python期末实训-学生成绩管理系统
python+tkinter+matplotlib学生管理系统
一.需求分析
- 读取学生成绩的excel表格到数据库中
- 将学生成绩导出到excel文件中
- 学生成绩单增删改查与展示
- 学生成绩按学号搜索和按姓名模糊搜素
- 展示班级学生的整体成绩情况
- 导出每位学生的成绩分析图
- 将程序打包成exe
二.系统设计
- 将表格数据读取进数据库函数excel_mysql
- 录入学生信息模块PyMySQLUtils
- 起始登录页面StartMenu
- 教师注册页面TeacherRegsiter
- 教师登录页面TeacherLogin
- 教师操作页面TeacherMenu
- 教师可以对学生成绩进行增删改查,对学生的某一列属性进行升序或降序排序
- 教师可以查看班级的平均分总体情况图表
- 教师可以导出每个同学的成绩分析

三.程序运行的依赖
import tkinter
import matplotlib.pyplot as plt
import numpy as np
import pymysql
from tkinter import *
from tkinter import ttk
import tkinter.font as tkFont
import tkinter.messagebox as messagebox
import pandas as pd
import xlwt
from pypinyin import pinyin, Style
import warnings
from PIL import Image,ImageTk
warnings.filterwarnings("ignore",category=DeprecationWarning)
- tkinter负责GUI图形界面
- matplotlib.pyplot负责可视化图形的绘画
- numpy用于创建可视化图形的x轴和y轴标签
- pymysql用于连接数据库
- ttk有高级的列表GUI
- tkinter.font设置字体
- tkinter.messagebox设置提示框
- pandas用于将excel数据读入 不使用xlrd是因为这个库需要指定版本,兼容性差
- xlwt用于将数据写出到excel表格中
- pypinyin可以将汉字转换为拼音,为了按姓名进行排序,默认的排序是按中文的unicode编码进行排序
- warnings让用户有更好的体验,程序使用了一些过时的函数
- Image,ImageTk用于制作界面的图标
- 最后使用了pyinstaller打包 Pyinstaller -F -w -i ic.ico pyMysql.py
四.系统实现
1.从表格中读取数据
def if_exist(pyutils, id):
sql = "select count(1) from student_score where sid = " + str(id)
return pyutils.fetchone(sql)
def excel_mysql():
data = pd.read_excel("student.xls")
id_dict = {}
utils = PyMySQLUtils()
for i in range(data.shape[0]):
# print(data.loc[i].values.tolist())
id_dict[data.loc[i].iloc[0]] = data.loc[i].values.tolist()
for key, val in id_dict.items():
sid = val[0]
sname = val[1]
sdept = val[2]
Linux = val[3]
Java = val[4]
Python = val[5]
average_score = val[6]
classmate_score = val[7]
teacher_score = val[8]
total_score = val[9]
if (if_exist(utils, key)[0]):
utils.execute(
f"UPDATE student_score SET sname = '{sname}', sdept = '{sdept}', Linux = {Linux}, Java = {Java}, "
f"Python = {Python}, average_score = {average_score}, classmate_score = {classmate_score}, "
f"teacher_score = {teacher_score}, total_score = {total_score} WHERE sid = '{sid}'")
else:
utils.execute(
f"INSERT INTO student_score VALUES('{sid}', '{sname}', '{sdept}', {Linux}, {Java}, {Python}, "
f"{average_score}, {classmate_score}, {teacher_score}, {total_score})")
由于每次运行程序都会从表格中读取数据向数据库插入,为了防止多次插入失败,通过if_exist函数进行判断,不存在进行添加操作,存在进行更新操作
2.列表数据的查询
# 定义储存数据的列表
self.list_sid = []
self.list_sname = []
self.list_sdept = []
self.list_Linux = []
self.list_Java = []
self.list_Python = []
self.list_average_score = []
self.list_classmate_score = []
self.list_teacher_score = []
self.list_total_score = []
