学习k8s
学习k8s
我为什么要用k8s 和其他部署方式的区别是什么?
-
传统部署方式
java --> package --> 放到服务器上 --> Tomcat
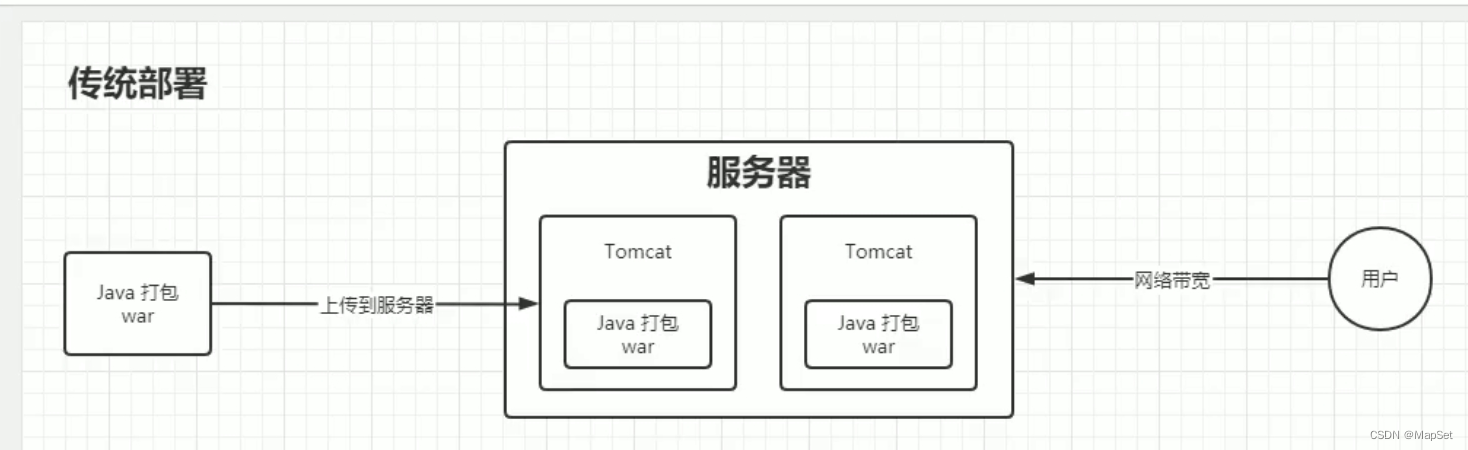
如果是同时进行写操作,会存在并发问题.
用户 --网络带宽–> 服务器 -->服务
同一个服务器上,多个服务:
网络资源的占用
内存的占用
cpu的占用
…
资源争抢
复杂度可以通过脚本来解决.
-
虚拟化部署/隔离机制/占用资源过多
java --> package --xx.jar–> linux服务器(虚机[Tomcat < xx.jar文件 >])
带来了,资源占用过度问题
