NLP技术在搜索推荐场景中的应用
NLP技术在搜索推荐中的应用非常广泛,例如在搜索广告的CTR预估模型中,NLP技术可以从语义角度提取一些对CTR预测有效的信息;在搜索场景中,也经常需要使用NLP技术确定展现的物料与搜索query的相关性,过滤掉相关性较差的物料,防止对用户体验造成负面影响。在推荐场景中,文本信息也可以作为一种泛化性较强的信息补充,弥补协同过滤信号的稀疏性问题,提升预测效果。
今天这篇文章梳理了NLP技术在搜索推荐场景中3个方面的应用,分别是NLP提升CTR预估效果、NLP解决搜索场景相关性问题、NLP信息优化基于推荐系统效果。
1 NLP特征提升CTR预估效果
Learning Supplementary NLP Features for CTR Prediction in Sponsored Search(KDD 2022)是微软必应团队在近年KDD上发表的一篇工作,主要介绍了如何利用NLP特征提升CTR预估的效果。这篇工作的应用场景是必应的搜索广告,需要对给定搜索词下不同的广告document进行CTR预测,并根据预测的CTR进行排序。
业内一般使用NLP特征的方法是,使用预训练的BERT模型,给当前query和document对进行相关性打分,将这个打分作为一维特征输入到CTR预估模型中。然而文中指出,这种应用NLP特征的方法并不是最优的。本文提出了一种BERT和CTR预估模型联合训练的方式,让BERT提取的语义特征和CTR预估任务更加契合。
