解释呢?
窃以为,这里的元应该做 【元件】 讲,共享元件,才叫享元。享元不是对整个大对象进行对象池管理,而是对大对象中的重复部分抽离出来进行管理。
图纸
一个例子:可以复用的样式表
在 css 中,我们会把经常用到的样式组合成一个 css 类,然后在标签中通过 class=XX 的方式让N个标签引用同样的样式
如果你用过 jxl 或者 poi 这样的框架操作过 Excel 表格的话,就会发现你可以在一个 Sheet 里创建的样式是有上限的。可是 C# 里用于操作 office 的框架却没有这个烦恼。当然微软一家亲肯定有一些优化,可问题在于他怎么做到的呢?
准备好了吗?这次的例子开始了:
绘制表格
假如我们现在要 绘制一个表格的框架,就像这样:
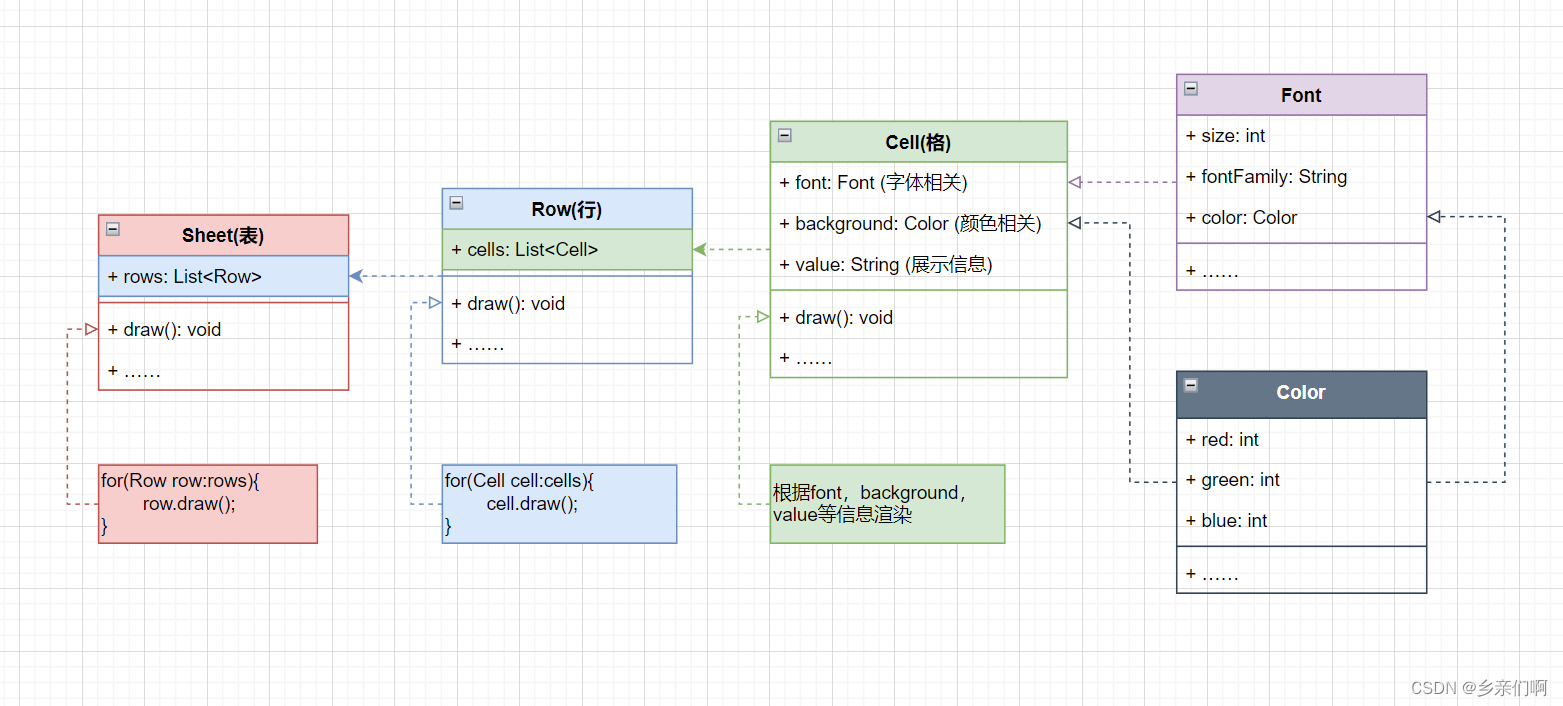
//格
public class Cell {
//设定字体
private Font font;
//背景颜色
private Color background;
//要展示的值
private String value;
public void draw(){
System.out.println("根据font+background+value进行绘制");
}
…… getter & setter & other 略
}
//行
public class Row {
private final List<Cell> cells;
public Row(List<Cell> cells) {
this.cells = cells;
}
public void draw(){
for (Cell cell : cells) {
cell.draw();
}
}
……
}
//表
public class Sheet {
private final List<Row> rows;
public Sheet() {
rows = new ArrayList<>();
}
public void draw() {
for (Row row : rows) {
row.draw();
}
}
……
}
这个框架特别好,我就喜欢这种一眼能看到头不藏着掖着的框架。这玩意,他单纯
可是太单纯也有问题,某天我们用他处理一个 1000*10 的表格的时候他直接就崩溃了
经过分析我们发现在绘制表格的时候程序占用的内存异常高,10000个格子,意味着我们会有10000个cell对象 和 10000个Font对象 以及 10000个Color对象,有没有办法简化他?
