dctcp 可扩展、低时延图解
理想 reno 和理想 dctcp 的单流 cwnd-time 演化图如下:

很直观地展现出 dctcp 锯齿小很多,锯齿小意味着高效。
dctcp 利用交换机反馈而来的 ecn 可精确计算导致排队超过 k 的报文比例,减去这一比例的 inflight 就是合适的。但 dctcp 在 reno aimd 的动态过程之上,实际的多流情况很难在图像上标识,还要结合算术上分析:
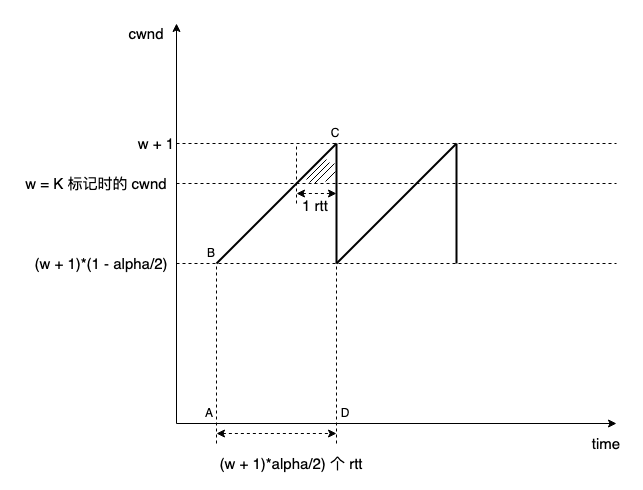
阴影小三角形和梯形 abcd 的面积之比就是 alpha:
1
2
(
(
w
+
1
)
+
(
w
+
1
)
(
1
?
α
/
2
)
)
?
(
w
+
1
)
?
α
/
2
2
=
α
\dfrac{\frac{1}{2}}{\frac{((w+1)+(w+1)(1-\alpha/2))*(w+1)*\alpha/2}{2}}=\alpha
2((w+1)+(w+1)(1?α/2))?(w+1)?α/2?21??=α ,现代网络的 cwnd 不会太小,可忽略 w 低阶项,解得
α
=
2
w
\alpha=\sqrt{\dfrac{2}{w}}
α=w2??,那么 (w + 1) - (w + 1)*(1 - alpha / 2) 就是锯齿的大小,将 alpha 代入,得到:
(
w
+
1
)
?
(
w
+
1
)
?
(
1
?
α
/
2
)
=
2
(
w
2
+
2
w
+