基础的模型结构如下图,左侧是位置特征和CTR预估的其他特征(如user、context特征等),右侧是语义特征,使用预训练的BERT,以query和ad文本作为输入,得到query和ad匹配的向量。CTR预估的向量和BERT生成的向量相加后,作为最终表示进行CTR预测。
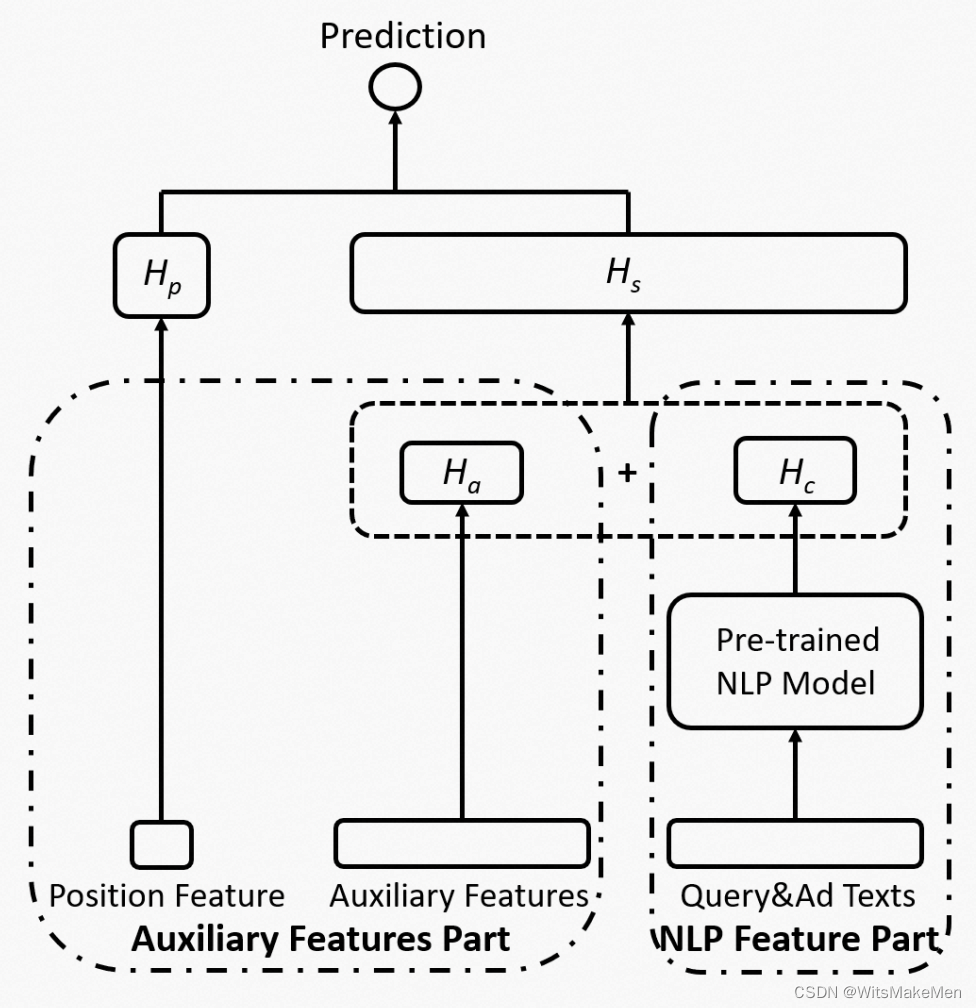
由于BERT模型的参数量很大,网络层数很深,而CTR预估模型的网络层数比较浅。这两个模型直接一起优化会比较困难。因此文中采用了两阶段的训练方法。在第一阶段,先分别独立的使用CTR预估的label训练不带语义特征的CTR预估模型,以及预训练的BERT模型,这一步得到了初始化参数。在第二阶段,将两个网络融合到一起学习,同时更新所有网络的参数。
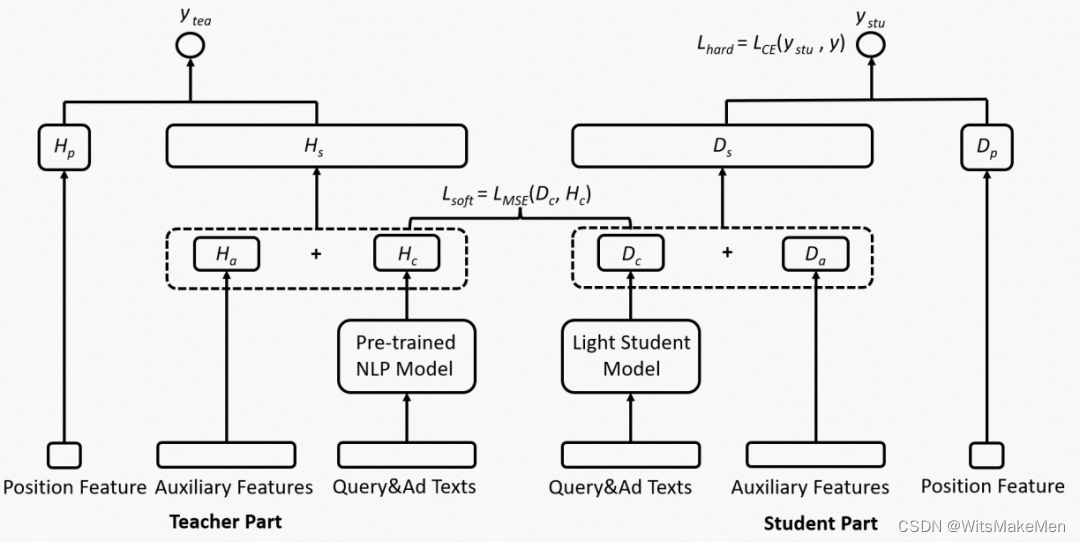
由于BERT网络参数量大,计算比较慢,文中还采用了一种蒸馏的策略压缩BERT模型的体积。Teacher部分是原始的BERT+CTR模型,Student部分将BERT改为一个轻量级的语义模型,使用正则化约束轻量级语义模型和原始BERT输出的向量表示相接近,让Student网络蒸馏主模型的知识。
2 NLP解决搜索场景相关性问题
NLP在搜索场景或电商场景的一大应用,就是解决相关性问题。相关性和CTR预估问题存在比较大的差异,相关性是影响CTR的一个因素,CTR还受到user、展现创意质量等多种因素的影响。相比而言,相关性更加客观的衡量了搜索词和展现商品是否匹配。因此,业内一般会将相关性建模和CTR建模分开考虑,而NLP技术对于解决相关性问题至关重要。