降本增效?
重构代码的方式总是大同小异的
第一步,先分析 变化和不变的地方
我们发现,1000个Row对象和10000个Cell对象 肯定是节约不了的,而 Cell 中最关键的 Value 每一格都不相同,哪怕碰巧一致,不确定性太多,无法公用
那就只能从 样式 上打主意了,Cell 通过 一个 Font 对象 和 一个 Color 对象来管理 Cell 的样式,而一个表格里面字体不超过5种,颜色不超过10种。我们却创建了整整 10000 个 Font 对象和 10000 个 Color 对象。这显然是不合理的
第二步,把变化和不变的地方拆开来
这一步已经完成了, 因为 Cell 和 Font、Color 本来就是通过组合绑定在一起的
第三步:有没有办法共享这些内容完全相同的样式对象?
当然有
我们可以创建 关于Font的对象池 和 关于Color的对象池,然后创建对应的工厂方法,要求 client 必须通过工厂方法来获取 Font 和 Color 对象。当我们发现 client 获取已经在池中存在的 Font、Color 对象的时候,直接从池里面把 已有对象 返还给 client;如果 client 获取的是全新的样式,则新建对应的 Font、Color 对象返还给 client,并把新建的对象写入池中
就像这样:
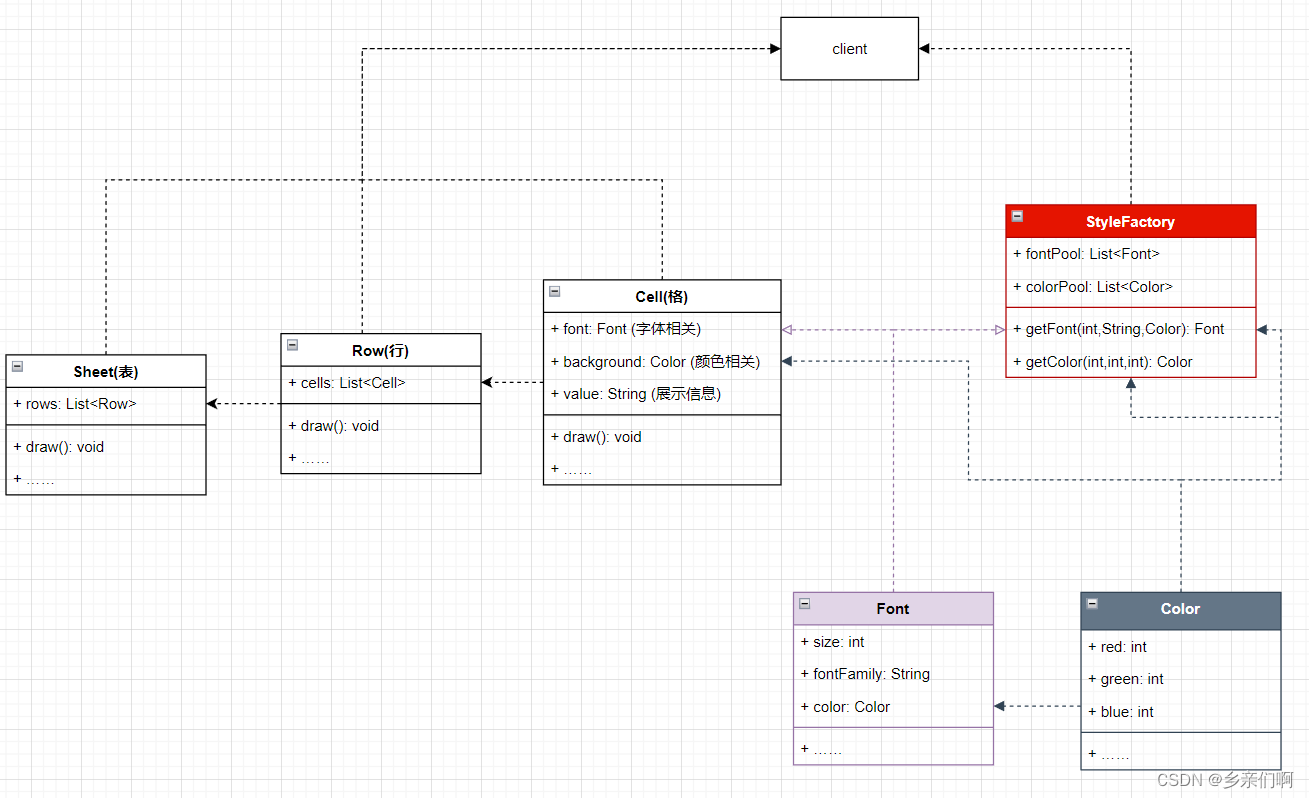
public class StyleFactory {
//字体池
private List<Font> fontPool = new LinkedList<>();
//颜色池
private List<Color> colorPool = new LinkedList<>();
public Font getFont(int size, String fontFamily, Color color) {
for (Font font : fontPool) {
if (font.getSize() == size
&& font.getFontFamily().equals(fontFamily)
&& font.getColor().equals(color)/*Color的equals方法已经重构过了*/) {
return font;
}
}
Font result = new Font(size, fontFamily, color);
fontPool.add(result);
return result;
}
public Color getColor(int red, int green, int blue) {
for (Color color : colorPool) {
if (color.getRed() == red
&& color.getGreen() == green
&& color.getBlue() == blue) {
return color;
}
}
Color result = new Color(red, green, blue);
colorPool.add(result);
return result;
}
}
我们增加了 fontPool 和 colorPool 这两个列表用于管理程序中已经出现过的 Font、Color对象
然后通过定义 StyleFactory 的方式管理 Font、Color 对象创建的方式,同时管理池,最终实现相同样式的共享,从而大大降低了内存损耗
而这正是一个标准的 享元 实现
为啥要用遍历而不是映射表
因为没必要,上文已经讲过 Font 在一个表格中出现次数不超过 5 种,Color 不超过 10 种。这种数量级的遍历根本不会对性能产生影响
碎碎念
抽象变化的部分 & 抽象不变的部分
在之前的设计模式中,我们通常是以不变的部分作为基层,把变化的部分剥离开来,让他去和不变的部分进行组合以实现降低耦合的效果
