轻量化CNN网络 - MobileNet
传统卷积神经网络,内存需求大、运算量大,导致无法在移动设备以及嵌入式设备上运行。
MobileNet网络是由google团队在2017年提出的,专注于移动端或者嵌入式设备中的轻量级CNN网络。相比传统卷积神经网络,在准确率小幅降低的前提下大大减少模型参数与运算量。(相比VGG16准确率减少了0.9%,但模型参数只有VGG的1/32)
1. MobileNet V1
论文:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
网址:https://arxiv.org/abs/1704.04861
网络亮点:
- 深度可分离卷积(大大减少运算量和参数数量)
- 增加超参数, 控制卷积层卷积核个数的参数 α 和控制输出图像大小的参数 β 控制卷积层卷积核个数的参数\alpha和控制输出图像大小的参数\beta 控制卷积层卷积核个数的参数α和控制输出图像大小的参数β,这两个参数是手动设定的,并不是学习得来的
传统卷积
卷积核通道 = 输入特征矩阵通道
输出特征矩阵通道 = 卷积核个数
深度可分离卷积 Depthwise Separable Conv:DW Conv+PW Conv
1.逐通道卷积 Depthwise Conv(DW Conv)
卷积核通道 = 1
输入特征矩阵通道 = 卷积核个数 = 输出特征矩阵通道
Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积
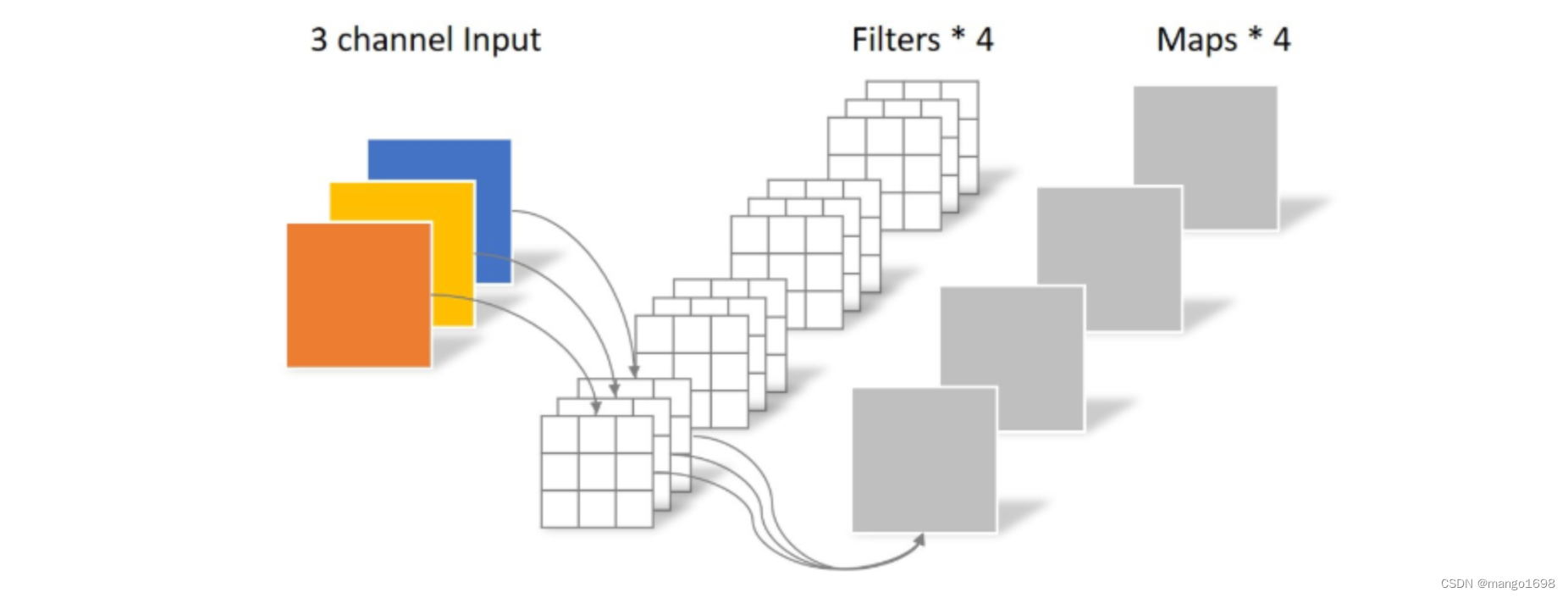
一张 5 × 5 5\times5 5×5像素、三通道彩色输入图片(shape为 5 × 5 × 3 5\times5\times3 5×5×3),Depthwise Convolution首先经过第一次卷积运算,DW完全是在二维平面内进行。卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。所以一个三通道的图像经过运算后生成了3个Feature map(如果有same padding则尺寸与输入层相同为 5 × 5 5\times5 5×5),如下图所示。
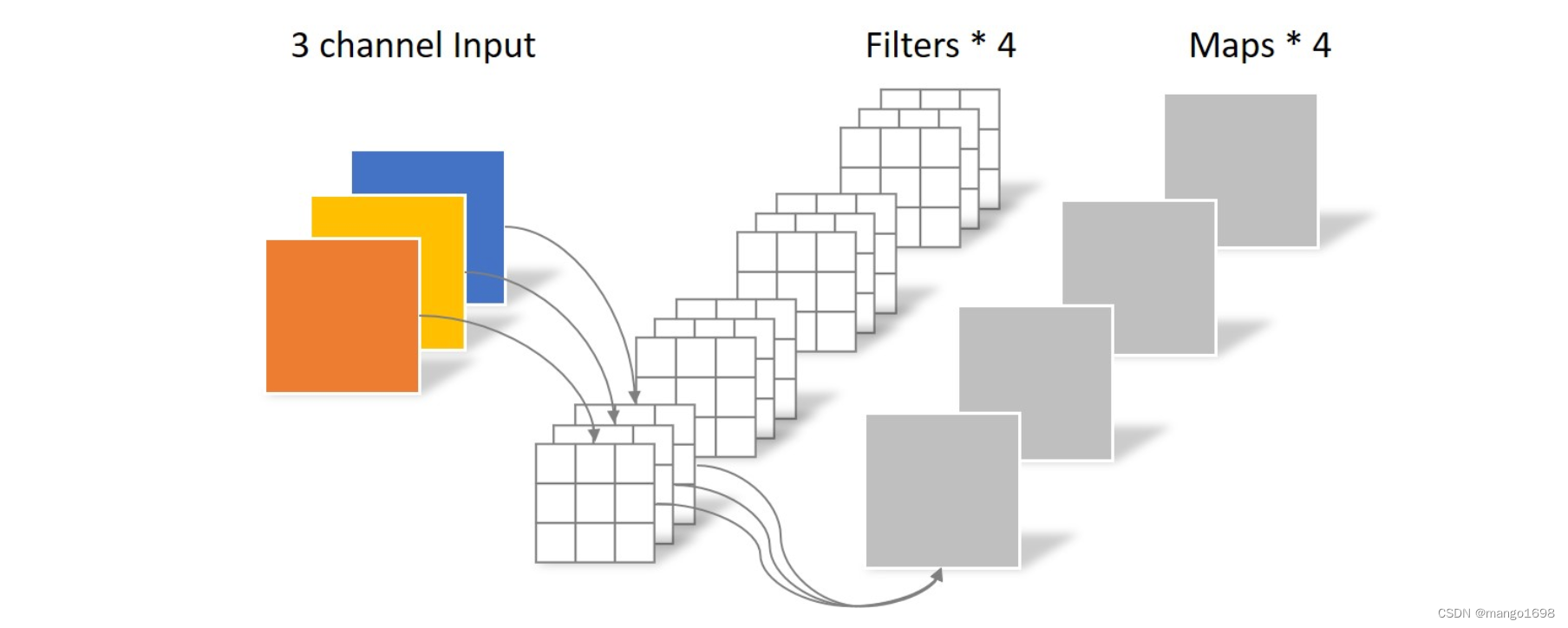