BERT2DNN: BERT Distillation with Massive Unlabeled Data for Online E-Commerce Search(ICDM 2020)是京东和清华大学发表的一篇解决电商场景相关性问题的工作。下图对比了本文提出的方法和业内其他基础方法的差异。
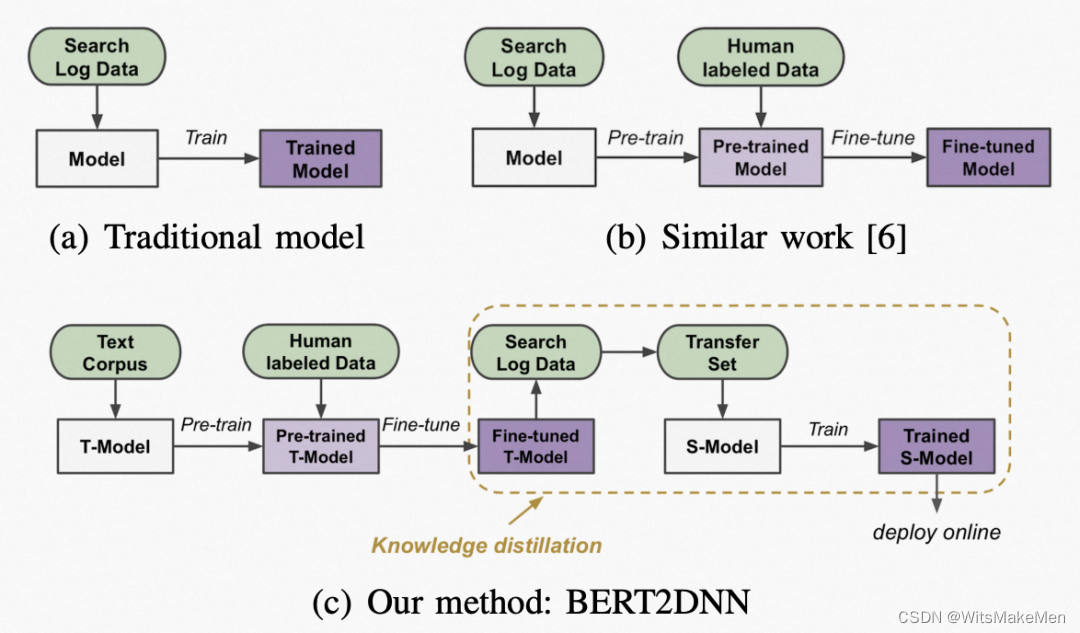
解决相关性问题,数据来源有两个方面,一方面是根据用户的搜索和点击行为构造数据,例如query-item发生点击就认为是相关的。这种数据标注成本很低,数据量也很大,但是并不代表真正的相关性,存在一定的噪声。另一种类型的数据是人工标注的相关性数据,这类数据由于需要人工标注,比较精准,噪声小,但是标注成本较高,往往不会积累很多数据。A unified neural network approach to e-commerce relevance learning(2019)这篇解决相关性问题的文章中,使用了先在用户行为数据上预训练,再使用人工标注的高质量数据finetune的架构构建相关性模型。
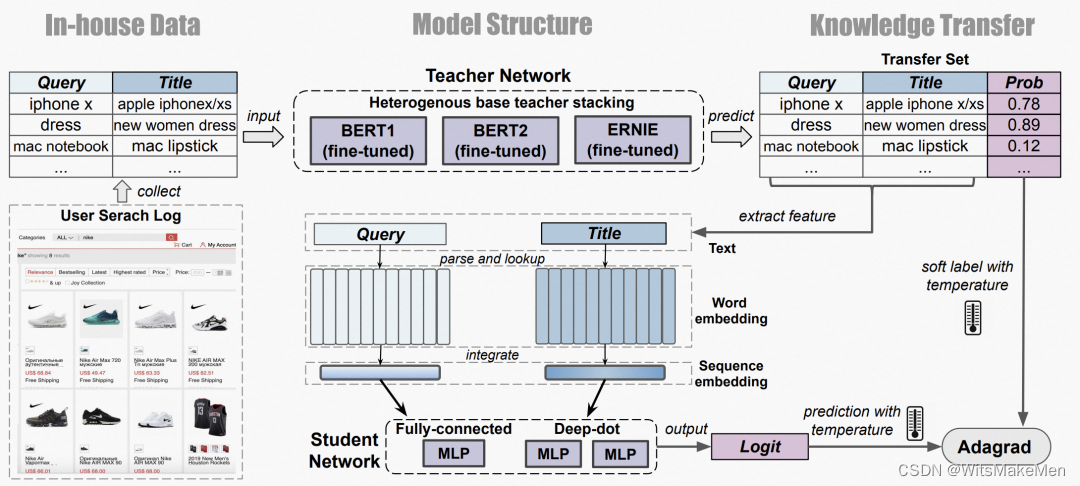
