【基于pyhton人体姿势识别实时显示】
发布时间:2024年01月17日
主要核心代码如下
功能介绍
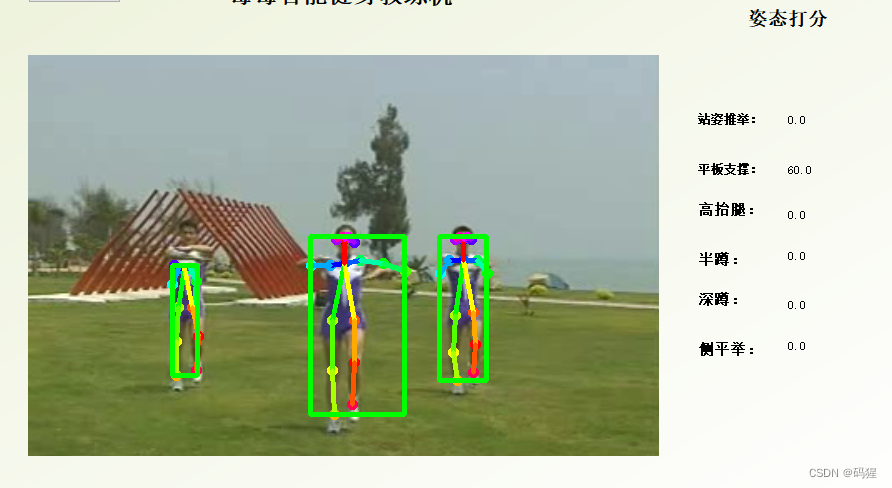
人体姿态识别项目,适合研究,容易上手,识别姿势站立,扩胸运动,踢腿,扎马步,摆手,奔跑,冲拳,下蹲,招财猫,平板支撑,侧身飞鸟,侧平举等
人体姿势识别项目
视频如上
代码如下
import numpy as np
import cv2
import argparse
if True: # Include project path
import sys
import os
ROOT = os.path.dirname(os.path.abspath(__file__))+"/../"
CURR_PATH = os.path.dirname(os.path.abspath(__file__))+"/"
sys.path.append(ROOT)
import utils.lib_images_io as lib_images_io
import utils.lib_plot as lib_plot
import utils.lib_commons as lib_commons
from utils.lib_openpose import SkeletonDetector
from utils.lib_tracker import Tracker
from utils.lib_tracker import Tracker
from utils.lib_classifier import ClassifierOnlineTest
from utils.lib_classifier import * # Import all sklearn related libraries
def par(path): # Pre-Append ROOT to the path if it's not absolute
return ROOT + path if (path and path[0] != "/") else path
# -- Command-line input
def get_command_line_arguments():
def parse_args():
parser = argparse.ArgumentParser(
description="Test action recognition on \n"
"(1) a video, (2) a folder of images, (3) or web camera.")
parser.add_argument("-m", "--model_path", required=False,
default=r'D:\pysave2023\Action-Recognition\model\trained_classifier.pickle')
parser.add_argument("-t", "--data_type", required=False, default='webcam',
choices=["video", "folder", "webcam"])
parser.add_argument("-p", "--data_path", required=False, default="",
help="path to a video file, or images folder, or webcam. \n"
"For video and folder, the path should be "
"absolute or relative to this project's root. "
"For webcam, either input an index or device name. ")
parser.add_argument("-o", "--output_folder", required=False, default='output/',
help="Which folder to save result to.")
args = parser.parse_args()
return args
args = parse_args()
if args.data_type != "webcam" and args.data_path and args.data_path[0] != "/":
# If the path is not absolute, then its relative to the ROOT.
args.data_path = ROOT + args.data_path
return args
def get_dst_folder_name(src_data_type, src_data_path):
''' Compute a output folder name based on data_type and data_path.
The final output of this script looks like this:
DST_FOLDER/folder_name/vidoe.avi
DST_FOLDER/folder_name/skeletons/XXXXX.txt
'''
assert(src_data_type in ["video", "folder", "webcam"])
if src_data_type == "video": # /root/data/video.avi --> video
folder_name = os.path.basename(src_data_path).split(".")[-2]
elif src_data_type == "folder": # /root/data/video/ --> video
folder_name = src_data_path.rstrip("/").split("/")[-1]
elif src_data_type == "webcam":
# month-day-hour-minute-seconds, e.g.: 02-26-15-51-12
folder_name = lib_commons.get_time_string()
return folder_name
args = get_command_line_arguments()
SRC_DATA_TYPE = args.data_type
SRC_DATA_PATH = args.data_path
SRC_MODEL_PATH = args.model_path
DST_FOLDER_NAME = get_dst_folder_name(SRC_DATA_TYPE, SRC_DATA_PATH)
# -- Settings
cfg_all = lib_commons.read_yaml(ROOT + "config/config.yaml")
cfg = cfg_all["s5_test.py"]
CLASSES = np.array(cfg_all["classes"])
SKELETON_FILENAME_FORMAT = cfg_all["skeleton_filename_format"]