其中一个Filter只包含一个大小为 3 × 3 3\times3 3×3的Kernel,卷积部分的参数个数计算如下: N _ d e p t h w i s e = 3 × 3 × 3 = 27 N\_depthwise = 3\times3 \times3 = 27 N_depthwise=3×3×3=27
Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。
DW部分的卷积核容易废掉,即卷积核参数大部分为0。
2.逐点卷积 Pointwise Conv (PW Conv)
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1 × 1 × M 1\times1\times M 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。
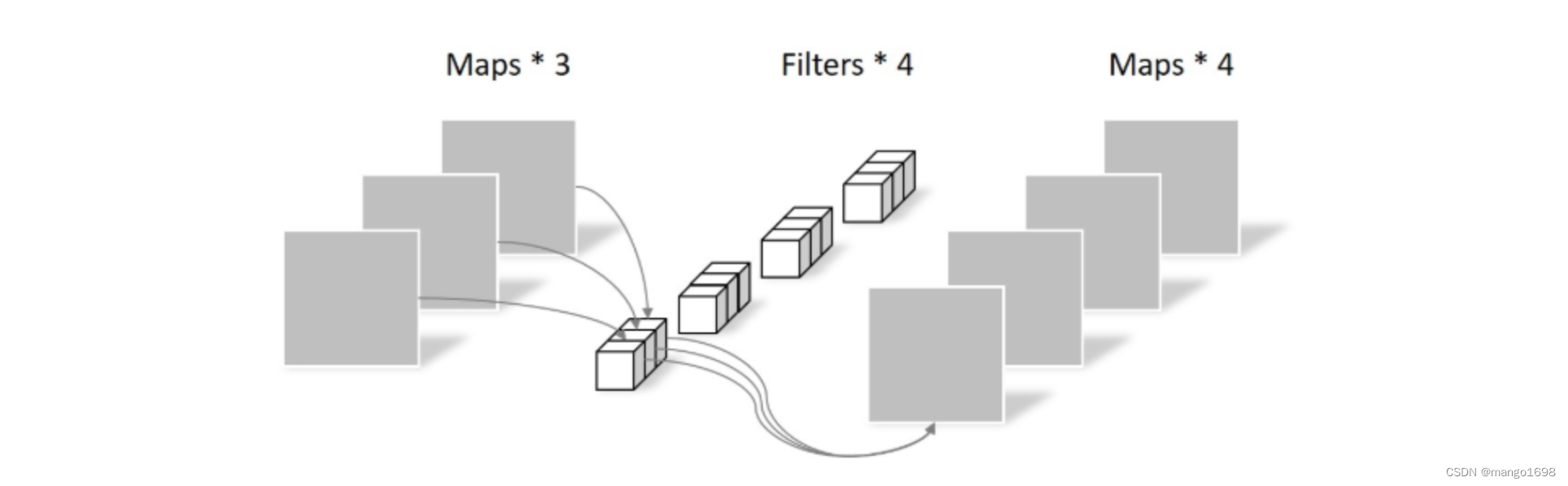
理论上,普通卷积计算量是DW+PW的8到9倍。
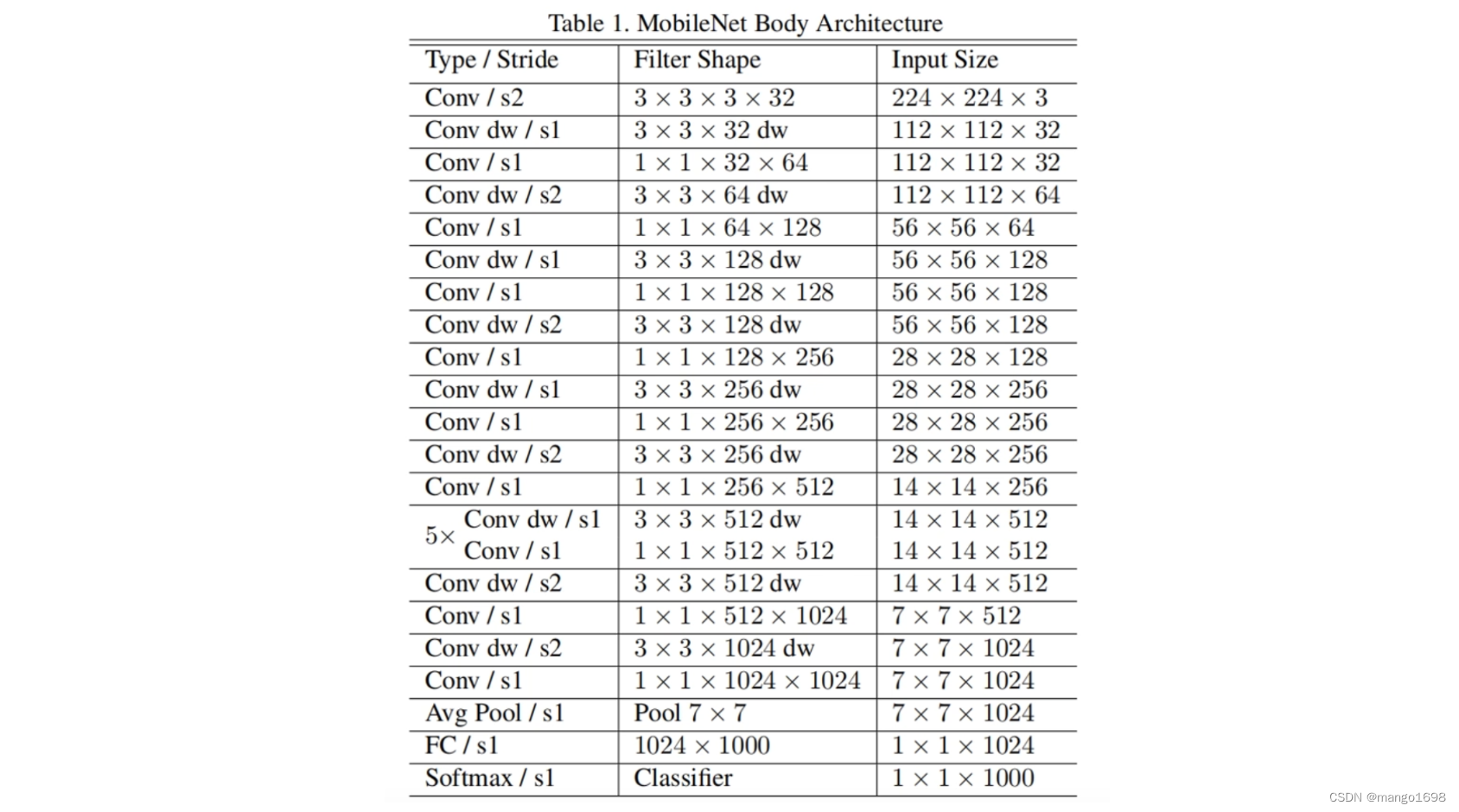
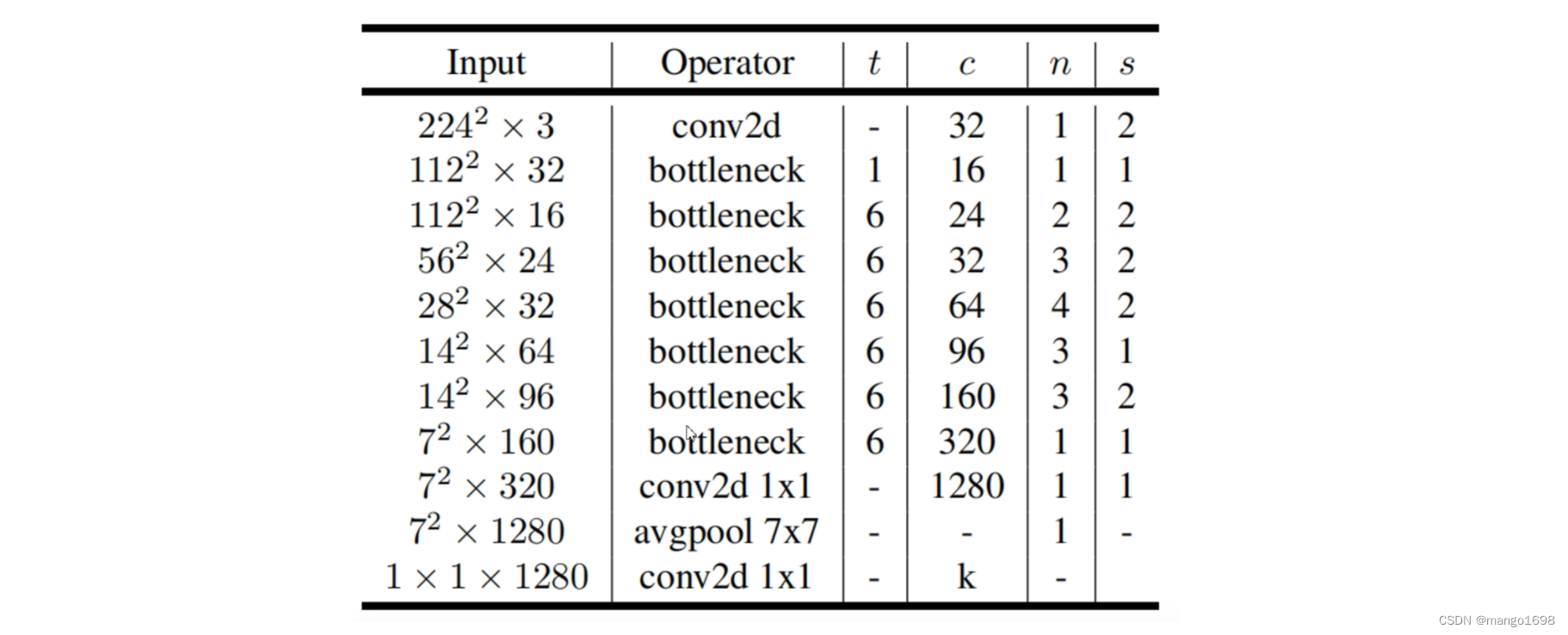
