深度解析LinkedList
LinkedList是Java集合框架中List接口的实现之一,它以双向链表的形式存储元素。与传统的数组相比,链表具有更高的灵活性,特别适用于频繁的插入和删除操作。让我们从底层实现开始深入了解这个强大的数据结构。

底层数据结构
LinkedList的底层数据结构是双向链表。每个节点都包含一个数据元素以及两个引用,一个指向前一个节点(prev),一个指向下一个节点(next)。这种结构使得在链表中进行插入和删除操作变得非常高效。
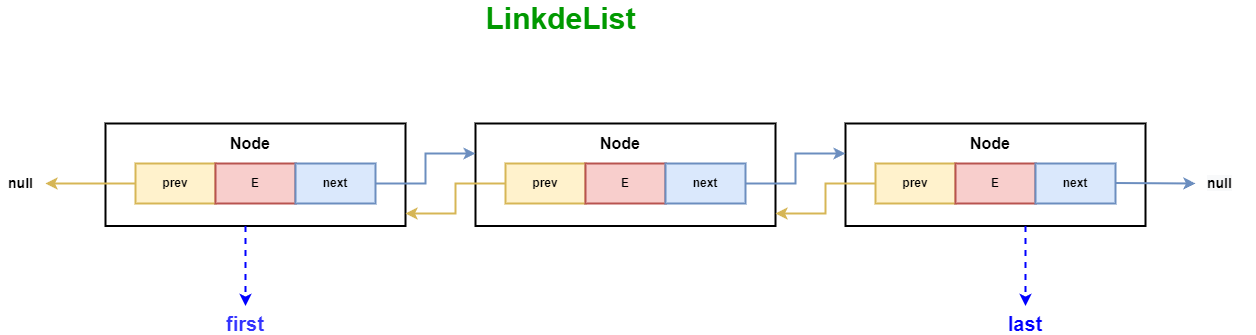
LinkedList的属性及Node源码如下:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
public LinkedList() {
}
...
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
...
}
LinkedList包含两个重要的实例变量:first和last,分别指向链表的头节点和尾节点。这两个节点使得在链表的两端进行操作更为高效。
size字段表示链表中元素的数量,通过它我们可以随时获取链表的大小。
Node类是LinkedList数据结构的基础。每个节点都包含一个数据元素、一个指向下一个节点的引用(next),以及一个指向前一个节点的引用(prev)。
- item:当前节点的数据元素。
- next:下一个节点的引用。
- prev:前一个节点的引用。
操作方法
篇幅有限,我们在这详细解释下常用的几个方法,别的方法家人们可自行阅读源码
add(E e): 在链表尾部添加元素
add(E e): 在链表尾部添加元素。
// LinkedList类中的add方法
public boolean add(E e) {
linkLast(e);
return true;
}
linkLast(e)
// 在链表尾部链接新节点的方法
void linkLast(E e) {
// 获取尾节点的引用
final Node<E> l = last;
// 创建新节点,其前一个节点是尾节点,后一个节点为null
final Node<E> newNode = new Node<>(l, e, null);
// 将新节点更新为尾节点
last = newNode;
if (l == null)
// 如果链表为空,同时将新节点设置为头节点
first = newNode;
else
// 否则,将原尾节点的next指向新的尾节点
l.next = newNode;
// 增加链表的大小
size++;
//修改计数器
modCount++;
}
源码详解:
-
final Node l = last;
通过last字段获取链表的尾节点引用。这一步是为了后续创建新节点时能够将其连接到链表的尾部。
-
final Node newNode = new Node<>(l, e, null);
使用Node类的构造方法创建一个新节点,其前一个节点是链表的尾节点l,后一个节点为null,因为这是新的尾节点。
-
last = newNode;
将链表的last字段更新为新创建的节点,使其成为新的尾节点。
-
if (l == null) first = newNode;
如果链表为空(即尾节点为null),则将头节点first指向新节点。因为在空链表中添加元素时,头节点和尾节点都是新节点。
-
else l.next = newNode;
如果链表非空,将原尾节点的next引用指向新节点,以完成新节点的插入。
-
size++;
每次成功添加一个元素后,增加链表的大小。
-
modCount++;
modCount是用于迭代器的修改计数器,用于在迭代时检测是否有其他线程修改了集合。每次对链表结构进行修改时,都会增加modCount的值。modCount是用于迭代器的修改计数器,用于在迭代时检测是否有其他线程修改了集合。每次对链表结构进行修改时,都会增加modCount的值。
add(int index, E element): 在指定位置插入元素
//在指定位置插入元素的方法
public void add(int index, E element) {
//参数检查
checkPositionIndex(index);
//链表尾部插入元素
if (index == size)
linkLast(element);
// 非尾部插入的情况
else
linkBefore(element, node(index));
}
checkPositionIndex():参数检查
//参数检查
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
isPositionIndex():判断指定下标是否合法
//判断指定下标是否合法
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}