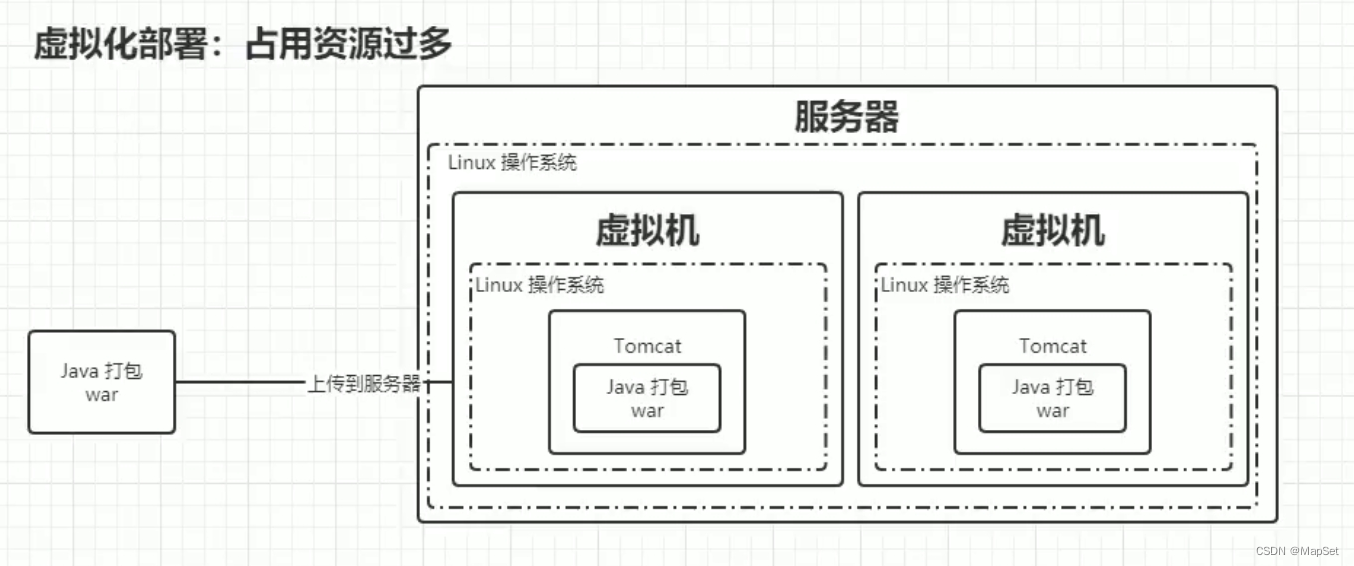
虚机的启动是分钟级别
-
容器化部署
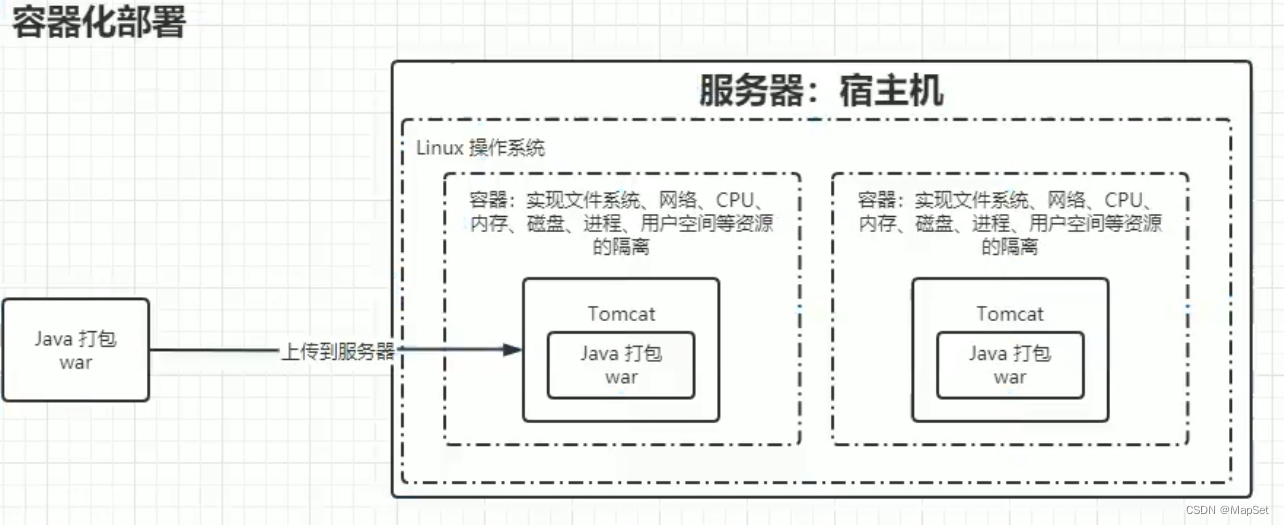
容器的启动是 秒级别的.
k8s的特点?为什么选择k8s?
-
为了解决以上问题,需要什么?
自我修复
弹性伸缩
自动部署和回滚
服务发现和负载均衡
机密和配置管理
存储编排
批处理
-
企业级服务调度平台有哪些?
- Apache Mesos
概念: 资源管理器,把所有的资源管理,调度,主从模式,zookeeper给主节点提供服务注册,服务发现功能,通过Framework Marathon 提供容器调度能力.