MobileNet V1网络结构
2. MobileNet V2
论文:MobileNetV2: Inverted Residuals and Linear Bottlenecks
网址:https://arxiv.org/abs/1801.04381
MobileNet V2网络是由google团队在2018年提出的,相比MobileNet V1网络,准确率更高,模型更小。
网络亮点:
- Inverted Residuals(倒残差结构)
- Liner Bottlenecks(线性瓶颈)
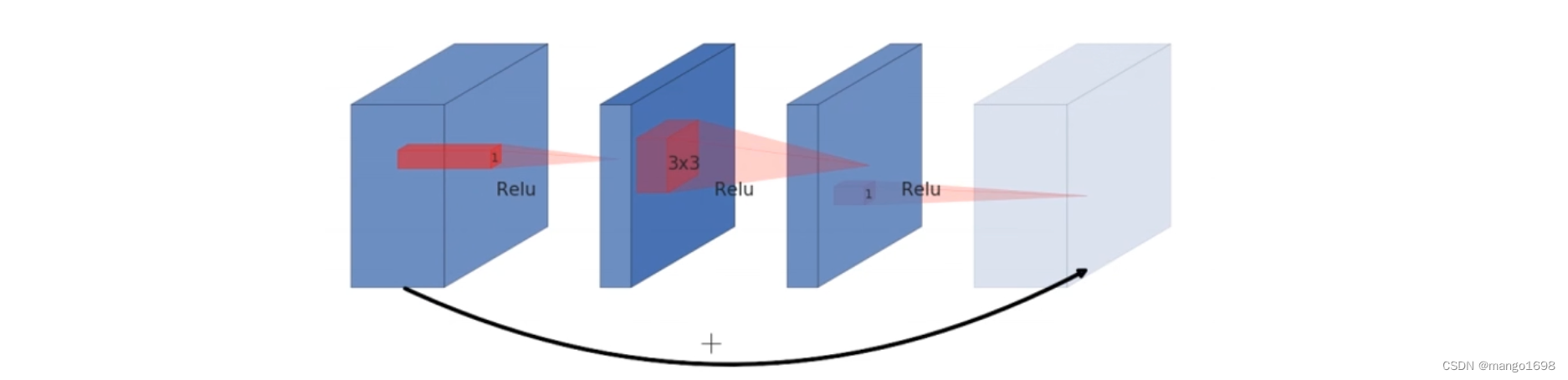
Resnet中的残差结构:(激活函数采用ReLU)
- 先使用 1 × 1 1\times1 1×1的卷积核进行降维操作
- 再进行常规卷积操作
- 再使用 1 × 1 1\times1 1×1的卷积核进行升维操作
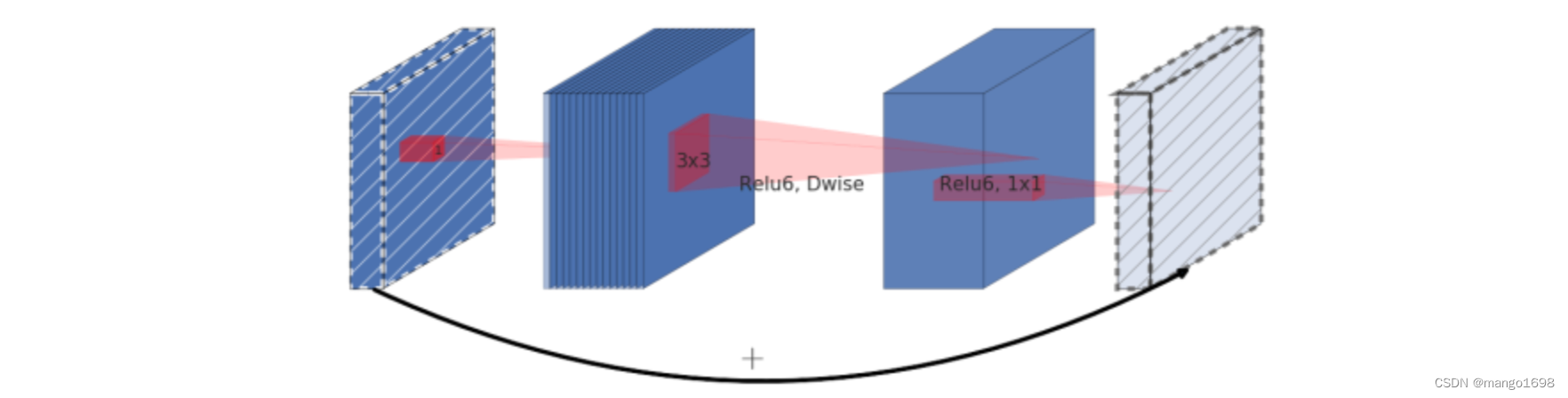
倒残差结构:(激活函数采用ReLU6)
- 先使用 1 × 1 1\times1 1×1的卷积核进行升维操作