# 从数据库获取表格内容
utils = PyMySQLUtils()
results = utils.fetchall("SELECT * FROM student_score")
for row in results:
self.list_sid.append(row[0])
self.list_sname.append(row[1])
self.list_sdept.append(row[2])
self.list_Linux.append(row[3])
self.list_Java.append(row[4])
self.list_Python.append(row[5])
self.list_average_score.append(row[6])
self.list_classmate_score.append(row[7])
self.list_teacher_score.append(row[8])
self.list_total_score.append(row[9])
utils.close()
for i in range(min(len(self.list_sid), len(self.list_sname), len(self.list_sdept), len(self.list_Linux),
len(self.list_Java), len(self.list_Python), len(self.list_average_score),
len(self.list_classmate_score), len(self.list_teacher_score), len(self.list_total_score))):
self.tree.insert("", i,
values=(self.list_sid[i], self.list_sname[i], self.list_sdept[i], self.list_Linux[i],
self.list_Java[i], self.list_Python[i], self.list_average_score[i],
self.list_classmate_score[i], self.list_teacher_score[i],
self.list_total_score[i]))
程序第一次执行时,会对数据库进行查询,将查询到结果放入列表中,然后在对列表中的数据进行遍历,将数据放入到tk的treeview中(也就是tk的表格中)
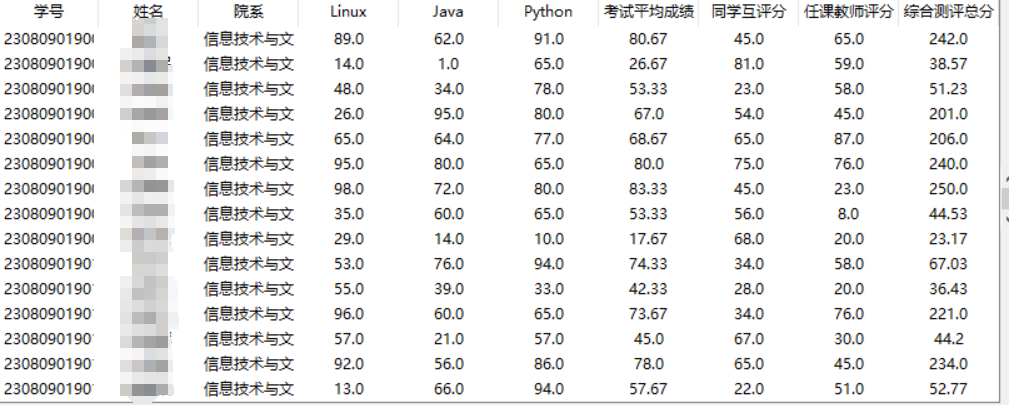
3.列表数据的增加
def insert(self):
if messagebox.askyesnocancel("askyesnocancel", "是否该添加学生成绩信息?"):
sid = self.var_sid.get()
sname = self.var_sname.get()
sdept = self.var_sdept.get()
Linux = round(float(self.var_Linux.get()), 2)
Java = round(float(self.var_Java.get()), 2)
Python = round(float(self.var_Python.get()), 2)
average_score = round(((Linux + Java + Python) / 3), 2)
classmate_score = round(float(self.var_classmate_score.get()), 2)
teacher_score = round(float(self.var_teacher_score.get()), 2)
total_score = round((average_score * 0.7 + classmate_score * 0.1 + teacher_score * 0.2), 2)
if sid in self.list_sid:
messagebox.showwarning("showwarning", "该学生成绩信息已存在!")
else:
utils = PyMySQLUtils()
utils.execute(
f"INSERT INTO student_score VALUES('{sid}', '{sname}', '{sdept}', {Linux}, {Java}, {Python}, "
f"{average_score}, {classmate_score}, {teacher_score}, {total_score})")
utils.close()
self.list_sid.append(sid)
self.list_sname.append(sname)
self.list_sdept.append(sdept)
self.list_Linux.append(Linux)
self.list_Java.append(Java)
self.list_Python.append(Python)
self.list_average_score.append(average_score)
self.list_classmate_score.append(classmate_score)
self.list_teacher_score.append(teacher_score)
self.list_total_score.append(total_score)
self.tree.insert('', 'end', values=(sid, sname, sdept, Linux, Java, Python, average_score,
classmate_score, teacher_score, total_score))
self.tree.update()
messagebox.showinfo("showinfo", "添加学生成绩信息成功!")