优势: 发布时间早,5w+节点控制,大规模节点的管理.
缺点: 面向节点,而不是容器
- Docker Swarm
概念: 标准版的Docker API
优势: 和Docker是集成的.
缺点: 已经弃用了.没人用.
- Google Kubernetes(一家独大)
概念: 使用Label和Pod的概念来将容器分为逻辑单元.Pods是同步地写作(co-located)容器的集合. 这是kubernetes 和其他两个框架哎的主要区别.简化了管理.
优势: 通过pods这一抽象的概念,解决了Container之间的依赖于通信问题,Pods,Services, Deployment 是独立部署的部分,可以通过 Selector 提供更多的灵活性,内置服务注册表和负载均衡.
缺点: 相比于 Apache Mesos 管理节点规模小
学习K8s
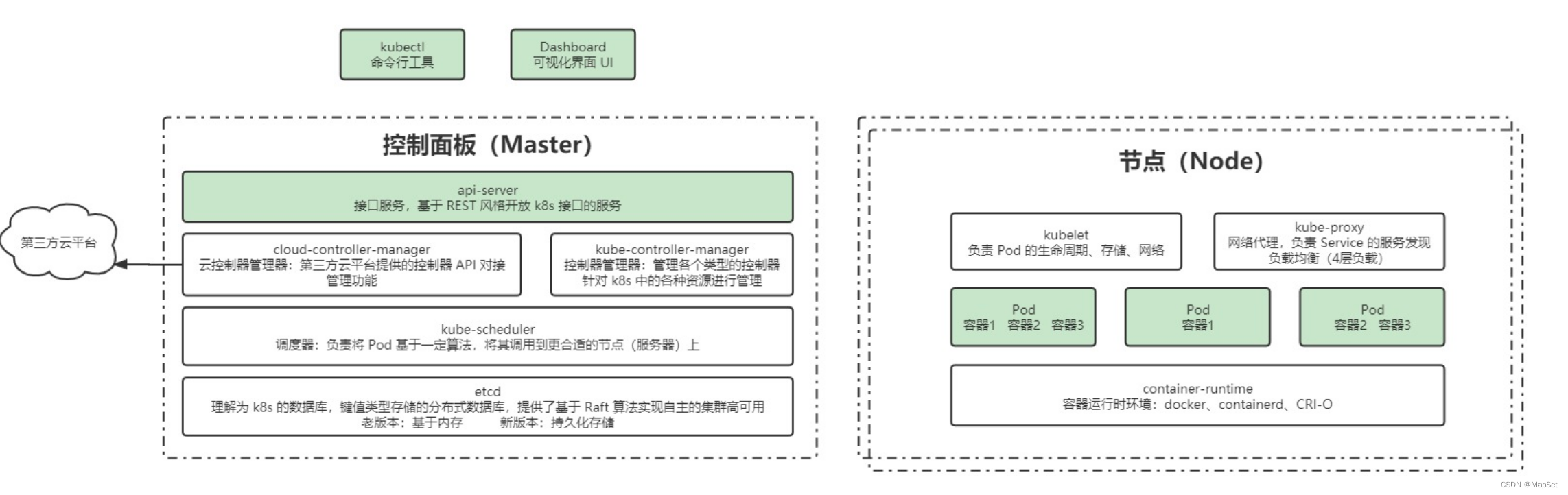
集群架构和组件
相关组件
控制面板组件(Master)
-
kube-apiserver
接口服务,REST风格,k8s接口服务
-
kube-controller-manager
控制器管理器: 管理各个类型的控制器,管理k8s的各个资源
-
cloud-controller-manager
云控制器管理器: 第三方云平台提供的控制器API对接管理平台
-
kube-scheduler
调度器: 负责将pod给予一定算法,将其调用到合适的节点(Node)上
-
etcd
-
k8s的数据库,键值对,分布式数据库,基于Raft算法,
老版本: 基于内存
新版本: 持久化存储
节点组件(Node)一般是多个Nodes
-
kubelet
负责容器的生命周期
负责Volume(CVI)挂载,存储
网络(CNI)管理
-
kube-proxy
网络代理,负责Service的服务发现,负载均衡(4层负载)
-
container-runtime
负责镜像管理已经Pod和容器的真正运行(CRI容器运行环境接口)
docker,containerd,CRI-O,
附加组件
-
kube-dns
kube-dns 负责为整个集群提供 DNS 服务
-
ingress Controller
Ingress Controller 为服务提供外网入口
-
Prometheus
Prometheus 提供资源监控
-
Dashboard
Dashboard 提供 GUI
-
Federtion
Federation 提供跨可用区的集群
-
Fluentd-elasticsearch
Fluentd-elasticsearch 提供集群日志采集、存储与查询
分层架构
-
生态系统
