语义补全任务2023年论文总结
一、3D Semantic Scene Completion: a Survey
语义场景补全SSC旨在联合估计出一个场景完整的几何和语义信息,假设只需要部分稀疏输入数据。
1、数据集


2、场景表示

Point Cloud,点云是一种方便的、记忆高效的表示方法,它将三维连续世界中的场景几何形状表示为位于其表面上的一组点。与其它表示方式不同的是,点云省略了自由空间的定义并且缺乏几何结构。很少有工作实际上应用了基于点的语义场景补全。在对象上,PCN是第一个处理基于点的补全问题]。然而,场景上点的生成point generation更具挑战性,文献[121,180]需要通过查询给定位置的语义类围绕这个展开研究。
Occupancy Grid,占用网格将场景几何图形编码为一个三维网格,其中单元格描述空间的语义占用。与点云相反,网格方便地定义了相邻单元的邻域,因此使得3D 卷积神经网络的应用更加方便,这有助于将为2D数据设计的深度学习架构扩展到三维数据中。然而,由于同时表示场景的占用区域和非占用区域,导致了很高的内存和计算要求,占用网格表示法受到了约束性的限制和效率方面的缺陷。体素也通常被用作支持我们现在所描述的隐式表面定义。
Implicit surface,隐式曲面将几何图形编码为一个梯度场,表示到最近曲面的有符号距离,称为有符号距离函数(Signed Distance Function,SDF)。而梯度场在本质上是连续的,为了便于实现,它们通常以离散的方式进行编码。梯度场的值是在特定的位置上估计的,通常是在体素中心上,或在点云的点位置上。隐式曲面也可以作为输入,以减少输入数据的稀疏性,以牺牲贪婪的计算为代价的。出于数值原因,大多数工作的编码实际上是一个flipped版本(比如第4.1节中介绍的f-TSDF)。下面详细解释mesh网格可以从implicit surface隐式表面获得,通过使用meshification网格化算法,如行marching cube。
Mesh,网格允许通过一组多边形对场景进行explicit surface显式表面表示。直接在三维网格上实现深度学习算法是具有挑战性的,大多数工作,通过最小化体素内的距离值和应用网格化算法,从中间隐式的基于体素TSDF表示获得网格。其它选择考虑应用文献[59]中的视图或使用参数表面元素,它们更面向对象/形状补全。此外,最近的基于学习的算法,如Deep Marching Cubes,能够从采样良好的点云中端到端获得连续网格,但同样也没有被用于填补大量缺失的信息或场景。
3、框架
3.1、输入
基于三维网格编码?在大多数工作中,3D占用网格(又名Voxel Occupancy)将每个单元格编码为free未被占用的或occupied被占用的。这种表示可以方便地编码为二进制网格,易于压缩(如4.3.4小节所示),但为训练网络提供的输入信号很少。
另一种更丰富的编码方法是使用TSDF(如图6c所示),其中在给定的三维位置(通常是体素中心)上计算到最近表面的带有符号的距离 (符号正负表示在表面的正反面)。TSDF不只在占用网格或点云等测量位置提供输入信号,而是为网络提供更丰富的监控信号。

TSDF编码变体。(b) 投影的TSDF是快速获得的,但依赖于视图。(c) TSDF解决了视图依赖性,但梯度在远离表面的区域更强,它不适合采用基于学习的方法。相比之下,(d) f-TSDF在表面附近的梯度是最强的
3Dpoint cloud点云?尽管这种表示有好处,但最近只有三个SSC相关工作使用点云作为输入编码。在文献[180]中,RGB用于使用RGB特性增强点数据,然而文献[121,122]在顶视图空间中重投影点特征。尽管使用点输入的SSC方法很少,但它还是经常用于对象补全任务。
2D representations二维表示?另外,深度图或距离图像(即2D polar-encoded极编码的激光雷达数据)是存储几何信息的常用二维表示,因此适合于SSC任务的候选对象。事实上,许多工作要么单独表示,要么与其它形式结合使用。与点云表示相反,但与网格表示类似,这种编码使数据进行有意义的连接起来以及与2D CNN的廉价处理。一些工作提出将深度转换为HHA图像,与单通道深度编码相比,它可以保持更有效的信息。其他的非几何模式,如RGB或激光雷达的折射强度,提供了特别有用的推断语义标签的辅助信号。在实践中,一些工作表明,可以直接从深度/距离图像中推断出足够好的语义标签来指导SSC任务。
3.2、架构选择
Volume network体积网络利用3D CNN来卷积体积网格表示,Point-based 基于点网络计算点位置特征,View-Volume 视角体积网络用二维和三维CNN学习数据的2D-3D映射,以及Hybrid network混合网络使用各种网络来组合不同维度的模态数据。
Volume network体积网络?因为便于处理网格数据,3D CNN是语义场景补全SSC任务中使用最流行的(如图7b所示)。由于completion补全任务非常需要上下文信息,因此通常做法使用U-Net架构(如图7所示),即带跳跃连接的编-解码器。后者的好处不仅是提供上下文信息,但也可以启用有意义的coarser场景表示,在SSC中用于输出多尺度预测或启用从粗到细coarse-to-fine的细化。