通过输入框获得要添加的数据,判断要添加的学生是否存在,若不存在则对数据库进行update操作,然后对treeview的最后进行添加,将新添加到数据加到tree中
4.列表数据的修改
def update(self):
if messagebox.askyesnocancel("askyesnocancel", "是否修改该学生成绩信息?"):
sid = self.var_sid.get()
sname = self.var_sname.get()
sdept = self.var_sdept.get()
Linux = round(float(self.var_Linux.get()), 2)
Java = round(float(self.var_Java.get()), 2)
Python = round(float(self.var_Python.get()), 2)
average_score = round(((Linux + Java + Python) / 3), 2)
classmate_score = round(float(self.var_classmate_score.get()), 2)
teacher_score = round(float(self.var_teacher_score.get()), 2)
total_score = round((average_score * 0.7 + classmate_score * 0.1 + teacher_score * 0.2), 2)
if sid not in self.list_sid:
messagebox.showwarning("showwarning", "该学生成绩信息不存在!")
else:
utils = PyMySQLUtils()
utils.execute(
f"UPDATE student_score SET sname = '{sname}', sdept = '{sdept}', Linux = {Linux}, Java = {Java}, "
f"Python = {Python}, average_score = {average_score}, classmate_score = {classmate_score}, "
f"teacher_score = {teacher_score}, total_score = {total_score} WHERE sid = '{sid}'")
# print(sid)
sid_index = self.list_sid.index(sid)
self.list_sname[sid_index] = sname
self.list_sdept[sid_index] = sdept
self.list_Linux[sid_index] = Linux
self.list_Java[sid_index] = Java
self.list_Python[sid_index] = Python
self.list_average_score[sid_index] = average_score
self.list_classmate_score[sid_index] = classmate_score
self.list_teacher_score[sid_index] = teacher_score
self.list_total_score[sid_index] = total_score
self.tree.item(self.tree.get_children()[sid_index], values=(
sid, sname, sdept, Linux, Java, Python, average_score, classmate_score, teacher_score,
total_score))
messagebox.showinfo("showinfo", "修改学生成绩信息成功!")
通过输入框获得学生的信息后,先判断学生是否存在,若存在则对数据库进行修改,然后查看这个id在id_list的第几个位置,因为id在id_list的位下标ndex一定是等于列表数据在tree中的index,通过index就可以实现tree的更新
5.列表数据的删除
def delete(self):
if messagebox.askyesnocancel("askyesnocancel", "是否删除该学生成绩信息?"):
sid = self.var_sid.get()
if sid not in self.list_sid:
messagebox.showwarning("showwarning", "该学生成绩信息不存在!")
else:
utils = PyMySQLUtils()
utils.execute(f"DELETE FROM student_score WHERE sid = '{sid}'")
utils.close()
sid_index = self.list_sid.index(sid)
del self.list_sid[sid_index]
del self.list_sname[sid_index]
del self.list_sdept[sid_index]
del self.list_Linux[sid_index]
del self.list_Java[sid_index]
del self.list_Python[sid_index]
del self.list_average_score[sid_index]
del self.list_classmate_score[sid_index]
del self.list_teacher_score[sid_index]
del self.list_total_score[sid_index]
self.tree.delete(self.tree.get_children()[sid_index])
messagebox.showinfo("showinfo", "删除学生成绩信息成功!")
和修改一样,通过index连接tree和数据库中数据的关系
6.单击选中功能
def tree_click(self, event):
row = self.tree.identify_row(event.y)
row_info = self.tree.item(row, 'values')
if (len(row) == 0):
return
self.var_sid.set(row_info[0])
self.var_sname.set(row_info[1])
self.var_sdept.set(row_info[2])
self.var_Linux.set(row_info[3])
self.var_Java.set(row_info[4])
self.var_Python.set(row_info[5])
self.var_classmate_score.set(row_info[7])
self.var_teacher_score.set(row_info[8])
如果列表的哪一行被点击,那么就会给下方的输入框挨个赋值,实现单机选中
7.搜索框功能
一共两个搜索功能,一个是按照学号精确查询一个是按照姓名模糊查询
精准查询是在学号一栏输入学号,然后单击查询学生成绩,程序会执行回调函数进行查询

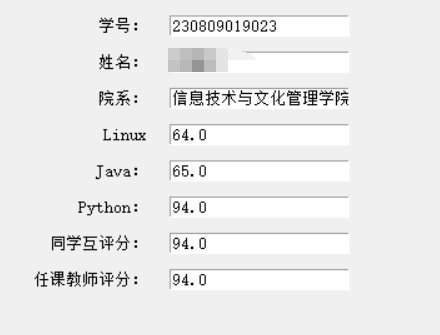
def select(self):
if messagebox.askyesnocancel("askyesnocancel", "是否查询该学生成绩信息?"):
sid = self.var_sid.get()
if sid not in self.list_sid:
messagebox.showwarning("showwarning", "该学生成绩信息不存在!")