- Kubernetes 外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS 应用、ChatOps 等
- Kubernetes 内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等
-
接口层
kubectl 命令行工具、客户端 SDK 以及集群
-
管理层
系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态 Provision 等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy 等)
-
应用层
部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS 解析等)
-
核心层
Kubernetes 最核心的功能,对外提供 API 构建高层的应用,对内提供插件式应用执行环境
核心概念与专业术语
服务的分类
-
无状态
举例: Nginx /Apache
优点: 对客户端透明,无依赖关系,可以高效实施扩容,迁移
缺点: 不能储存数据,需要额外的数据服务支撑
-
有状态
举例: Mysql/Redis
优点: 可以独立存储数据,实现数据管理
缺点: 集权环境下需要实现主从,数据同步,备份,水平扩容复杂
资源和对象
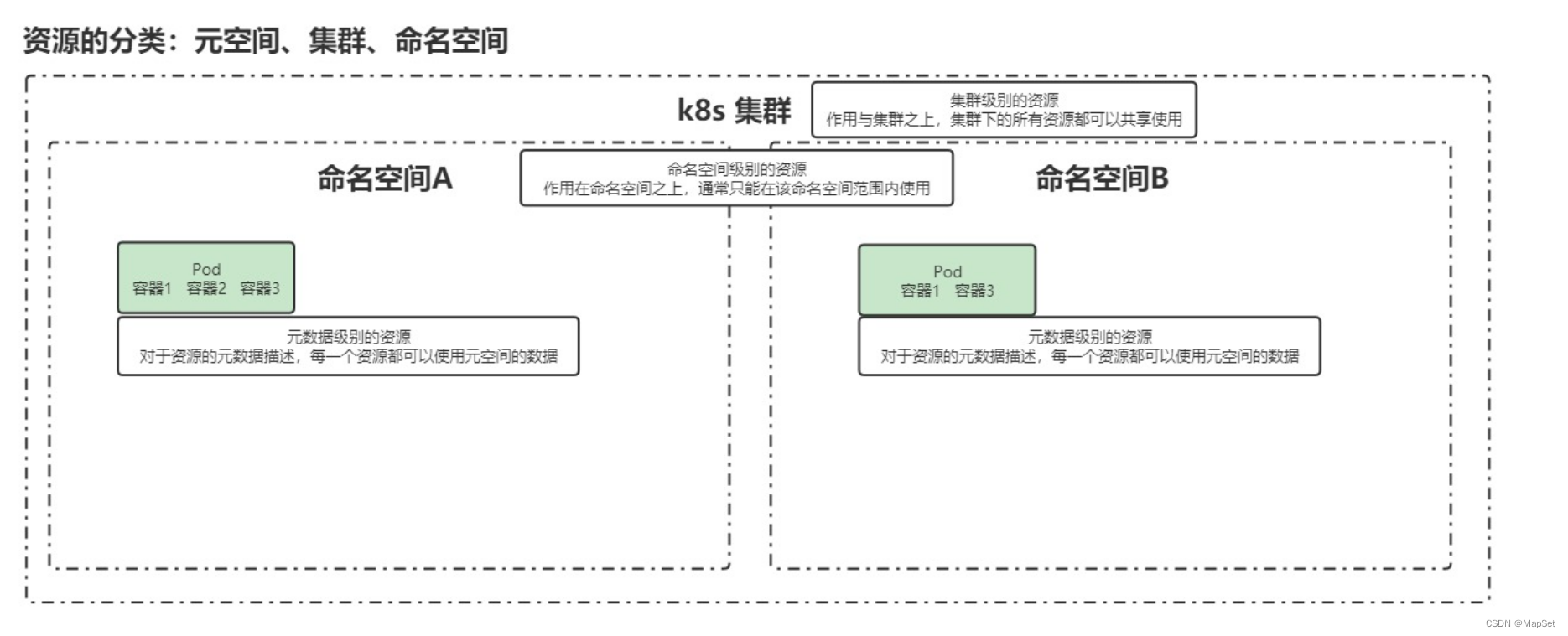
元数据型
-
Horizontal Pod Autoscaler(HPA)
Pod 自动扩容:可以根据 CPU 使用率或自定义指标(metrics)自动对 Pod 进行扩/缩容。
- 控制管理器每隔30s(可以通过–horizontal-pod-autoscaler-sync-period修改)查询metrics的资源使用情况
- 支持三种metrics类型
- 预定义metrics(比如Pod的CPU)以利用率的方式计算
- 自定义的Pod metrics,以原始值(raw value)的方式计算
- 自定义的object metrics
- 支持两种metrics查询方式:Heapster和自定义的REST API
- 支持多metrics
-
PodTemplate
Pod Template 是关于 Pod 的定义,但是被包含在其他的 Kubernetes 对象中(例如 Deployment、StatefulSet、DaemonSet 等控制器)。控制器通过 Pod Template 信息来创建 Pod。
-
LimitRange
可以对集群内 Request 和 Limits 的配置做一个全局的统一的限制,相当于批量设置了某一个范围内(某个命名空间)的 Pod 的资源使用限制。