但享元比较特殊,他是少有的剥离不变的部分,以变化的部分为基准,让变化的部分去找不变的部分的设计模式
享元和单例
如果把享元的内容从对象内的某些状态,拓展到整个对象,这时候的享元就是对整个对象的对象池管理,此时我们甚至可以说单例是极致的享元
但是享元和单例的本质是不同的
- 单例讲究从根本上只有一个对象,而且这一个对象的状态也是共享的部分,所以他也应该是可变的
- 享元讲究一种状态一个对象,一个享元对象被创建出来后,他的状态应该是不可变的。因为当你改变享元对象的状态时,所有引用这个对象的外部对象都会因此而改变,这并不是我们用享元想要看到的效果。
所以硬要在创建型模式里找一个跟享元像的话,倒不如说是原型的思想更像一点:
- 对原型来说,创建一个新对象花销太大了,那行我不创建了,我复制
- 对享元来说,大量对象都有 地址不同的相同状态 占用太大了,那行别创建了,大家都用同一个就完事了
享元和String.intern()
首先我们要知道这个intern方法是用来干嘛的:
String 中的 intern() 是一个本地方法,他的作用为:假如一个字符串在 常量池 中已经存在了,则返还常量池中的该字符串;如果不存在,则把该字符串放入常量池,再返还常量池中的该字符串对象的引用
有没有觉得他跟享元超级像,其实Java中的String就是用了享元的思想。我们知道String是不可变的,我们创建的字符串会被放到某个公共区域(常量池),以便程序中所有的类共享这些字符串信息。JVM一定要这样管控字符串,如果为所有的字符串都创建全新的信息,那一下子就爆内存了。
可别认为这只是一个可知可不知的冷知识,面试官是很喜欢问问他有关的问题的,比如他可以这样问:
请问以下代码会如何输出:
String str1 = new StringBuilder("a").append("b").toString();
System.out.println(str1.intern() == str1);
String str2 = new StringBuilder("ja").append("va").toString();
//String str2 = new StringBuilder("a").append("b").toString(); //这样写效果也是一样的
System.out.println(str2.intern() == str2);
答案是这样的:
- 1.6及以下时输出 false、false
- 1.7及以上时输出 true、false
至于原因,咱这是讲设计模式的,就不展开了(这玩意跟堆 栈 永久代有关系,太长了,有机会整理JVM的笔记时再唠吧)
享元和活字印刷
就是古代四大发明里面哪个活字印刷
仔细想想,其实活字印刷就是享元思想的体现:
把每个字都制作成小方块放到字库中,需要的时候先到字库里面找,如果没找到,刻一个先用,用完再把刚刻好的那个方块放到字库中,方便下次调用
古人的智慧真是不可小觑
万分感谢您看完这篇文章,如果您喜欢这篇文章,欢迎点赞、收藏。还可以通过专栏,查看更多与【设计模式】有关的内容
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Hive之set参数大全-5
- 2024最新最全【Xmind8】下载安装零基础教程【附安装包】
- 基于深度学习的动物检测识别系统(含UI界面、yolov5、Python代码、数据集)
- 中华恐龙园贺春首播嗨爆全场,蓝海创意云开启文旅直播营销新篇章
- 从汇编语言到反汇编:X64dbg带你解析底层世界
- ElasticSearch高阶使用
- 神经网络:数据预处理知识点
- 使用JSON.parse字符串转换json报错解决办法
- 王国维的人生三境界,这一生至少当一次傻瓜
- Dart安装(Winodws)