else:
sid_index = self.list_sid.index(sid)
self.var_sname.set(self.list_sname[sid_index])
self.var_sdept.set(self.list_sdept[sid_index])
self.var_Linux.set(self.list_Linux[sid_index])
self.var_Java.set(self.list_Java[sid_index])
self.var_Python.set(self.list_Python[sid_index])
self.var_classmate_score.set(self.list_Python[sid_index])
self.var_teacher_score.set(self.list_teacher_score[sid_index])
messagebox.showinfo("showinfo", "查询学生成绩信息成功!")
获得id在数组中的下标,然后通过下标为输入框赋值
模糊查询
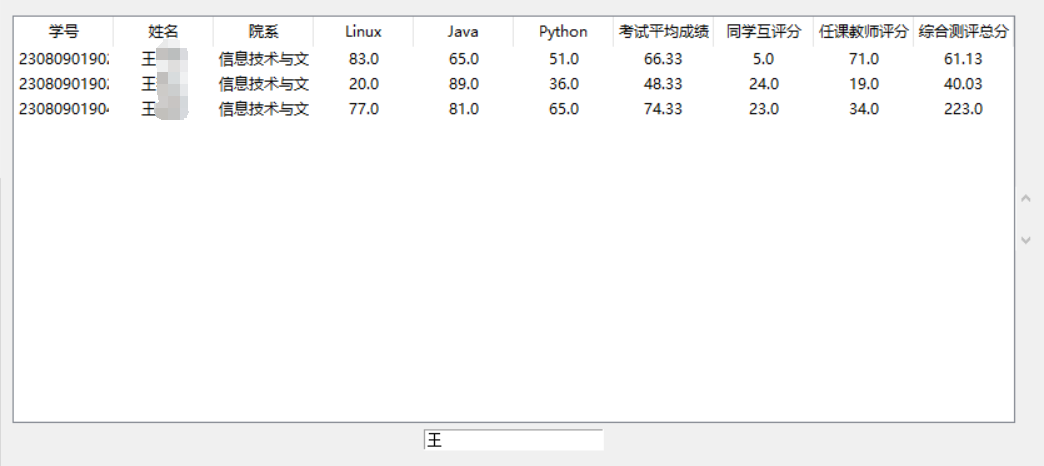
def find(self, x):
# print(x)
utils = PyMySQLUtils()
# print("3self.key_name="+self.key_name)
results = utils.fetchall("SELECT * FROM student_score where sname like " + "'%" + self.var_find.get() + "%'")
# print(results)
for i in range(min(len(self.list_sid), len(self.list_sname), len(self.list_sdept), len(self.list_Linux),
len(self.list_Java), len(self.list_Python), len(self.list_average_score),
len(self.list_classmate_score), len(self.list_teacher_score), len(self.list_total_score))):
sid_index = min(len(self.list_sid), len(self.list_sname), len(self.list_sdept), len(self.list_Linux),
len(self.list_Java), len(self.list_Python), len(self.list_average_score),
len(self.list_classmate_score), len(self.list_teacher_score),
len(self.list_total_score)) - 1
del self.list_sid[sid_index]
del self.list_sname[sid_index]
del self.list_sdept[sid_index]
del self.list_Linux[sid_index]
del self.list_Java[sid_index]
del self.list_Python[sid_index]
del self.list_average_score[sid_index]
del self.list_classmate_score[sid_index]
del self.list_teacher_score[sid_index]
del self.list_total_score[sid_index]
# print(sid_index)
self.tree.delete(self.tree.get_children()[sid_index])
for row in results:
self.list_sid.append(row[0])
self.list_sname.append(row[1])
self.list_sdept.append(row[2])
self.list_Linux.append(row[3])
self.list_Java.append(row[4])
self.list_Python.append(row[5])
self.list_average_score.append(row[6])
self.list_classmate_score.append(row[7])
self.list_teacher_score.append(row[8])
self.list_total_score.append(row[9])
utils.close()
# print("3self.key_name=" + self.key_name)
# 设置表格内容
self.flush()