- 在进行DW(逐通道卷积)卷积
- 然后在使用 1 × 1 1\times1 1×1的卷积核进行降维处理(PW逐点卷积)
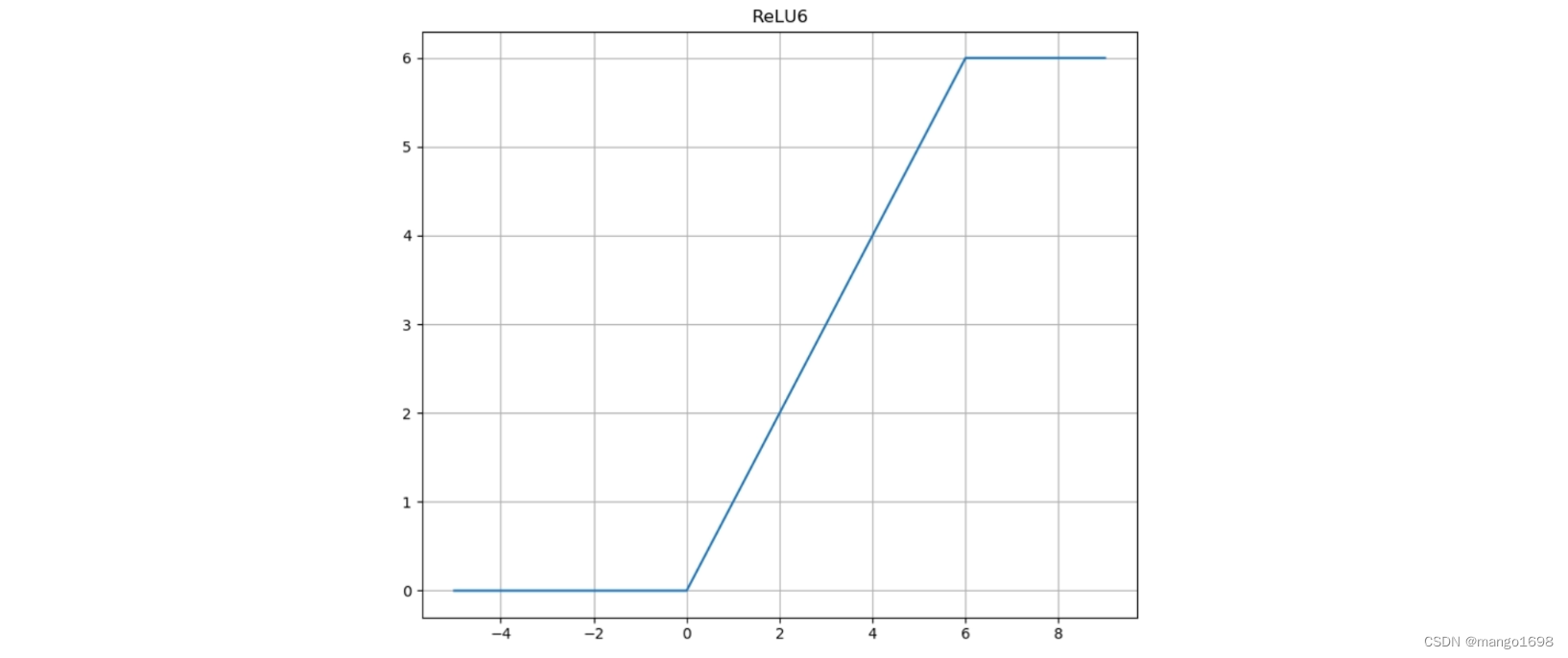
ReLU6激活函数:
y
=
R
e
L
U
6
(
x
)
=
m
i
n
(
m
a
x
(
x
,
0
)
,
6
)
y = ReLU6(x) = min(max(x,0),6)
y=ReLU6(x)=min(max(x,0),6)
Linear Bottlenecks (线性瓶颈)
先说瓶颈(Bottleneck), 1 × 1 1\times1 1×1卷积小像个瓶口所以叫瓶颈,该词的来源是resnet的经典网络使用的词汇,当前的MobileNet v2依旧使用了该结构的block。
再说linear,如下图,从下往上看的,看最后的pointwise卷积,之前的pointwise卷积是升维的,轮到最后的pointwise卷积就是降维,设计该网的作者说高维加个非线性挺好,低维要是也加非线性就把特征破坏了,不如线性的好,所以1*1后不加ReLU6 ,改换线性。
