用通俗易懂的方式讲解:图解 BERT 架构
之前文章我们分享了:用通俗易懂的方式讲解:图解 Transformer 架构,如果你还没有理解,可以翻阅看一下。
今天本文将从BERT的本质、BERT的原理、BERT的应用三个方面,带您一文搞懂Bidirectional Encoder Representations from Transformers | BERT。
文章目录
用通俗易懂方式讲解系列
- 用通俗易懂的方式讲解:自然语言处理初学者指南(附1000页的PPT讲解)
- 用通俗易懂的方式讲解:NLP 这样学习才是正确路线
- 用通俗易懂的方式讲解:28张图全解深度学习知识!
- 用通俗易懂的方式讲解:不用再找了,这就是 NLP 方向最全面试题库
- 用通俗易懂的方式讲解:实体关系抽取入门教程
- 用通俗易懂的方式讲解:灵魂 20 问帮你彻底搞定Transformer
- 用通俗易懂的方式讲解:图解 Transformer 架构
- 用通俗易懂的方式讲解:大模型算法面经指南(附答案)
- 用通俗易懂的方式讲解:十分钟部署清华 ChatGLM-6B,实测效果超预期
- 用通俗易懂的方式讲解:内容讲解+代码案例,轻松掌握大模型应用框架 LangChain
- 用通俗易懂的方式讲解:如何用大语言模型构建一个知识问答系统
- 用通俗易懂的方式讲解:最全的大模型 RAG 技术概览
- 用通俗易懂的方式讲解:利用 LangChain 和 Neo4j 向量索引,构建一个RAG应用程序
- 用通俗易懂的方式讲解:使用 Neo4j 和 LangChain 集成非结构化知识图增强 QA
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了NLP面试与技术交流群, 想要进交流群、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、添加微信号:mlc2060,备注:技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:技术交流

一、BERT 的本质
BERT架构: 一种基于多层Transformer编码器的预训练语言模型,通过结合Tokenization、多种Embeddings和特定任务的输出层,能够捕捉文本的双向上下文信息,并在各种自然语言处理任务中表现出色。