本文提出的BERTDNN方法,优化点主要体现在对BERT的蒸馏以及模型训练流程上。模型主体结构采用BERT,输入query和item文本信息,预测打分结果。首先在干净的相关性语料数据以及人工标注的高质量数据上训练BERT模型,然后利用这个模型对搜索日志中的用户行为数据打分,得到大量的包含相关性打分的数据。接下来使用一个DNN模型拟合这个打分,将BERT中的知识蒸馏到DNN模型中。DNN模型的结构可以采用query和item的embedding在底层直接交叉的双单塔结构,或者分别交叉的双塔结构。DNN模型大大降低了运行开销,作为线上最终部署的模型。
3 NLP优化推荐系统效果
在推荐系统中,一般根据user对item的打分结果学习user和item的表示向量,然后利用向量检索进行推荐。然而,协同过滤信号存在稀疏性,容易影响模型效果。而user的填写的评价、item的描述等文本信息,在协同过滤信号的基础上提供了高泛化性特征,对于提升推荐效果很有帮助。
Gated Attentive-Autoencoder for Content-Aware Recommendation(WSDM 2019)就采用了item content表示与user-item打分关系的表示相融合的方式提升效果。文中利用user-item打分学习一个embedding,同时利用item的内容信息结合attention模块学习一个文本表示信息,然后使用一个门结构对两侧的信息进行融合。此外,本文还是用了item的邻居信息结合attention来丰富中心节点表示。
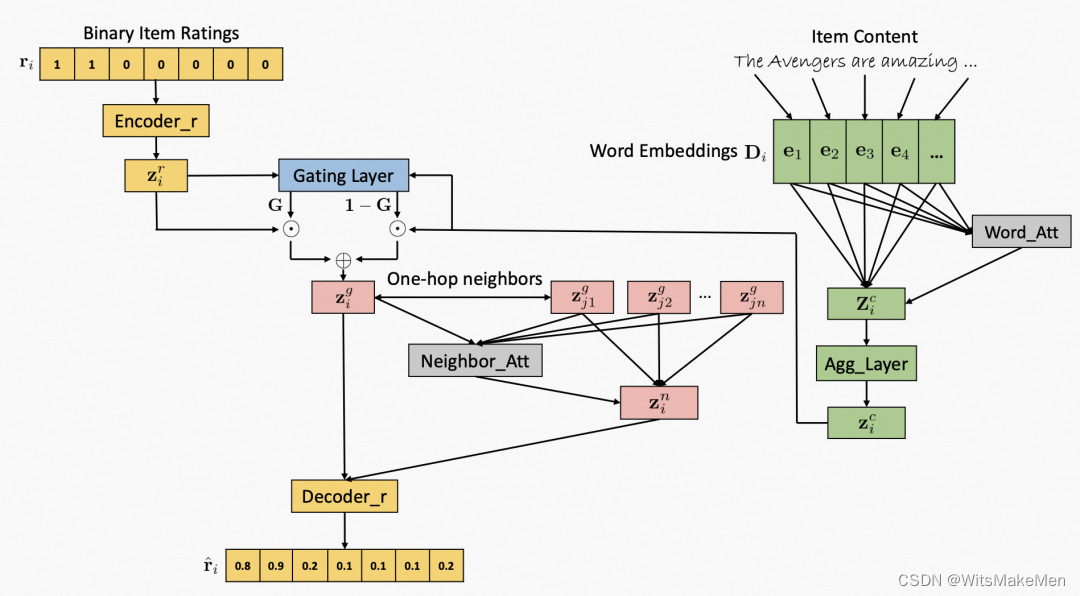
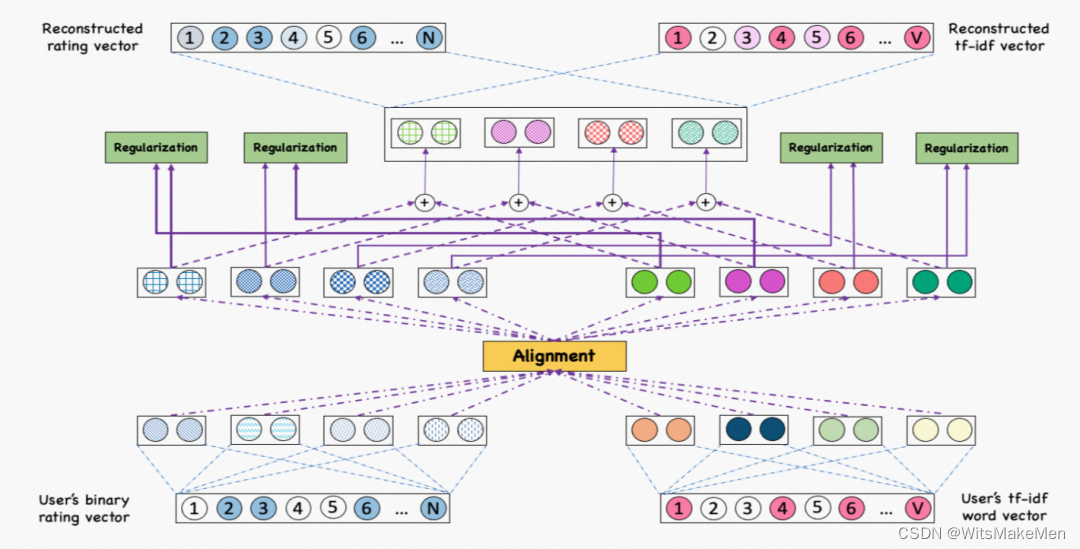