针对倒残差结构的最后一个 1 × 1 1\times1 1×1的卷积层,使用了线性激活函数,而非ReLU激活函数。
ReLU激活函数对低维特征信息造成大量损失
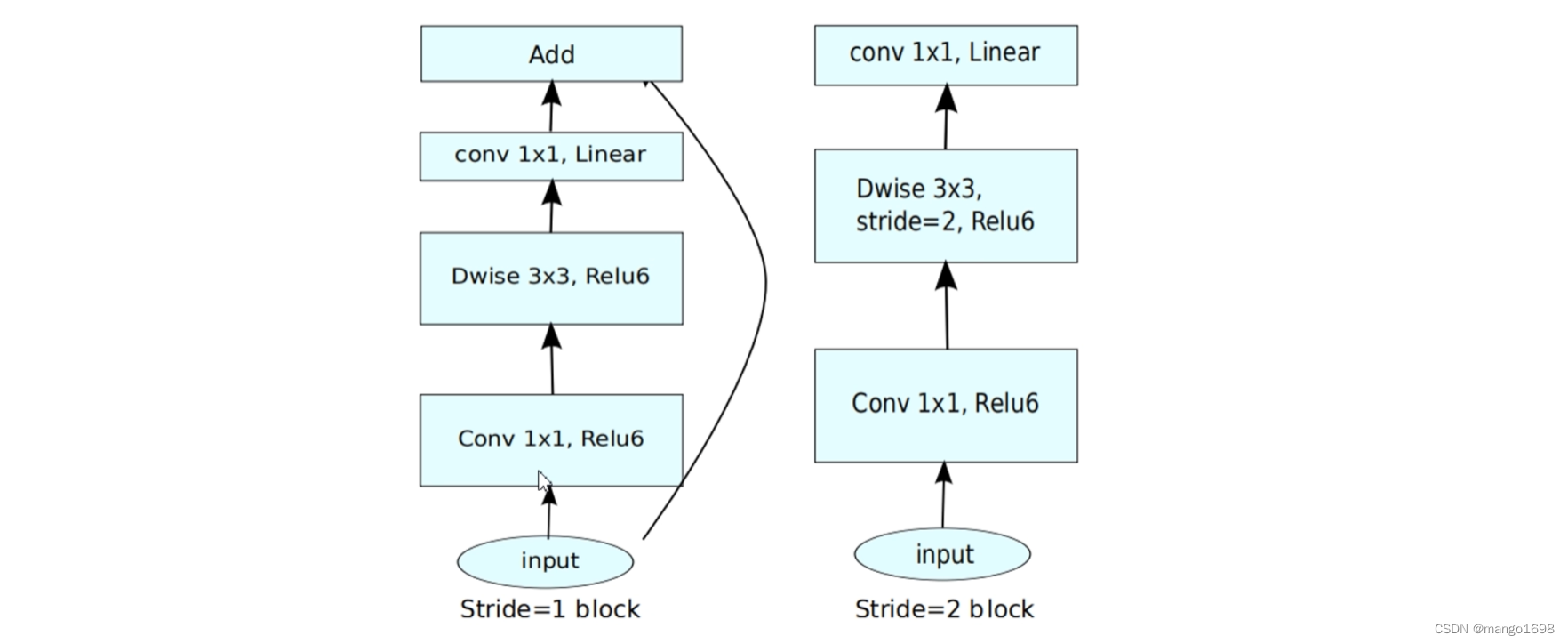
当stride=1且输入特征矩阵与输出特征矩阵shape相同时才有shortcut连接。
MobileNet V2网络结构
3. MobileNet V3
论文:Searching for MobileNetV3
网址:https://arxiv.org/abs/1905.02244
网络亮点:
- 更新Block(benck)
- 使用NAS搜索参数(Neural Architecture Search)
- 重新设计耗时层结构
更新Block
-
加入了SE模块(注意力机制)
-
更新了激活函数
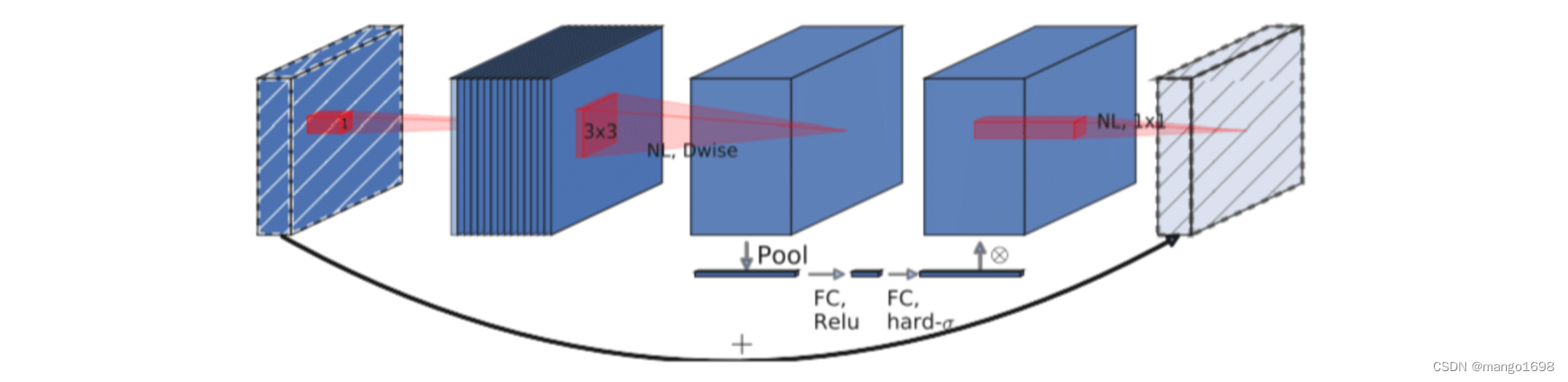
注意力机制部分:
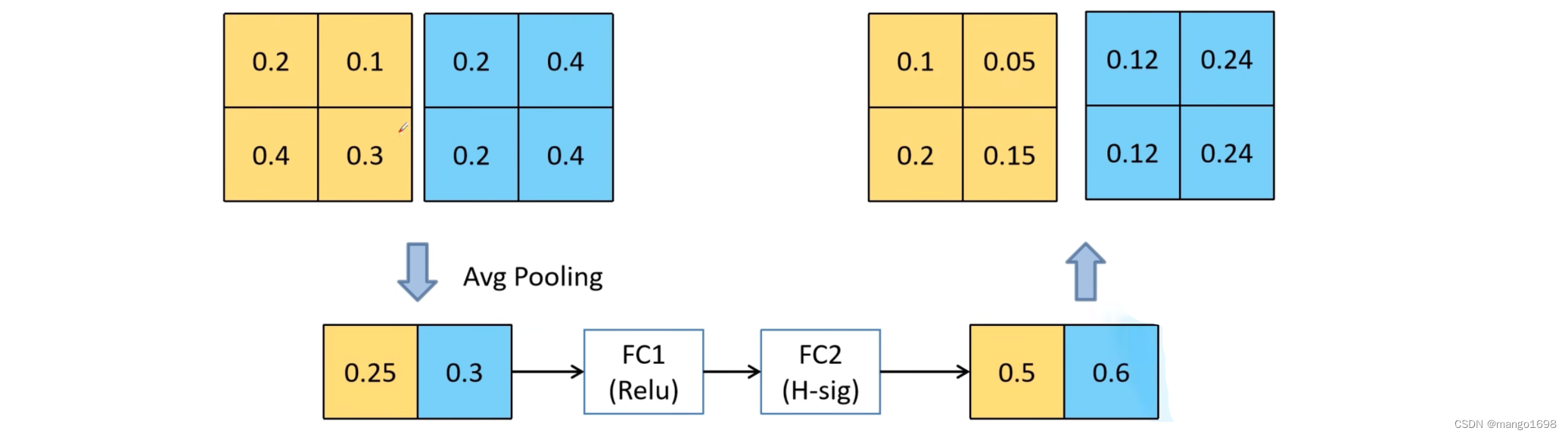
H-sig:Hard-sigmoid激活函数
重新设计激活函数:
使用swish激活函数,公式如下。
s
w
i
s
h
(
x
)
=
x
?