在搜索框中输入内容后回车确定,自动查找符合条件的对象并进行展示。之前的查询都是使用程序运行时的列表进行操作,但是因为这个功能要按条件搜索,所以要对列表重新赋值并展示
8.使列表的每行数据按顺序排列
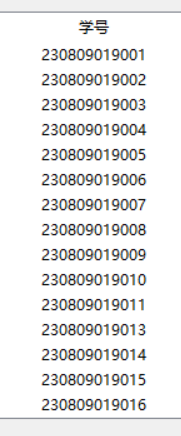
按学号
按分数
def tree_sort_column(self, tv, col, reverse):
flag=True
l = [(tv.set(k, col), k) for k in tv.get_children('')]
# print(l)
for i in l:
# print(i[0])
if not self.is_chinese(i[0]):
flag = False
if flag:
# print("chuchuchuchuchu")
l.sort(key=lambda keys: [pinyin(i, style=Style.TONE3) for i in keys], reverse=reverse)
else:
l.sort(reverse=reverse)
for index, (val, k) in enumerate(l):
# 根据排序后索引移动
tv.move(k, '', index)
# 重写标题,使之成为再点倒序的标题
tv.heading(col, command=lambda: self.tree_sort_column(tv, col, not reverse))
汉字的排序需要使用汉字转拼音库,然后在进行排序
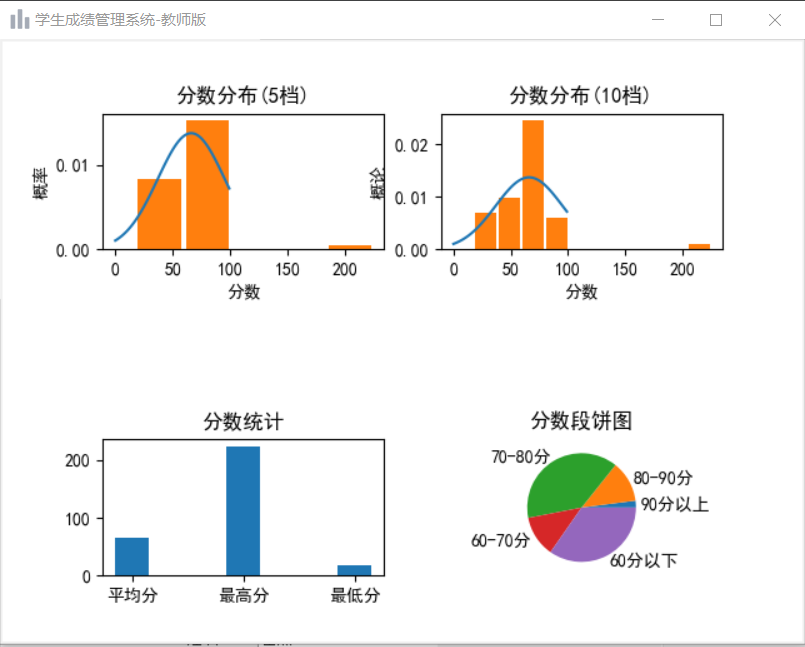
9.班级的成绩分析图表
def analyse(self):
a = 0 # 90分以上数量
b = 0 # 80-90分以上数量
c = 0 # 70-80分以上数量
d = 0 # 60-70分以上数量
e = 0 # 60分以下数量
utils=PyMySQLUtils()
score=utils.fetchall("select average_score from student_score")
score_max = 0
score_min = 100
score_avg = 0
score_sum = 0
score = np.array(score) # 获得分数数据集
student_no = np.array(utils.fetchall("select sid from student_score")) # 获得学号数据集
mean = score.mean() # 获得分数数据集的平均值
std = score.std() # 获得分数数据集的标准差
# 计算分数总和、各分数区间数量统计
for i in range(0, len(score)):
score0 = int(score[i])
# print(student_no[i],score0)
score_sum = score_sum + score0 # 计算分数之和,为求平均数做准备
# 计算最大值
if score0 > score_max:
score_max = score0
# 计算最小值
if score0 < score_min:
score_min = score0
if score0 >= 90: # 统计90分以上数量
a = a + 1
elif score0 >= 80: # 统计80分以上数量
b = b + 1
elif score0 >= 70: # 统计70分以上数量
c = c + 1
elif score0 >= 60: # 统计60分以上数量
d = d + 1
else: # 统计60分以下数量
e = e + 1
score_avg = score_sum / len(score) # 平均分
scores = [a, b, c, d, e] # 分数区间统计
# 柱形图柱形的宽度
bar_width = 0.3
# 设定X轴:前两个数字是x轴的起止范围,第三个数字表示步长,步长设定得越小,画出来的正态分布曲线越平滑
x = np.arange(0, 100, 1)
# 设定Y轴,正态分布函数
y = self.normfun(x, mean, std)
# 设定柱状图x轴、Y轴数组
x3 = np.arange(3)
y3 = np.array([score_avg, score_max, score_min])
plt.subplot(321)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title('分数分布(5档)')
plt.plot(x, y)
plt.hist(score, bins=5, rwidth=0.9, density=True)
plt.xlabel('分数')
plt.ylabel('概率')