# Action recognition: number of frames used to extract features.
WINDOW_SIZE = int(cfg_all["features"]["window_size"])
# Output folder
DST_FOLDER = args.output_folder + "/" + DST_FOLDER_NAME + "/"
DST_SKELETON_FOLDER_NAME = cfg["output"]["skeleton_folder_name"]
DST_VIDEO_NAME = cfg["output"]["video_name"]
# framerate of output video.avi
DST_VIDEO_FPS = float(cfg["output"]["video_fps"])
# Video setttings
# If data_type is webcam, set the max frame rate.
SRC_WEBCAM_MAX_FPS = float(cfg["settings"]["source"]
["webcam_max_framerate"])
# If data_type is video, set the sampling interval.
# For example, if it's 3, then the video will be read 3 times faster.
SRC_VIDEO_SAMPLE_INTERVAL = int(cfg["settings"]["source"]
["video_sample_interval"])
# Openpose settings
OPENPOSE_MODEL = cfg["settings"]["openpose"]["model"]
OPENPOSE_IMG_SIZE = cfg["settings"]["openpose"]["img_size"]
# Display settings
img_disp_desired_rows = int(cfg["settings"]["display"]["desired_rows"])
# -- Function
def select_images_loader(src_data_type, src_data_path):
if src_data_type == "video":
images_loader = lib_images_io.ReadFromVideo(
src_data_path,
sample_interval=SRC_VIDEO_SAMPLE_INTERVAL)
elif src_data_type == "folder":
images_loader = lib_images_io.ReadFromFolder(
folder_path=src_data_path)
elif src_data_type == "webcam":
if src_data_path == "":
webcam_idx = 0
elif src_data_path.isdigit():
webcam_idx = int(src_data_path)
else:
webcam_idx = src_data_path
images_loader = lib_images_io.ReadFromWebcam(
SRC_WEBCAM_MAX_FPS, webcam_idx)
return images_loader
class MultiPersonClassifier(object):
''' This is a wrapper around ClassifierOnlineTest
for recognizing actions of multiple people.
'''
def __init__(self, model_path, classes):
self.dict_id2clf = {} # human id -> classifier of this person
# Define a function for creating classifier for new people.
self._create_classifier = lambda human_id: ClassifierOnlineTest(
model_path, classes, WINDOW_SIZE, human_id)
def classify(self, dict_id2skeleton):
''' Classify the action type of each skeleton in dict_id2skeleton '''
# Clear people not in view
old_ids = set(self.dict_id2clf)
cur_ids = set(dict_id2skeleton)
humans_not_in_view = list(old_ids - cur_ids)
for human in humans_not_in_view:
del self.dict_id2clf[human]
# Predict each person's action
id2label = {}
for id, skeleton in dict_id2skeleton.items():
if id not in self.dict_id2clf: # add this new person
self.dict_id2clf[id] = self._create_classifier(id)
classifier = self.dict_id2clf[id]
id2label[id] = classifier.predict(skeleton) # predict label
# print("\n\nPredicting label for human{}".format(id))
# print(" skeleton: {}".format(skeleton))
# print(" label: {}".format(id2label[id]))
return id2label
def get_classifier(self, id):
''' Get the classifier based on the person id.
Arguments:
id {int or "min"}
'''
if len(self.dict_id2clf) == 0:
return None
if id == 'min':
id = min(self.dict_id2clf.keys())
return self.dict_id2clf[id]
def remove_skeletons_with_few_joints(skeletons):
''' Remove bad skeletons before sending to the tracker '''
good_skeletons = []
for skeleton in skeletons:
px = skeleton[2:2+13*2:2]
py = skeleton[3:2+13*2:2]
num_valid_joints = len([x for x in px if x != 0])
num_leg_joints = len([x for x in px[-6:] if x != 0])
total_size = max(py) - min(py)
# !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
# IF JOINTS ARE MISSING, TRY CHANGING THESE VALUES:
# !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
if num_valid_joints >= 5 and total_size >= 0.1 and num_leg_joints >= 0:
# add this skeleton only when all requirements are satisfied
good_skeletons.append(skeleton)
return good_skeletons
def draw_result_img(img_disp, ith_img, humans, dict_id2skeleton,
skeleton_detector, multiperson_classifier):
''' Draw skeletons, labels, and prediction scores onto image for display '''
# Resize to a proper size for display
r, c = img_disp.shape[0:2]
desired_cols = int(1.0 * c * (img_disp_desired_rows / r))
img_disp = cv2.resize(img_disp,
dsize=(desired_cols, img_disp_desired_rows))
# Draw all people's skeleton
skeleton_detector.draw(img_disp, humans)
# Draw bounding box and label of each person
if len(dict_id2skeleton):
for id, label in dict_id2label.items():
skeleton = dict_id2skeleton[id]