σ
(
x
)
σ
(
x
)
=
1
1
+
e
?
x
swish(x) = x·\sigma(x)\\ \sigma(x) = \frac{1}{1+e^{-x}}
swish(x)=x?σ(x)σ(x)=1+e?x1?
σ
(
x
)
\sigma(x)
σ(x)为sigmoid激活函数。
swish激活函数计算、求导复杂,对量化过程不友好,因此,作者提出了h-swish激活函数。
R
e
L
U
6
(
x
)
=
m
i
n
(
m
a
x
(
x
,
0
)
,
6
)
ReLU6(x) = min(max(x,0),6)
ReLU6(x)=min(max(x,0),6)
h ? s i g m o i d = R e L U 6 ( x + 3 ) 6 h-sigmoid = \frac{ReLU6(x+3)}{6} h?sigmoid=6ReLU6(x+3)?
h ? s w i s h ( x ) = x R e L U 6 ( x + 3 ) 6 h-swish(x) = x\frac{ReLU6(x+3)}{6} h?swish(x)=x6ReLU6(x+3)?
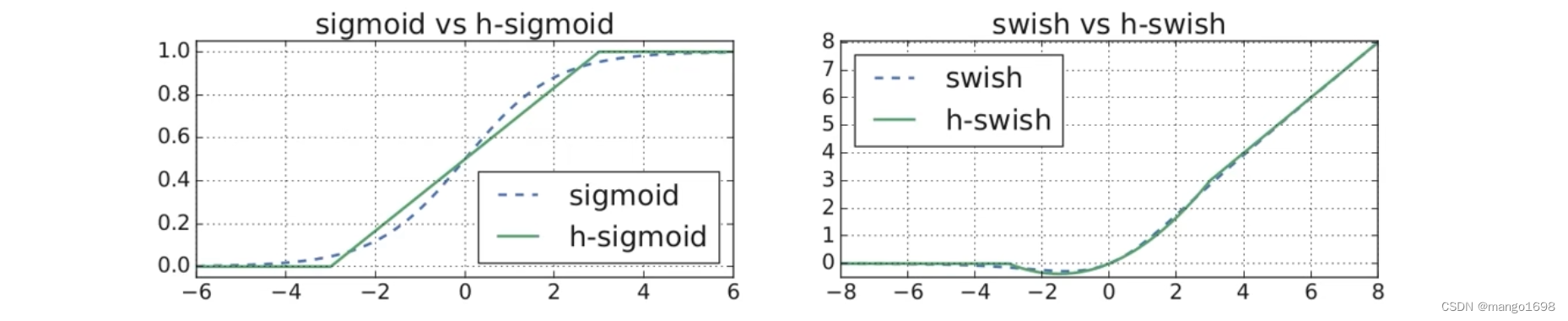
在很多时候,我们会选择使用h-sigmoid激活函数来替换sigmoid激活函数。使用h-swish激活函数来替代h-swish激活函数。