1
)
w
/
2
≈
2
w
2
(w+1)-(w+1)*(1-\alpha/2)=\sqrt{\dfrac{2(w^2+2w+1)}{w}}/2\approx\dfrac{\sqrt{2w}}{2}
(w+1)?(w+1)?(1?α/2)=w2(w2+2w+1)??/2≈22w?? 而对于标准 reno aimd,对应的上述值是
w
+
1
2
\dfrac{w+1}{2}
2w+1? 。简单比较一下二者:
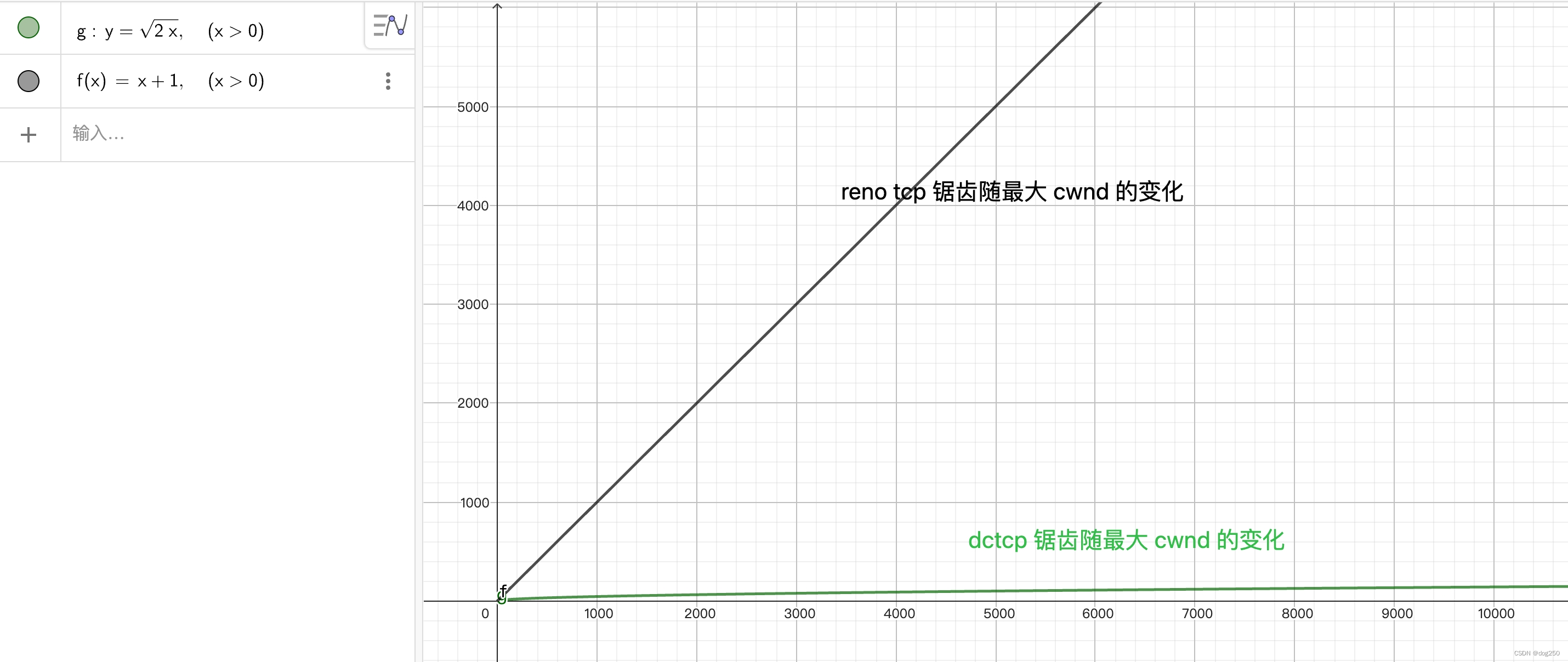
简单的同步流场景,reno tcp 的最大 cwnd = (C * RTT + buffer) / N,而 dctcp 最大 cwnd = (C * RTT + K) / N。虽然只有一字之差,但 dctcp 并非只是 buffer = K 的替代,这正体现在上图的绿线中,这个根号 2w 的关系就来自于 dctcp 交换机反馈的精确信息,而如果没有这个信息,如黑线所示,reno 只能盲目以 0.5 为 md 系数猛降 cwnd 而造成大锯齿,cubic 虽改观,但本质不变。
从上述分解,可得 dctcp 拥塞周期为:
T
d
c
t
c
p
=
2
(
C
?
R
T
T
+
K
)
/
N
2
T_{dctcp}=\dfrac{\sqrt{2(C*RTT+K)/N}}{2}
Tdctcp?=22(C?RTT+K)/N?? ,对应于 reno tcp,拥塞周期为:
T
r
e
n
o
=
C
?