-
输入层 (Input)
BERT的输入是一个原始的文本序列,它可以是单个句子,也可以是两个句子(例如,问答任务中的问题和答案)。在输入到模型之前,这些文本需要经过特定的预处理步骤。
-
Tokenization 和 Embeddings
Tokenization: 输入文本首先通过分词器(Tokenizer)被分割成Token。这一步通常包括将文本转换为小写、去除标点符号、分词等。BERT使用WordPiece分词方法,将单词进一步拆分成子词(subwords),以优化词汇表的大小和模型的泛化能力。
Token Embeddings: 分词后的Token被映射到一个高维空间,形成Token Embeddings。这是通过查找一个预训练的嵌入矩阵来实现的,该矩阵为每个Token提供一个固定大小的向量表示。
Segment Embeddings: 由于BERT能够处理两个句子作为输入(例如,在句子对分类任务中),因此需要一种方法来区分两个句子。Segment Embeddings用于此目的,为每个Token添加一个额外的嵌入,以指示它属于哪个句子(通常是“A”或“B”)。
Position Embeddings: 由于Transformer模型本身不具有处理序列中Token位置信息的能力,因此需要位置嵌入来提供这一信息。每个位置都有一个独特的嵌入向量,这些向量在训练过程中学习得到。
Token Embeddings、Segment Embeddings和Position Embeddings三者相加,得到每个Token的最终输入嵌入。
-
BERT的网络结构 (Network Structure of BERT)
BERT的核心是由多个Transformer编码器层堆叠而成的。每个编码器层都包含自注意力机制和前馈神经网络,允许模型捕捉输入序列中的复杂依赖关系。
-
自注意力机制: 允许模型在处理序列时关注不同位置的Token,并计算Token之间的注意力权重,从而捕捉输入序列中的依赖关系。
-
前馈神经网络: 对自注意力机制的输出进行进一步转换,以提取更高级别的特征。
-
残差连接和层归一化: 用于提高模型的训练稳定性和效果,有助于缓解梯度消失和梯度爆炸问题。
-
输出层 (Output)
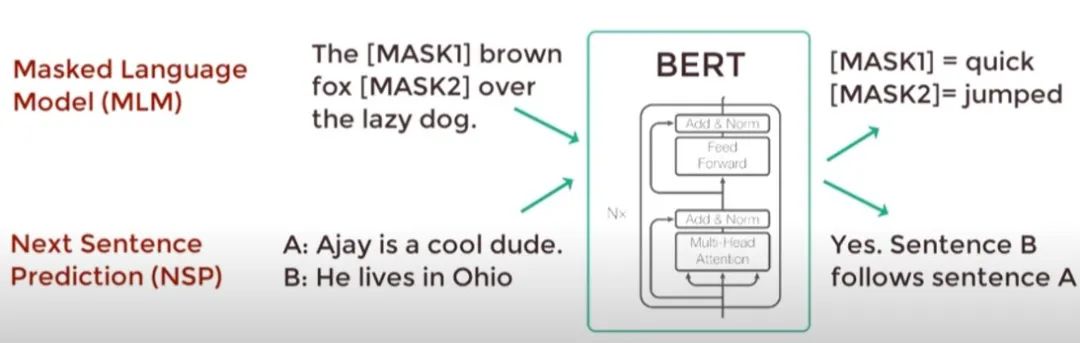
BERT的输出取决于特定的任务。在预训练阶段,BERT采用了两种任务:Masked Language Model(MLM)和Next Sentence Prediction(NSP)。
-
MLM: 在这种任务中,BERT预测输入序列中被随机遮盖的Token。模型的输出是每个被遮盖Token的概率分布,通过Softmax层得到。
-
NSP: 这种任务要求BERT预测两个句子是否是连续的。模型的输出是一个二分类问题的概率分布。
BERT模型的输入:通过结合Token Embeddings、Segment Embeddings和Position Embeddings三种嵌入方式,BERT等模型能够全面捕获文本的语义和上下文信息,为各类自然语言处理任务提供强大的基础表示能力。
-
Token Embeddings
-
在BERT中,输入文本首先被分割成Token序列(单词、子词等),每个Token都会被映射到一个高维向量空间,形成Token Embeddings。这些嵌入捕获了Token的语义信息,是模型理解文本的基础。
-
Token Embeddings是通过在大规模语料库上进行无监督预训练得到的,这使得BERT能够理解和处理各种复杂的语言现象和语义关系。

Token Embeddings
-
Segment Embeddings:
-
为了处理像问答这样的任务,BERT引入了Segment Embeddings来区分两个不同但相关的句子(例如问题和答案)。这些嵌入帮助模型理解句子间的关系和边界。
-
在文本分类任务中,Segment Embeddings的作用可能不那么明显,因为输入通常是一个连续的文本段落。然而,它们仍然可以用于区分不同部分的文本,特别是在处理长文档或多个句子时。

Segment Embeddings
-
Position Embeddings:
-
由于Transformer结构本身不具备处理序列顺序的能力,BERT引入了Position Embeddings来捕获文本中Token的位置信息。
-
这些嵌入确保模型能够区分不同位置的相同Token,例如区分“hello,world”和“world,hello”中的“hello”和“world”。

Position Embeddings
Position Embeddings与Token Embeddings和Segment Embeddings相加,形成最终的输入嵌入,这些嵌入随后被送入Transformer编码器进行处理。
二、BERT 的原理
BERT的工作原理是通过在大规模未标注数据上执行预训练任务(如Masked Language Model来捕获文本中词汇的双向上下文关系,以及Next Sentence Prediction来理解句子间的逻辑关系),再将预训练的模型针对特定任务进行Fine tuning,从而在各种自然语言处理任务中实现高性能。