# scale the y data back to original
skeleton[1::2] = skeleton[1::2] / scale_h
# print("Drawing skeleton: ", dict_id2skeleton[id], "with label:", label, ".")
lib_plot.draw_action_result(img_disp, id, skeleton, label)
# Add blank to the left for displaying prediction scores of each class
img_disp = lib_plot.add_white_region_to_left_of_image(img_disp)
cv2.putText(img_disp, "Frame:" + str(ith_img),
(20, 20), fontScale=1.5, fontFace=cv2.FONT_HERSHEY_PLAIN,
color=(0, 0, 0), thickness=2)
# Draw predicting score for only 1 person
if len(dict_id2skeleton):
classifier_of_a_person = multiperson_classifier.get_classifier(
id='min')
classifier_of_a_person.draw_scores_onto_image(img_disp)
return img_disp
def get_the_skeleton_data_to_save_to_disk(dict_id2skeleton):
'''
In each image, for each skeleton, save the:
human_id, label, and the skeleton positions of length 18*2.
So the total length per row is 2+36=38
'''
skels_to_save = []
for human_id in dict_id2skeleton.keys():
label = dict_id2label[human_id]
skeleton = dict_id2skeleton[human_id]
skels_to_save.append([[human_id, label] + skeleton.tolist()])
return skels_to_save
# -- Main
if __name__ == "__main__":
# -- Detector, tracker, classifier
skeleton_detector = SkeletonDetector(OPENPOSE_MODEL, OPENPOSE_IMG_SIZE)
multiperson_tracker = Tracker()
multiperson_classifier = MultiPersonClassifier(SRC_MODEL_PATH, CLASSES)
# -- Image reader and displayer
images_loader = select_images_loader(SRC_DATA_TYPE, SRC_DATA_PATH)
img_displayer = lib_images_io.ImageDisplayer()
# -- Init output
# output folder
os.makedirs(DST_FOLDER, exist_ok=True)
os.makedirs(DST_FOLDER + DST_SKELETON_FOLDER_NAME, exist_ok=True)
# video writer
video_writer = lib_images_io.VideoWriter(
DST_FOLDER + DST_VIDEO_NAME, DST_VIDEO_FPS)
# -- Read images and process
try:
ith_img = -1
for i in range(100):
if images_loader.has_image():
# -- Read image
img = images_loader.read_image()
ith_img += 1
img_disp = img.copy()
print(f"\nProcessing {ith_img}th image ...")
# -- Detect skeletons
humans = skeleton_detector.detect(img)
skeletons, scale_h = skeleton_detector.humans_to_skels_list(humans)
skeletons = remove_skeletons_with_few_joints(skeletons)
# -- Track people
dict_id2skeleton = multiperson_tracker.track(
skeletons) # int id -> np.array() skeleton
# -- Recognize action of each person
if len(dict_id2skeleton):
dict_id2label = multiperson_classifier.classify(
dict_id2skeleton)
# -- Draw
img_disp = draw_result_img(img_disp, ith_img, humans, dict_id2skeleton,
skeleton_detector, multiperson_classifier)
# Print label of a person
if len(dict_id2skeleton):
min_id = min(dict_id2skeleton.keys())
print("prediced label is :", dict_id2label[min_id])
# -- Display image, and write to video.avi
img_displayer.display(img_disp, wait_key_ms=1)
video_writer.write(img_disp)
# -- Get skeleton data and save to file
skels_to_save = get_the_skeleton_data_to_save_to_disk(
dict_id2skeleton)
lib_commons.save_listlist(
DST_FOLDER + DST_SKELETON_FOLDER_NAME +
SKELETON_FILENAME_FORMAT.format(ith_img),
skels_to_save)
finally:
video_writer.stop()
print("Program ends")
需要源代码的请留下邮箱或者加我wx,Andre_XLXDream
文章来源:https://blog.csdn.net/weixin_43050480/article/details/135637650
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!