R
T
T
+
B
S
i
z
e
2
N
T_{reno}=\dfrac{C*RTT+BSize}{2N}
Treno?=2NC?RTT+BSize? ,C * RTT 为定值,姑且就让 BSize = K,变化 N,看看 dctcp 和 reno 拥塞周期的区别:

dctcp 的拥塞周期不随 N 变化,也不随 buffer 变化,这是 dctcp 可扩展的一面,另一面,观察队列变化可见排队时延的变化,对于 dctcp,queue 为: N ? ( ( w + 1 ) ? ( w + 1 ) ? ( 1 ? α / 2 ) ) ≈ N ? 2 w 2 = 2 N ( C ? R T T + K ) 2 N*((w+1)-(w+1)*(1-\alpha/2))\approx\dfrac{N*\sqrt{2w}}{2}=\dfrac{\sqrt{2N(C*RTT+K)}}{2} N?((w+1)?(w+1)?(1?α/2))≈2N?2w??=22N(C?RTT+K)?? ,N 为流数量,开个根号就啥也没了,时延相对流的数量变化相当平缓,而对于 reno tcp,queue 完全受 buffer 限制,在 buffer 允许情况下,流数量越多,queue 越长,时延随流数量增加而明显增加。这就是 dctcp 的可扩展性的全部。
从以上分析可自然而然得到 dctcp 低时延结论,再次看 dctcp 和 reno tcp 的 queue 长度变化, Q L d c t c p = 2 N ( C ? R T T + K ) 2 QL_{dctcp}=\dfrac{\sqrt{2N(C*RTT+K)}}{2} QLdctcp?=22N(C?RTT+K)??, Q L r e n o = C ? R T T + B S i z e 2 QL_{reno}=\dfrac{C*RTT+BSize}{2} QLreno?=2C?RTT+BSize? ,将 N 等效为 BSize,可见 dctcp 队列的变化比 reno tcp 慢得多,很小的 K 值保持很小的排队时延就能容忍很宽的 C * RTT 范围,与此能力相对,reno tcp 需要 BSize 线性同步于 C * RTT,如果 C * RTT 很大而没有足够大的 buffer 与之匹配,reno aimd 一下子把 cwnd 降一半,把 inflight 降到不足 C * RTT,带宽将得不到有效利用。
我们发现,dctcp 的结论竟然就是异步 reno aimd 的结论,参见 dcn 交换机 buffer 的平方反比律。
大致就这么多。
如果把 dctcp 搬到广域网,满足 l4s 框架的交换机替代可 ecn 的 dcn 交换机,在 rtt 动态范围很大的广域网场景,配合 rtt-independence 特性解决小 rtt 流量侵略性问题: m × i n c r e a s e m e n t p e r A C K = 1 W v i r t m\times increasement_{perACK}=\dfrac{1}{W_{virt}} m×increasementperACK?=Wvirt?1?,所以, i n c r e a s e m e n t p e r A C K = 1 m 1 W v i r t = 1 m 1 C ? R T T v i r t = 1 m 1 C ? m ? R T T = 1 m 2 1 W increasement_{perACK}=\dfrac{1}{m}\dfrac{1}{W_{virt}}=\dfrac{1}{m}\dfrac{1}{C*RTT_{virt}}=\dfrac{1}{m}\dfrac{1}{C*m*RTT}=\dfrac{1}{m^2}\dfrac{1}{W} increasementperACK?=m1?Wvirt?1?=m1?C?RTTvirt?1?=m1?C?m?RTT1?=m21?W1?,典型的一个 bdp 不变,把宽拉成长的操作。这就是一个低时延,低丢包,可扩展的算法,tcp prague,当然,它才刚起步。
我曾经对减小锯齿的方向不看好,因为我没有想到可以靠网络反馈信息,在纯端到端约束下,纯靠 capacity-search 的 aimd 变体根本无法减小锯齿,当它变钝,它必变长,当它变尖,它必变深,拉扯而已,却始终无法既短又钝,既尖又浅。vegas 在另一个方向也有时延不可扩展的问题难以解决。
随着带宽逐渐丰盈,应用也逐渐丰富,实时应用基本取代了离线应用,人们对时延的要求超过了对带宽的要求,宁取低时延而无需高带宽,带宽和时延的需求是不对称的,正如总量和种类的需求不对称一样,当人们吃饱了时,就无需越来越多的大米小麦了,但对饮食种类的需求是无止境的。
在这背景下,任何阻碍低时延的障碍都应被清除。起初人们认为网络分层模型是一个好模型,当时互操作大于一切,而如今低时延大于一切时,谁还在乎分层。网卡都可以 offloading tcp 了,交换机为什么不能呢。我在前几天评论到,在 rfc9000 quic 之前,人们把 quic 视作应用层,在 rfc9000 之后,quic 就无层了。
浙江温州皮鞋湿,下雨进水不会胖。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 螺丝厂家:螺栓和螺柱的区别
- Cmake(3)——Cmake找文件命令和头文件路径命令
- Vue学习笔记-Vue3对响应式数据的判断
- 【算法题】11. 盛最多水的容器
- windows 导入fiddler .cer证书到android系统系统证书中
- Ubuntu-报错
- 数据集成时表模型同步方法解析
- 前端中级算法题
- 在线答题考试小程序源码系统:既能刷题又可以考试的小程序 带完整的安装代码包以及搭建教程
- RTL8762D initialization of process