另一篇文章Aligning Dual Disentangled User Representations from Ratings and Textual Content(KDD 2022)也采用了类似的方法。本文为了刻画user与item之间发生交互行为的底层因素,采用了分解学习的方法,根据user-item的打分信息以及user的评论信息分别学习两个表示,然后在分解学习得到多个因素后,在因素这个维度进行两个表示的对齐。
4 总结
本文主要介绍了NLP技术在搜索推荐场景中的应用。在搜索推荐中,文本信息是很常见的一种信息来源,因此如何利用文本信息提升CTR预估、推荐等模型效果,以及如何利用NLP技术解决相关性问题,都是搜推广场景中很有价值的研究点。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 创建Vue3工程
- 中国品牌崛起,爱可声助听器在欧美市场崭露头角
- 一个很好用且开源的java验证码框架kaptcha
- 计算机网络-期末不挂科-第一章-概述
- C语言通过MSXML6.0读写XML文件(同时支持char[]和wchar_t[]字符数组)
- 小红书多模态团队建立新「扩散模型」:解码脑电波,高清还原人眼所见
- 操作系统【设备管理】
- 关于各种浏览器或操作系统深色模式的设置,看这篇文章就够了
- 【免费送书】Java从入门到精通:轻松领会Java程序开发的精髓
- 【NI-RIO入门】生成、部署、调试 实时应用程序