Python中可迭代对象、迭代器详解
在Python中,有这两个概念容易让人混淆。第一个是可迭代对象(Iterable),第二个是迭代器(Iterator),第三个是生成器(Generator),这里暂且不谈生成器。

可迭代对象
列表、元组、字符串、字典等都是可迭代对象,可以使用for循环遍历出所有元素的都可以称为可迭代对象(Iterable)。在Python的内置数据结构中定义了Iterable这个类,在collections.abc模块中,我们可以用这个来检测是否为可迭代对象。
>>>?from?collections?import?Iterable >>>?a?=?[1,2,3] >>>?isinstance(a,?Iterable) >>>?True >>>?b?=?'abcd' >>>?isinstance(b,?Iterable) >>>?True
这些数据结构之所以能称之为Iterable,是因为其内部实现了__iter__()方法,从而可迭代。当我们使用for循环时,解释器会调用内置的iter()函数,调用前首先会检查对象是否实现了__iter__()方法,如果有就调用它获取一个迭代器(接下来会讲)。加入没有__iter__()方法,但是实现了__getitem__()方法,解释器会创建一个迭代器并且按顺序获取元素。如果这两个方法都没有找到,就会抛出TypeError异常。下面我们自定义对象,分别实现这两个方法(getitem(), iter())
class?MyObj: ????def?__init__(self,?iterable): ????????self._iterable?=?list(iterable) ????def?__getitem__(self,?item): ????????return?self._iterable[item] obj?=?MyObj([1,2,3]) for?i?in?obj: ????print(i)
如上所示,这里没有实现__iter__方法,只实现了__getitem__方法,也使得Myobj称为可迭代对象。
下面我们实现__iter__方法,这里使用了yield语法用来产出值(这里需要生成器的知识)
class?MyObj: ????def?__init__(self,?iterable): ????????self._iterable?=?list(iterable) ????def?__iter__(self): ????????index?=?0 ????????while?True: ????????????try: ????????????????yield?self._iterable[index] ????????????except?IndexError: ????????????????break ????????????index?+=?1 obj?=?MyObj([1,2,3]) for?i?in?obj: ????print(i)
这里同样让对象称为可迭代对象。
迭代器
迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
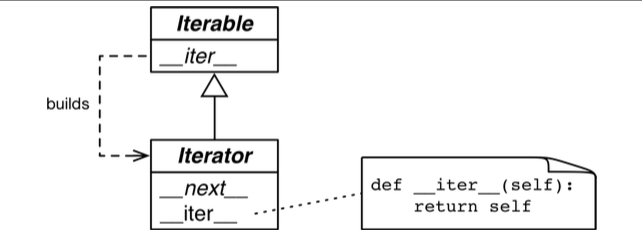
如上图所示,迭代器(Iterator)继承可迭代(Iterable),迭代器必须实现__iter__方法和__next__方法。其中__next__方法用于产出下一个元素。
由继承图可见,迭代器一定是可迭代对象,可迭代对象不一定是迭代器。
迭代器有两个基本的方法:iter() 和 next()。
我们使用iter(iterable)即可把可迭代对象转换成迭代器。
使用next(iterator)来获取迭代器的下一个值。
>>>?a?=?[3,4,5] >>>?a >>>?[3,?4,?5] >>>?iter(a) >>>?<list_iterator?object?at?0x10b130ba8> >>>?iterator?=?iter(a) >>>?next(iterator) >>>?3 >>>?next(iterator) >>>?4 >>>?next(iterator) >>>?5 >>>?next(iterator) Traceback?(most?recent?call?last): ??File?"<input>",?line?1,?in?<module> StopIteration
如上所示,因为对象实现了__next__方法,我们可以通过next(iterator)来获取迭代器的下一个值,直到没有值了,抛出StopIteration异常结束。
迭代器的背后
迭代器Iterator是一个抽象基类,它定义在_collections_abc.py中
Iterator源码如下
class?Iterator(Iterable): ????__slots__?=?() ????@abstractmethod ????def?__next__(self): ????????'Return?the?next?item?from?the?iterator.?When?exhausted,?raise?StopIteration' ????????raise?StopIteration ????def?__iter__(self): ????????return?self ????@classmethod ????def?__subclasshook__(cls,?C): ????????if?cls?is?Iterator: ????????????return?_check_methods(C,?'__iter__',?'__next__') ????????return?NotImplemented
可以看到,它实现了__subclasshook__方法,即不用显式继承Iterator,只需要实现__iter__和__next__方法即可称为Iterator的虚拟子类。这里凸现了Python的鸭子类型,实现特定的“协议”即可拥有某种行为。
另外,它自己也定义了__iter__方法,当我们使用iter(Iterator)时直接返回自己,不做任何处理。
iter()函数的两个用法
官方文档中给出了说明:
????iter(iterable)?->?iterator ????iter(callable,?sentinel)?->?iterator ???? ????Get?an?iterator?from?an?object.??In?the?first?form,?the?argument?must ????supply?its?own?iterator,?or?be?a?sequence. ????In?the?second?form,?the?callable?is?called?until?it?returns?the?sentinel.
第一个用法:iter(iterable) -> iterator (把可迭代对象转换为迭代器)
第二个用法:iter(callable, sentinel) -> iterator (第一个参数:任何可调用对象,可以是函数,第二个是标记值,当可调用对象返回这个值时,迭代器抛出StopIteration异常,而不产出标记值)
>>>?from?random?import?choice >>>?values?=?[1,2,3,4,5,6,7] >>>?def?test_iter(): >>>?????return?choice(values) >>>?it?=?iter(test_iter,?2) >>>?it >>>?<callable_iterator?object?at?0x10b130b00> >>>?for?i?in?it: >>>?????print(i) >>>?7 >>>?1 >>>?7 >>>?3 >>>?1
上面代码的流程:test_iter函数从values列表中随机挑选一个值并返回,调用iter(callable, sentinel)函数,把sentinel标记值设置为2,返回一个callable_iterator实例,遍历这个特殊的迭代器,如果函数返回标记值2,直接抛出异常退出程序。这就是iter函数的鲜为人知的另一个用法。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 实战纪实 | 某配送平台zabbix 未授权访问 + 弱口令
- C# WPF上位机开发(闪退问题的处理)
- 线性代数笔记6 1.6
- SpringCloud02
- SpringMVC之拦截器和异常处理器
- Python爬虫基础篇1
- 【pytorch】Pytorch 中的 grid 与 各种变换
- 11、基于LunarLander登陆器的A2C强化学习(含PYTHON工程)
- 洛谷——P1983 [NOIP2013 普及组] 车站分级(拓扑排序、c++)
- 简易实现 STL--list