论文精读:EVA-CLIP Improved Training Techniques for CLIP
EVA-CLIP: Improved Training Techniques for CLIP at Scale
Status: Summarizing
Author: Ledell Wu, Quan Sun, Xinlong Wang, Yue Cao, Yuxin Fang
Publishing/Release Date: May 27, 2023
Publisher: arXiv
Summary: 作者使用了一系列方法来提升CLIP的训练效率和效果,包括新的表示学习方法、更换优化器和数据增强技术,使得EVA-CLIP相比于具有相同参数量的模型徐连成本更小,性能更优。
Score /5: ????
Type: Paper
Link: https://arxiv.org/abs/2303.15389
读前先问
- 论文大方向的任务是什么?Task
大模型的训练效率问题
- 这个方向有什么问题?是什么类型的问题?Type
CLIP越来越火,但是训练起来的计算成本较高,时间较久,而且还不稳定。
- 为什么会有这个问题?Why
模型太大了
- 作者是怎么解决这个问题的?How
新的表示学习方法、更换优化器和数据增强技术。
- 怎么验证解决方案是否有效?
一方面关注效率,看看对计算成本和时间成本的压缩;另一方面关注效果,跟同等体量的模型对比效果。
论文精读
引言
CLIP是一个非常强大的视觉-语言基础模型,利用了大量的数据集学习了非常丰富的视觉表征,并且通过对图像-文本对的学校搭建起了视觉和语言之间的桥梁。但是训练CLIP模型还有很多挑战,因为它的计算成本比较高,并且当模型的规模提升时,训练起来不稳定。
在这篇论文中,作者提出了EVA-CLIP,一种可行且有效的训练CLIP模型的方案。EVA-CLIP集成了多种可以降低训练成本、稳定训练过程和提升zero-shot能力的方法,包括通过EVA模型权重来初始化CLIP、使用LAMB优化器、随机丢弃一部分输入tokens和Flash Attention。
方法
- 初始化
为了提升模型的特征表示能力和加速模型收敛,作者采用了预训练好的EVA模型来初始化CLIP的图像编码器。
- 优化器
LAMB 优化器是专门为大批量训练设计的,具有自适应的元素级学习率和层级学习率,可以让训练效率更高,收敛更快。原生的CLIP模型用的 batch size 是 32768,一些其它开源的 CLIP 模型的 batch size 设置超过了 100k。
- FLIP
FLIP(Fast Language-Image Pre-training)是一种简单高效的训练 CLIP 模型的方法,在训练过程中随机 Mask 并删除了大部分的图像块,这样的话占用的空间就会更小,batch size 就可以设置的更大。
EVA-CLIP才用了这种方法,随机 Mask 掉 50% 的图像 tokens,时间成本直接压缩了一倍,也可以让 batch size 增大一倍。
实验
- 设定