node(int index):获取指定位置的节点
Node<E> node(int index) {
// assert isElementIndex(index);
//判断索引位置(判断索引位于链表的前半部分还是后半部分,提高元素获取的性能)
if (index < (size >> 1)) {
//前半部分的话从头节点开始遍历,通过节点的next一直查找到当前索引所在的元素
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
//后半部分的话从尾始遍历,通过节点的prev一直查找到当前索引所在的元素
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
源码详解:
- if (index < (size >> 1)) {
>>带符号右移运算符,一个数的二进制表示向右移动指定的位数,左侧空出的位置使用原始数值的最高位进行填充。这个操作相当于将数值除以2的指定次方并向下取整。右移一位相当于除以2。
这行代码是判断索引位置,即判断索引位于链表的前半部分还是后半部分来决定是从前往后还是从后往前遍历链表,以提高元素获取的性能。
- Node x = first; for (int i = 0; i < index; i++) x = x.next;
如果目标节点在链表的前半部分,就从头节点 first 开始,通过next往后遍历,找到对应索引的节点并返回。
-
Node x = last; for (int i = size - 1; i > index; i–) x = x.prev;
如果目标节点在链表的后半部分,就从尾节点 last 开始,通过prev往前遍历,找到对应索引的节点并返回。
linkBefore():非尾部插入元素
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
//获取到要插入位置元素的前驱引用
final Node<E> pred = succ.prev;
// 创建新节点,其前驱引用是插入位置原节点的前驱引用,后驱引用为插入位置原节点
final Node<E> newNode = new Node<>(pred, e, succ);
//更新插入位置原节点的前驱引用为插入节点
succ.prev = newNode;
//处理前驱节点为空的情况
if (pred == null)
first = newNode;
//处理前驱节点非空的情况
else
pred.next = newNode;
// 增加链表的大小
size++;
//修改计数器
modCount++;
}
源码详解:
-
final Node pred = succ.prev;
通过 succ 节点的 prev 引用,获取插入位置的前一个节点 pred。
-
final Node newNode = new Node<>(pred, e, succ);
使用 Node 类的构造方法创建一个新的节点,其前一个节点是 pred,后一个节点是 succ。
-
succ.prev = newNode;
将后继节点 succ 的前驱引用指向新节点 newNode,确保新节点的插入。
-
if (pred == null) first = newNode;
如果前驱节点为空,说明新节点插入的位置是链表的头部,将链表的头节点 first 指向新节点 newNode。
-
else pred.next = newNode;
如果前驱节点非空,将前驱节点的 next 引用指向新节点 newNode,完成新节点的插入。
-
size++;
每次成功添加一个元素后,增加链表的大小。
- modCount++;
modCount是用于迭代器的修改计数器,用于在迭代时检测是否有其他线程修改了集合。每次对链表结构进行修改时,都会增加modCount的值。modCount是用于迭代器的修改计数器,用于在迭代时检测是否有其他线程修改了集合。每次对链表结构进行修改时,都会增加modCount的值。
remove(Object o): 从链表中移除指定元素
public boolean remove(Object o) {
//处理删除元素为null的情况
if (o == null) {
//遍历链表
for (Node<E> x = first; x != null; x = x.next) {
//获取到第一个为null的元素
if (x.item == null) {
//删除元素
unlink(x);
return true;
}
}
//处理删除元素非null的情况
} else {
//遍历链表
for (Node<E> x = first; x != null; x = x.next) {
//获取到要删除的元素
if (o.equals(x.item)) {
//删除元素
unlink(x);
return true;
}
}
}
return false;
}
源码解析:
- if (o == null) {
