大模型理论基础1
发布时间:2024年01月15日
大模型理论基础1
第一章:引言
语言模型
- 自回归语言模型
概率的链式法则:
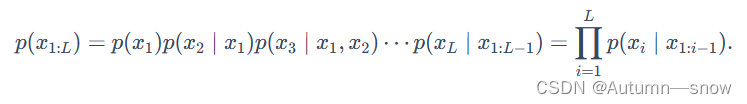
在自回归语言模型 p 中生成整个序列 X1:L,我们需要一次生成一个令牌(token),该令牌基于之前以生成的令牌进行计算获得:
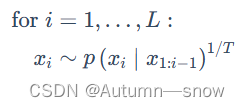
其中T≥0 是一个控制我们希望从语言模型中得到多少随机性的温度参数:
T=0:确定性地在每个位置 i 选择最可能的令牌 xi
T=1:从纯语言模型“正常(normally)”采样
T=∞:从整个词汇表上的均匀分布中采样 然而,如果我们仅将概率提高到 1/T 的次方,概率分布可能不会加和到 1。我们可以通过重新标准化分布来解决这个问题。我们将标准化版本 p T(x i∣x 1:i?1)∝p(xi∣x 1:i?1)1/T称为退火条件概率分布。
N-gram模型
- 语言模型首先被用于需要生成文本的实践应用:噪声信道模型通过贝叶斯定理实现
- 语音识别和机器翻译系统使用了基于词的n-gram语言模型
- n-gram模型被训练在大量的文本上

神经语言模型
- 首次提出了神经语言模型,其中 p(x i ∣x i?(n?1):i?1 ) 由神经网络给出:
p(cheese∣ate,the)=some?neural?network(ate,the,cheese) - Recurrent Neural Networks(RNNs),包括长短期记忆(LSTMs),使得一个令牌x i 的条件分布可以依赖于整个上下文 x 1:i?1(有效地使 n=∞ ),但这些模型难以训练。
- Transformers是一个较新的架构(于2017年为机器翻译开发),再次返回固定上下文长度n,但更易于训练(并利用了GPU的并行性)。此外,n可以对许多应用程序“足够大”(GPT-3使用的是n=2048)。
文章来源:https://blog.csdn.net/Autumn_snow/article/details/135611534
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- web自动化之常见面试题
- 二进制文件操作-读文件
- Matlab实现MPA-BP海洋捕食者算法优化BP神经网络多变量回归预测(多指标、多图)
- 阿里云Alibaba Cloud Linux 3镜像版本清单2024更新
- 掌握 Spring IoC 容器与 Bean 作用域:详解 singleton 与 prototype 的使用与配置
- CSS实用功能
- 电子邮件地址填写指南:格式与常见问题解答
- LabVIEW开发振动数据分析系统
- 将x, y, z 列表变成 [x,y,z]格式
- Python random模块(获取随机数)常用方法和使用例子