EVA-CLIP 的视觉编码器通过 EVA 进行初始化,文本编码器通过 OpenAI 的 CLIP 或者 OpenCLIP 初始化。需要注意的是,EVA 有两个版本,用 EVA-01 初始化的叫 EVA-01-CLIP,用 EVA-02 初始化的叫 EVA-02-CLIP。
LAMB 优化器的参数设置: β 1 = 0.9 , β 2 = 0.98 , weight?decay = 0.05 \beta_1 = 0.9, \beta_2 = 0.98, \text{weight decay} = 0.05 β1?=0.9,β2?=0.98,weight?decay=0.05。视觉编码器和文本编码器分别才用了不同的学习率和层衰减率,例如,在 EVA-01-CLIP-g 训练的前 2000 轮预热中,视觉编码器的学习率为 2e-4,文本编码器的学习率为 2e-5,然后在剩下的训练步骤中再将学习率逐步衰减到 0。
训练过程中还使用到了 DeepSpeed 优化库的 ZeRO-1 优化器、梯度检查点和 Flash Attention。
在训练 EVA-01-CLIP-g 的过程中,fp16 精度就足够保证动态损失缩放的稳定性,而 EVA-02-CLIP-E+ 则是需要 bf16。
训练数据集是 Merged-2B,合并了来自 LAION-2B 的 1.6 billion 样本和来自 COCO-700M 的 0.4 billion 样本。
- 模型对比

- 消融实验
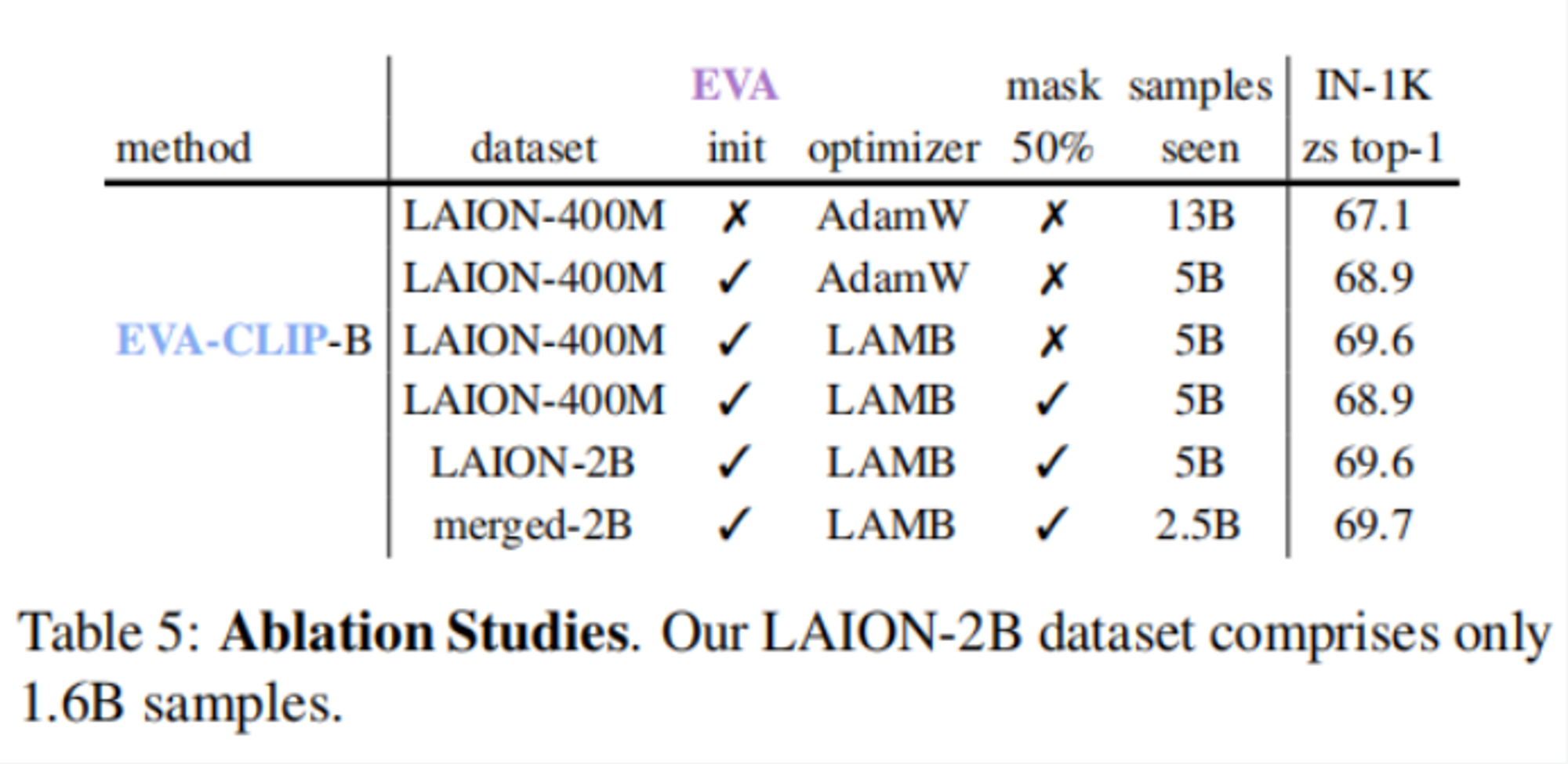
视觉编码器是 ViT-B/16,文本编码器是 CLIP-B-16。batch size 设置为 32k,评估模型在 ImageNet-1K 验证集上的 zero-shot 准确率。
前两行对比,用 EVA 初始化的模型,即使在数据量减少了将近一半的情况下,准确率依然提升了 1.8%。
二三行对比,LAMB 优化器带来了 0.7% 的提升。
三四行对比,随机 Mask 掉 50% 的 tokens,准确率又下降了 0.7%,但是训练速度加快了 1 倍。
五六行对比,merged-2B 在只见过 LAION-2B 一半样本的情况下,准确率还能提升 0.1%。
- 计算成本
Flash Attention 可以节省将近 15% 的时间。
直接 Mask 掉 50% 的tokens 可以节省将近 50% 的时间。

Code
参考资料
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【电力电子】Cuk仿真电路
- Electron窗口绑定父窗口后center()不生效的解决方案
- Linux内核--网络协议栈(五)TCP IP栈的实现原理与具体过程
- [密码学]ECC加密
- 张驰咨询:软件开发必学——用六西格玛设计(DFSS)让产品零缺陷
- C++初阶类与对象(一):学习类与对象、访问限定符、封装、this指针
- js基础知识、变量、命名规则、基本数据类型、转换类型、运算、优先级
- Liunx JBK、Python安装和SSH免密登陆
- 乳糖不耐受人群,多喝牛奶,反而降低糖尿病风险?
- Prompt Engineering 可能会是 2024 年最热门的“编程语言”?