BERT工作原理
模型的预训练任务:在大量未标注数据上进行自我学习的过程,通过这些任务,模型能够学习到语言的内在规律和模式,从而为其在后续的具体任务(如文本分类、问答等)中提供有力的支持。以下是两个核心的预训练任务:
无监督预训练
-
Masked Language Model (MLM)
-
任务描述:在输入的文本中,随机地遮盖或替换一部分词汇,并要求模型预测这些被遮盖或替换的词汇的原始内容。
-
目的:使模型能够利用双向的上下文信息来预测被遮盖的词汇,从而学习到更深层次的语义表示。
-
实现方式:在预训练阶段,BERT随机选择文本中15%的Token进行遮盖,其中80%的时间用[MASK]标记替换,10%的时间用随机词汇替换,剩下的10%保持不变。这种遮盖策略被称为动态遮盖,因为它在每次输入时都会随机改变遮盖的位置和词汇。

Masked Language Model (MLM)
-
Next Sentence Prediction (NSP)
-
任务描述:给定一对句子,判断第二个句子是否是第一个句子的后续句子。
-
目的:使模型能够理解句子间的逻辑关系,如连贯性、因果关系等,从而提高其在处理长文档或复杂文本时的能力。
-
实现方式:在预训练阶段,BERT构造了一个二分类任务,其中50%的时间B是A的真正后续句子(标签为“IsNext”),另外50%的时间B是从语料库中随机选择的句子(标签为“NotNext”)。模型通过最后一层Transformer输出的[CLS]标记的嵌入来进行预测。

Next Sentence Prediction (NSP)
模型Fine tuning:BERT的fine-tuning过程是针对特定任务对预训练模型进行调整的过程,使其能够更好地适应和解决具体任务。根据任务类型的不同,对BERT模型的修改也会有所不同,但通常这些修改都相对简单,往往只需要在模型的输出部分加上一层或多层神经网络。

模型Fine tuning
-
任务类型:根据具体任务的不同,BERT的fine-tuning可以分为以下几种类型:
-
句子对分类任务(Sentence Pair Classification):这种任务需要判断两个句子之间的关系,如文本蕴含、问答匹配等。在fine-tuning时,将两个句子一起输入模型,并取第一个token([CLS])的输出表示作为整个句子对的表示,然后将其输入到一个额外的softmax层进行分类。
-
单句分类任务(Single Sentence Classification):这种任务需要对单个句子进行分类,如情感分析、文本分类等。在fine-tuning时,将单个句子输入模型,并同样取第一个token([CLS])的输出表示进行分类。
-
问答任务(Question Answering):这种任务需要模型从给定的文本中找出问题的答案。在fine-tuning时,将问题和答案一起输入模型,并取答案部分在模型输出中的起始和结束位置作为答案的预测。
-
序列标注任务(Sequence Tagging,如命名实体识别NER):这种任务需要对输入序列中的每个token进行分类,如识别文本中的实体、词性标注等。在fine-tuning时,取所有token在最后一层Transformer的输出,然后将其输入到一个额外的softmax层进行逐token的分类。
-
模型修改:在进行fine-tuning时,对BERT模型的修改通常包括以下几个方面:
-
输入处理:根据任务类型的不同,对输入数据进行相应的处理,如将句子对拼接在一起、添加特殊标记等。
-
输出层:在BERT模型的输出部分添加一层或多层神经网络,用于将模型的输出转换为任务所需的格式。对于分类任务,通常添加一个softmax层进行概率分布的计算;对于序列标注任务,则逐token进行分类。
-
损失函数:根据任务类型选择合适的损失函数,如交叉熵损失函数用于分类任务、平方差损失函数用于回归任务等。
三、BERT的应用
Question Answer(QA,问答系统):BERT在问答系统(QA)中的应用通常涉及两个阶段:检索阶段和问答判断阶段。