# 绘制分数数据集的正态分布曲线和直方图(10分档)
plt.subplot(322)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title('分数分布(10档)')
plt.plot(x, y)
plt.hist(score, bins=10, rwidth=0.9, density=True)
plt.xlabel('分数')
plt.ylabel('概论')
# 绘制柱形图
plt.subplot(325)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title('分数统计')
plt.bar(x3, y3, tick_label=['平均分', '最高分', '最低分'], width=bar_width)
# 绘制饼状图
plt.subplot(326)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title('分数段饼图')
plt.pie(scores, labels=['90分以上', '80-90分', '70-80分', '60-70分', '60分以下'])
# 输出四幅图
plt.savefig('analyse.png')
# 解决覆盖bug
plt.close()
win = Toplevel()
win.iconbitmap('analyseico.ico')
# win.wm_iconbitmap('analyseico.ico')
image = Image.open('analyse.png')
img1 = ImageTk.PhotoImage(image)
a = Label(win, image=img1).pack()
win.mainloop()
统计班级的平均分情况,绘制四张图片并展示到Toplevel中,并设置图标。
10.导出每个学生的成绩分析图表
方便每位同学直到自己和平均分的差距
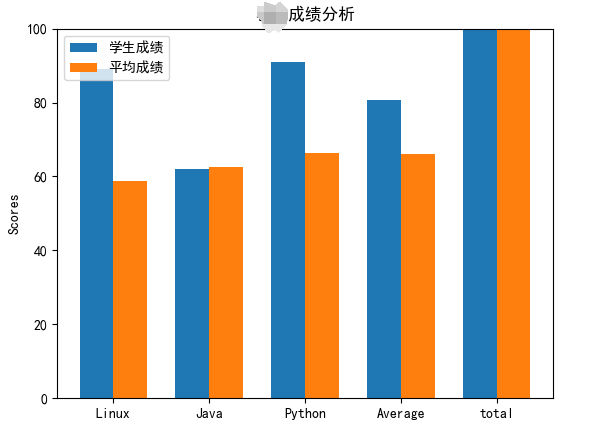
展示了四科比较关键的课和平均分
def get_avg(self)->list:
utils=PyMySQLUtils()
linux_sum=utils.fetchone("select SUM(LINUX) FROM student_score ")
# print(linux_sum)
java_sum=utils.fetchone("select SUM(JAVA) FROM student_score ")
python_avg=utils.fetchone("select SUM(python) FROM student_score ")
avg_avg=utils.fetchone("select SUM(AVERAGE_SCORE) FROM student_score ")
total_avg=utils.fetchone("select SUM(TOTAL_SCORE) FROM student_score ")
size=utils.fetchone("select count(1) FROM student_score ")
utils.close()
return [linux_sum[0]/size[0],java_sum[0]/size[0],python_avg[0]/size[0],avg_avg[0]/size[0],total_avg[0]/size[0]]
def analyse_stu(self):
utils=PyMySQLUtils()
avg_score=self.get_avg()
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 正常显示负号
for i in range(len(self.list_sid)):
stu_score=utils.fetchone("select linux,java,python,average_score,total_score fROm student_score where sid="+self.list_sid[i])
labels = ['Linux', 'Java', 'Python', 'Average', 'total']
x = np.arange(len(labels)) # the label locations
width = 0.35 # the width of the bars
fig, ax = plt.subplots()
rects1 = ax.bar(x - width / 2, stu_score, width, label='学生成绩')
rects2 = ax.bar(x + width / 2, avg_score, width, label='平均成绩')