集群级别
-
Namespace
Kubernetes 支持多个虚拟集群,它们底层依赖于同一个物理集群,这些虚拟集群被称为命名空间。
作用是用于实现多团队/环境的资源隔离。
命名空间 namespace 是 k8s 集群级别的资源,可以给不同的用户、租户、环境或项目创建对应的命名空间。
默认 namespace:
- kube-system 主要用于运行系统级资源,存放 k8s 自身的组件
- kube-public 此命名空间是自动创建的,并且可供所有用户(包括未经过身份验证的用户)读取。此命名空间主要用于集群使用,关联的一些资源在集群中是可见的并且可以公开读取。此命名空间的公共方面知识一个约定,但不是非要这么要求。
- default 未指定名称空间的资源就是 default,即你在创建pod 时如果没有指定 namespace,则会默认使用 default
-
Node
不像其他的资源(如 Pod 和 Namespace),Node 本质上不是Kubernetes 来创建的,Kubernetes 只是管理 Node 上的资源。虽然可以通过 Manifest 创建一个Node对象(如下 json 所示),但 Kubernetes 也只是去检查是否真的是有这么一个 Node,如果检查失败,也不会往上调度 Pod。
-
ClusterRole
ClusterRole 是一组权限的集合,但与 Role 不同的是,ClusterRole 可以在包括所有 Namespace 和集群级别的资源或非资源类型进行鉴权。
-
ClusterRoleBinding
ClusterRoleBinding:将 Subject 绑定到 ClusterRole,ClusterRoleBinding 将使规则在所有命名空间中生效。
命名空间级别
####### 工作负载型
对象规约和状态
微服务项目k8s环境演示
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 第1章 初识JavaScript
- 关于两大 AI 助手:ChatGPT 和文心一言哪个更好用?
- uni-app引入vant表单(附源码)
- PHP开发日志 ━━ 基于PHP和JS的AES相互加密解密方法详解(CryptoJS) 适合CryptoJS4.0和PHP8.0
- 开发服务器因弱口令导致受到木马攻击
- 批量操作软件之SaltStack简介
- 异常处理之异常抛出与异常捕获
- 平方朋友对C++
- 智能优化算法应用:基于白鲸算法3D无线传感器网络(WSN)覆盖优化 - 附代码
- 【Java系列】文件操作详解