enumerate()函数讲解+同时获取索引和对应的元素值+实例
发布时间:2023年12月18日
? ? ? ?enumerate()函数是Python内置函数,用于在遍历可迭代对象(如列表、字符串、元组等)时,同时获取索引和对应的元素值。
? ? ? 它的主要作用是在循环过程中方便地获取索引和元素。
下面以两个例子来进行介绍理解。
目录
一、例子1
代码:
list1 = ['语文', '数学', '英语']
# turple = ('语文', '数学', '英语')
for index, item in enumerate(list1):
print("Index:", index, "Item:", item)?结果:

在这个例子中,enumerate()函数返回一个包含索引和对应值的元组。
这样,我们可以在一个循环中同时获取列表的索引和元素,而不需要单独计算索引。
二、例子2
准备数据
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
# 这里,`load_iris()`函数从sklearn库中加载鸢尾花数据集
X = iris.data
Y = iris.target
# 并将数据和目标变量分别存储在X和Y中。
# X表示花瓣长度、花瓣宽度、花萼长度和花萼宽度等特征,Y表示三个品种(setosa,versicolor,virginica)的标签。
# 将X和Y转换为DataFrame
data = pd.DataFrame(X, columns=iris.feature_names)
data['target'] = Y结果:
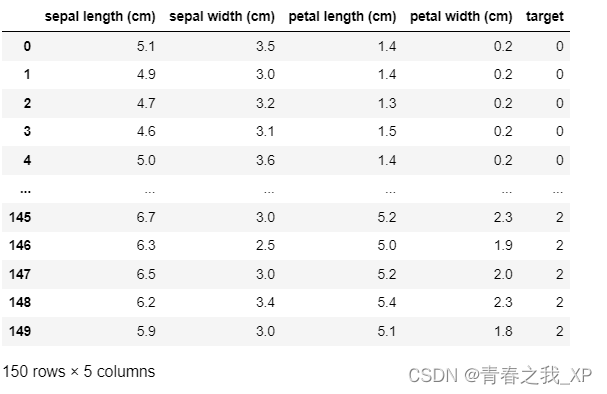
?其中有150列,即150各样本,target列有150个值,前50个值为0,中间50个值为1,后50个值为2
体会下面两段代码:
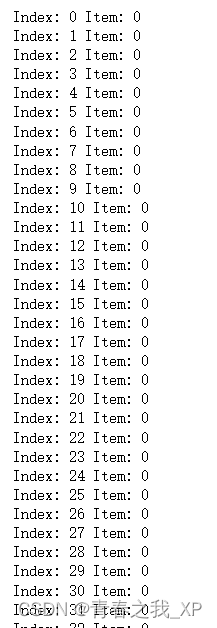
①
for index, item in enumerate(data["target"]):
print("Index:", index, "Item:", item)结果如下:
最终结果返回的是每个样本对应的索引值和元素值
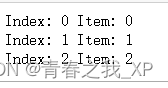
?②
for index, item in enumerate(data["target"].unique()):
print("Index:", index, "Item:", item)? ? ? ?在这段代码中,`enumerate(data["target"].unique())` 返回的结果,其中包含了索引和对应的唯一值。
请看,索引返回的是0、1、2,并不是其在鸢尾花原数据集的索引
? ? ? 因为,这里的索引是相对于 `data["target"].unique()` 的,而不是原始数据集的索引。
? ? ? 所以,`index` 不会反映原始的索引标签。
文章来源:https://blog.csdn.net/2301_81199775/article/details/134924114
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 医学图像的图像处理、分割、分类和定位-1
- 操作系统概述
- 小白水平理解面试经典题目LeetCode 121 Best Time to Buy and Sell Stock
- 如何利用零售店铺管理系统优化门店业务?
- 国际会议口译,选择同传好还是交传好
- 【SpringBoot】—— 如何创建SpringBoot工程
- 《ARM Linux内核源码剖析》读书笔记——0号进程(init_task)的创建时机
- CAN 六:CAN过滤器编程举例
- Java后端问题排查经验
- 关于“Python”的核心知识点整理大全55