# Add some text for labels, title and custom x-axis tick labels, etc.
ax.set_ylabel('Scores')
ax.set_title(self.list_sname[i] + "成绩分析")
ax.set_xticks(x)
ax.set_xticklabels(labels)
ax.legend()
plt.ylim((0, 100))
# plt.show()
plt.savefig("./img/{}.png".format(str(self.list_sid[i])+self.list_sname[i]))
plt.close()
messagebox.showinfo("showinfo", "成功导出所有学生成绩分析表")
获得平均分和每个学生的单独成绩,组合成每人独特的图表,便于观察
11.程序的打包
推荐使用anaconda新建一个打包环境,会减少占用的内存

用我之前使用过的打包环境
- activate -name(虚拟环境名字)(进入到该虚拟环境中)

切换盘符到要打包的目录下,要先到根目录才行,直接cd无响应
输入 Pyinstaller -F -w -i ic.ico pyMysql.py
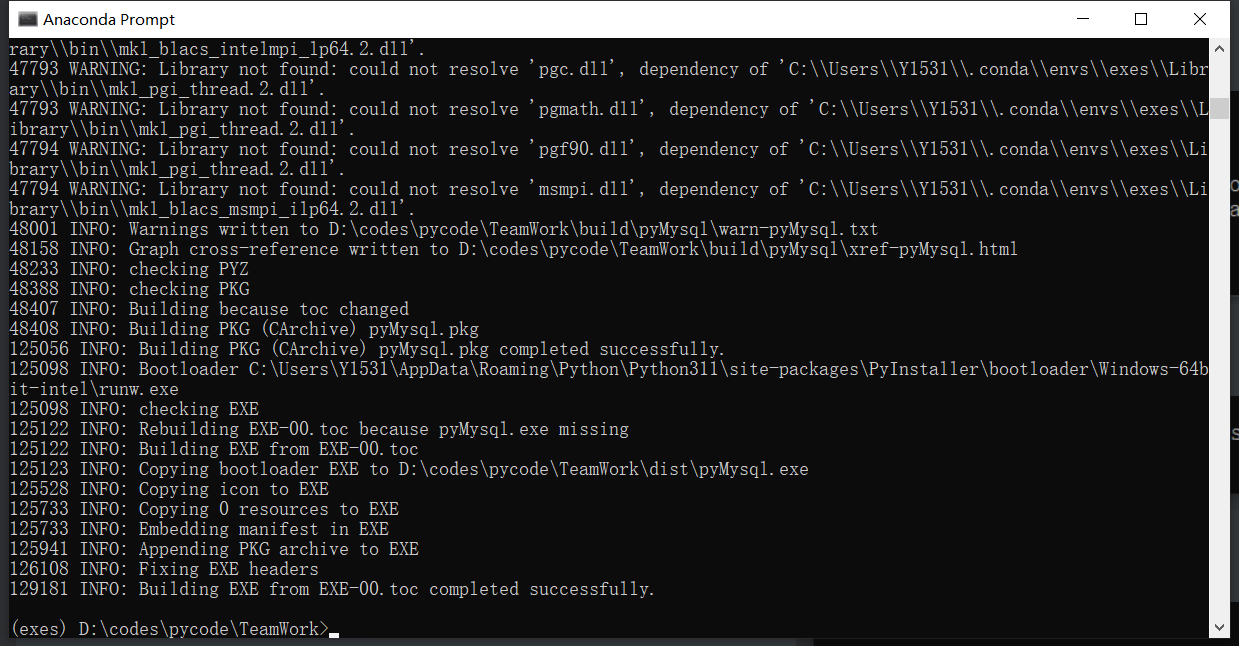

最后在目录下有个dist文件夹,里面就是打包好的exe文件
5程序注意事项
直接打开exe可能会报错
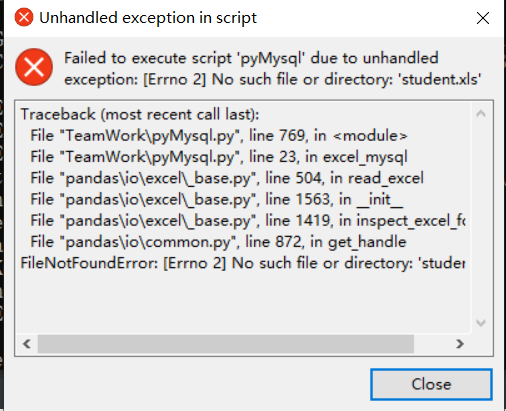
可能是文件的结构出现了问题,可执行文件同级目录必须同时存在
- 学生的成绩表
- 软件的图标文件,文件分析的tu’b
- img文件夹 用于学生成绩分析图的导出
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!