重新设计耗时层结构
1.减少第一个卷积层的卷积核个数(32->16)
2.精简Last Stage
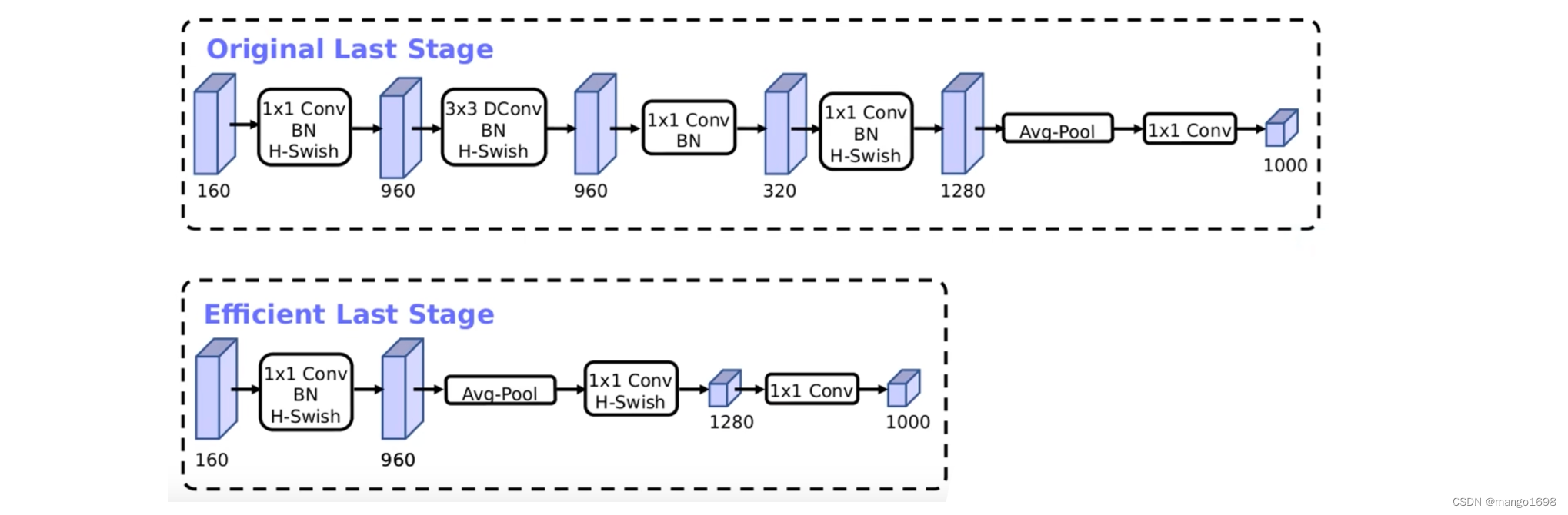
这样调整后,作者发现,在准确率方面没有发生很大的变化,但是节省了7毫秒(占推理过程的11%)的执行时间。
MobileNet V3-Large网络结构
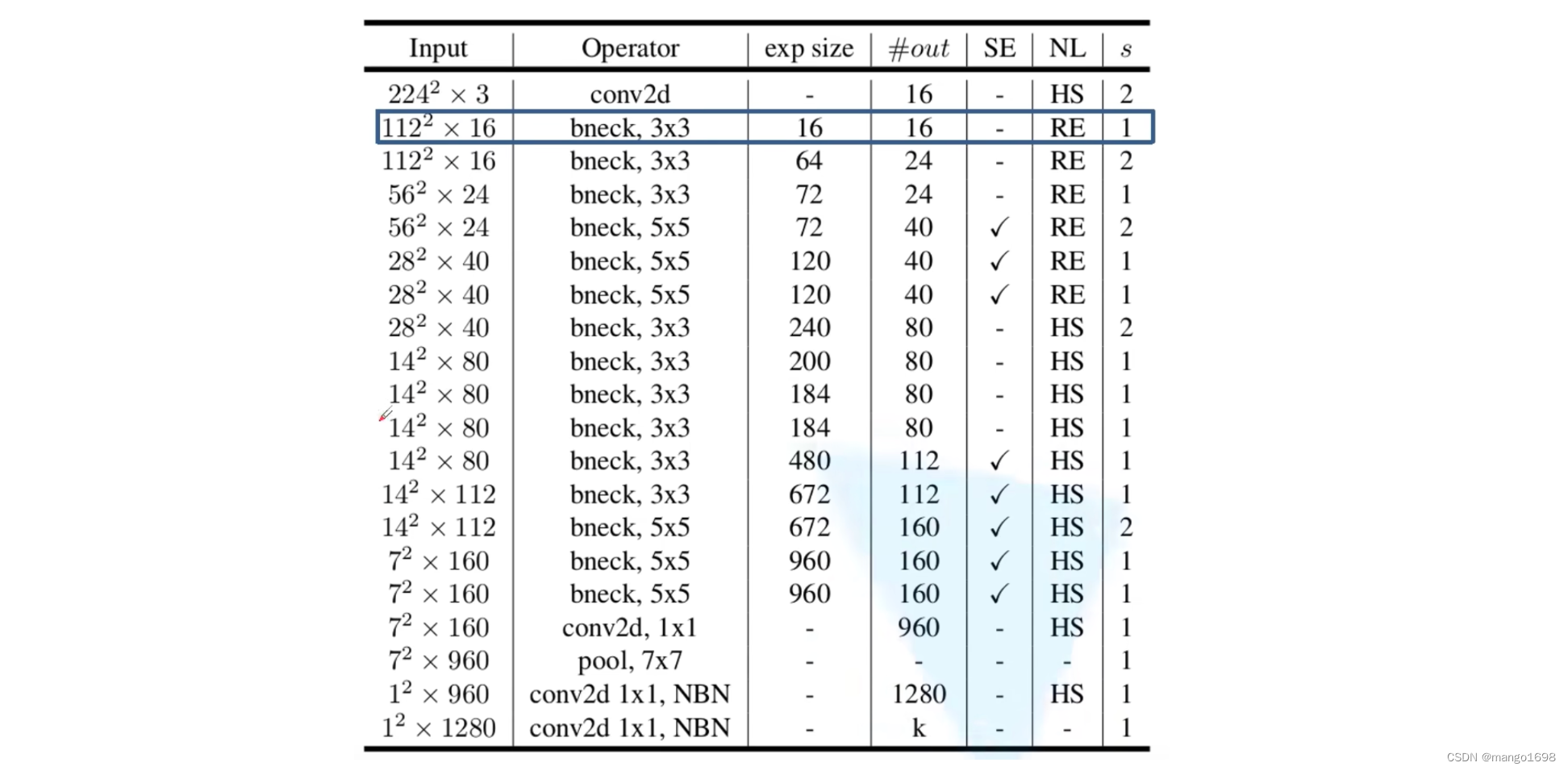
注意:在第一个bneck中,并没有使用 1 × 1 1\times1 1×1对卷积进行升维操作。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 用NEO4J平台构建一个《人工智能引论》课程的多模态知识图谱
- K8S--解决访问Harbor私有仓库无权限的问题(401 Unauthorized)
- 免费、好用!IDEA插件用这款!
- 第十一章 后端编译与优化
- Vue学习计划-Vue3--核心语法(十)Proxy响应式原理
- 限时福利,Adobe InCopy2024下载安装指南
- pyecharts绘制饼图
- 网络机顶盒什么牌子好?小编分享最新网络机顶盒排行榜
- 优雅应对代码上下文不同,功能相同的情况
- QT C++ TCP Socket 请求心知天气