人工智能_机器学习087_DBSCAN聚类案例_聚类数据创建---人工智能工作笔记0127
发布时间:2024年01月03日
之前我们把DBSCAN的原理以及参数都理解了,现在我们看如何使用
首先我们导包
import numpy as np 导入数学计算包
import matplotlib.pyplot as plt 导入画图包
from sklearn.cluster import KMeans,DBSCAN 导入算法
from sklearn import datasets 导入数据集包
X,y = datasets.make_circles(n_samples = 1000,noise=0.05,factor = 0.5)
可以看到 参数noise是噪声点,占比,然后n_samples=1000,我们让它生成1000个噪声点, 然后factor是内圈和外圈的占比
plt.scatter(X[:,0],X[:,1],c=y) 从X中获取第第一列做为x轴,获取第二列做为y轴,三行,颜色,就是y的值,y是0,1 也就是y有两种颜色对吧
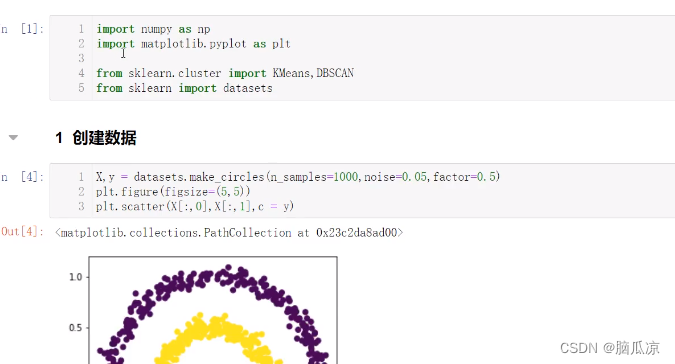
X,y = datasets.make_circles(n_samples = 1000,noise=0.05,factor = 0.5)
plt.figure(figsize=(5,5)) 设置一下画布的宽度高度
plt.scatter(X[:,0],X[:,1],c=y)
然后再去看看
文章来源:https://blog.csdn.net/lidew521/article/details/135356679
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!