-
一、检索阶段
-
文档处理:
-
切割:将长文档切割成较短的段落或句子(Passage),这些片段更容易处理和索引。
-
建立索引:利用倒排索引技术,为每个切割后的片段(Passage)建立索引,以便快速查询。
-
检索模型:
-
BM25模型:使用BM25或类似的检索函数(如BM25+RM3)计算问句与每个候选段落或句子的相关性得分。
-
候选选择:根据得分选择Top K个最相关的候选段落或句子。
-
二、问答判断阶段
-
模型准备:
-
Fine-tuning数据:选择适当的问答数据集(如SQuAD)或任务数据进行BERT模型的fine-tuning。
-
模型结构:在BERT模型的基础上,添加必要的输出层以适应问答任务,如分类层或起始/终止位置预测层。
-
问答处理:
-
输入构建:将用户问句和每个候选段落或句子组合成BERT模型的输入格式。
-
模型预测:使用fine-tuned BERT模型对每个输入进行预测,判断候选段落或句子是否包含正确答案,或者预测答案的精确位置。
-
答案选择:
-
评分机制:根据BERT模型的预测结果,为每个候选段落或句子分配得分。
-
最终答案:选择得分最高的候选段落或句子作为最终答案。
聊天机器人:BERT在聊天机器人中的应用主要涉及两个方面:用户意图分类和槽位填充(对于单轮对话),以及多轮对话中的上下文信息利用。

聊天机器人
-
一、BERT在单轮对话中的应用
-
用户意图分类:
-
输入:将用户的话语作为BERT模型的输入。
-
模型结构:在BERT模型的基础上添加分类层,用于将用户意图分类到不同的服务类型中。
-
训练:使用带有意图标签的用户话语数据集进行fine-tuning,使模型能够准确识别用户意图。
-
任务描述:从用户的话语中解析出用户的意图,如订餐、点歌等。
-
BERT应用:
-
槽位填充:
-
输入:将用户的话语以及预定义的槽位作为BERT模型的输入。
-
模型结构:采用序列标注的方式,对每个输入token进行槽位标签的预测。
-
训练:使用带有槽位标签的用户话语数据集进行fine-tuning,使模型能够准确填充槽位信息。
-
任务描述:根据用户意图抽取关键元素,如订机票时的出发地、目的地等。
-
BERT应用:
-
二、BERT在多轮对话中的应用
-
上下文信息利用:
-
输入:将当前用户话语以及历史对话内容作为BERT模型的输入。
-
模型结构:可以采用多种策略来融入历史信息,如将历史对话与当前用户话语拼接、使用历史对话的嵌入表示等。
-
训练:使用多轮对话数据集进行fine-tuning,使模型能够正确理解和利用上下文信息来生成应答。
-
任务描述:在多轮对话中,利用历史交互信息来改进模型的应答。
-
BERT应用:
-
模型改进:
-
增加模型容量:通过增加BERT模型的层数或隐藏单元数来捕捉更多的上下文信息。
-
引入注意力机制:使用注意力机制来加权历史信息的重要性,使模型能够关注与当前应答最相关的部分。
-
记忆网络:结合记忆网络来存储和检索历史信息,以便在需要时提供给模型进行应答生成。
-
关键问题:如何有效融入更多的历史信息,并在上下文中正确地使用这些信息。
-
改进策略
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 9.建造者模式
- mysql第五次作业
- Oracle:JDBC链接Oracle的DEMO
- 实时渲染 -- 光栅化(Rasterization)
- 【信号与系统】【北京航空航天大学】实验三、连续时间信号的频域分析 【MATLAB】
- 贪吃蛇(五)蛇撞墙
- 第05章_数组(一维数组的使用、内存分析、应用,多维数组的使用,数组的常见算法,Arrays工具类的使用,数组中的常见异常)
- 杜卡迪Panigale v4 SP2、Street Fighter v4 SP正式发布,购车送GP观赛
- 旅游平台网页前后端
- [ACM学习] 动态规划基础之一二三维dp