这里首先检查传入的参数 o 是否为 null,分别处理 null 和非 null 两种情况。
- if (o == null) { for (Node x = first; x != null; x = x.next) {…
如果要删除的元素是 null,则通过遍历链表找到第一个值为 null 的节点,然后调用 unlink(x) 方法删除该节点。删除成功后返回 true。如果要删除的元素是 null,则通过遍历链表找到第一个值为 null 的节点,然后调用 unlink(x) 方法删除该节点。删除成功后返回 true。
- else { for (Node x = first; x != null; x = x.next) { …
如果要删除的元素不为 null,则通过遍历链表找到第一个值与参数 o 相等的节点,然后调用 unlink(x) 方法删除该节点。删除成功后返回 true。
- return false;
如果遍历完整个链表都没有找到要删除的元素,则返回 false 表示删除失败。
unlink(Node x):实际执行节点删除的方法
E unlink(Node<E> x) {
// assert x != null;
//获取要删除的元素
final E element = x.item;
//获取要删除的元素的后继
final Node<E> next = x.next;
//获取要删除的元素的前驱
final Node<E> prev = x.prev;
//处理前驱节点为空的情况
if (prev == null) {
first = next;
//前驱节点非空则处理前驱的后继
} else {
prev.next = next;
x.prev = null;
}
//处理后继节点为空的情况
if (next == null) {
last = prev;
//后继节点非空则处理后继的前驱
} else {
next.prev = prev;
x.next = null;
}
//清空目标节点的数据元素
x.item = null;
//减小链表的大小
size--;
//更新修改计数器
modCount++;
return element;
}
源码详解:
-
final E element = x.item;
通过 x 节点的 item 字段获取节点的数据元素,即要删除的元素。
-
final Node next = x.next; final Node prev = x.prev;
通过 x 节点的 next 和 prev 字段获取目标节点的后继节点和前驱节点。
-
if (prev == null) { if (prev == null) { first = next; } else { prev.next = next; x.prev = null; }
如果前驱节点为空,说明要删除的节点是链表的头节点,将目标节点的后继节点 next设置为链表的头节点 first 。如果前驱节点非空,将前驱节点的 next 引用指向目标节点的后继节点,同时将目标节点的 prev 引用置为 null。
-
if (next == null) { last = prev; else { next.prev = prev; x.next = null; }
如果后继节点为空,说明要删除的节点是链表的尾节点,将链表的尾节点 last 指向目标节点的前驱节点 prev。如果后继节点非空,将后继节点的 prev 引用指向目标节点的前驱节点,同时将目标节点的 next 引用置为 null。
- x.item = null;
将目标节点的 item 字段置为 null,帮助垃圾回收系统回收节点的数据元素。
-
size–; modCount++;
每次成功删除一个节点后,减小链表的大小,并更新修改计数器。
-
return element;
最后,返回被删除节点的数据元素。
LinkedList的优势和劣势
优势
- 动态大小: 链表可以动态地分配内存,不需要预先指定大小。
- 插入和删除: 在链表中插入和删除元素更为高效,因为只需要调整节点的引用。
劣势
- 随机访问困难: 在链表中要访问特定位置的元素,必须从头结点开始遍历,效率相对较低。
- 额外空间: 链表每个节点需要额外的空间存储引用,相比数组会占用更多的内存。
使用场景
LinkedList适用于以下场景:
- 频繁的插入和删除操作: 由于链表的节点可以方便地插入和删除,适用于这类操作频繁的场景。
- 不需要频繁随机访问: 如果主要操作是在链表两端进行,而不是在中间进行随机访问,那么链表是一个不错的选择。
总结
LinkedList作为Java集合框架中的一个重要成员,为开发者提供了一种灵活而高效的数据结构。通过深入了解其底层实现和基本特性,我们能够更好地在实际应用中选择和使用这一数据结构,从而优化程序的性能和效率。希望这篇文章能够帮助你更好地理解和使用LinkedList。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!