3D CNN有两个重要的限制:它们的立方式增长的内存需求,以及由于卷积而导致的稀疏输入流形的扩张。
View-Volume 视角体积?为了利用2DCNN的效率,一种常见的策略是将它们与3DCNN结合使用,如图7a所示。从文献中已经确定了两种不同的方案。最常见的是,使用二维CNN编码器从二维纹理/几何输入中提取二维特征(RGB、深度等),然后将其提升到3D,由3DCNN进行处理(如图7a所示,3D骨干网络)。额外的分支和中间融合方案来添加可选的模态数据。简而言之,使用连续的2D-3D CNN方便地有利于不同的相邻定义,因为2D相邻像素可能在三维空间中距离很远,反之亦然,从而提供了丰富的特征表示,以增加处理时间为代价。为了解决这一限制,第二种方案(图7a,2D骨干网络)将3D输入数据投影到2D数据中,然后用正常的2D CNN进行处理明显轻于对应的3D CNN网络。然后将得到的2D特征反投影回3D空间,并使用3D卷积解码,在最终预测之前检索第三维度。后一种方案在计算和内存占用方面无疑较轻,但更适合于户外场景(比如,4.5小节),因为数据显示主要变化是沿着两个轴(即纵向和横向)。

Point-based network基于点的网络?为了最终防止输入数据的离散化,最近的一些工作采用了基于点的网络,如图7c所示。2018年,文献[172]首次提出将permutation-invariant排列不变架构应用于对象补全任务,并取得了良好的结果。然而,由于生成式SSC的点生成容量有限、对固定大小输出的需要和全局特征提取的使用,阻碍了它对生成式SSC的使用。迄今为止,只有SPC-Net仅依赖于基于点的网络,来预测观测点和未观测点的语义。通过假设未观察点的规则分布来规避固定的大小限制,作为一个点分割任务来解决这个问题。总的来说,我们认为基于点的SSC所吸引的工作还太少,是一个可行的研究途径。?

Hybrid networks混合网络?其他一些工作结合了已经提到的架构,我们将其称为混合网络,如图7d所示。一个常见的2D-3D方案通过expert modality专家模态网络将2D和3D特征(如RGB和f-TSDF)结合在一个通过3D CNN解码的公共隐式空间中(如图7d mix-2D-3D所示)。这使得纹理和几何特性的联合使用具有额外的好处。类似地,IPF-SPCNet在初始2D CNN上对RGB图像进行语义分割,并提升图像标签,以增加ad-hoc 3D点(如图7d point-augmented所示)。在文献[121,122]中,PointNet从点的子集编码几何特征,然后以混合架构的方式进行鸟瞰视角(BEV)投影的点(如图7D point-2D所示)。另一种策略是采用并行的2D-3D分支来处理二维投影图像和三维网格中包含的不同邻域定义的相同数据。最近,S3CNet将3D体素化的f-TSDF和正常特征与2D BEV结合起来,将这两种模式通过稀疏编码-解码器网络进行晚期融合(如图7d parallel-2D-3D所示),在户外场景中取得了令人印象深刻的效果。文献[1]提出了一个类似的架构,通过将一个half-known半已知的场景外推到一个完整的已知的场景中,来执行他们所说的scene extrapolation 场景外推。

3.3、设计技巧
3.3.1、上下文感知 Contextual awareness
为了正确地补全场景中缺失的信息,需要从多个尺度中收集上下文信息,从而消除场景中相似对象之间的歧义性。
这使得捕获局部几何细节和高级上下文信息成为可能。实现这一点的一个常见策略是在不同卷积层之间添加skip connection,以聚合来自不同感受野的特征。此外,还可以使用文献[78]中提出的具有多尺度特征融合的serial context aggregation连续上下文聚合,如图8a所示。在文献[137]中,有人提出使用dilated convolution扩张卷积(又名“atrous”)来增加感受野并以较低的计算代价收集上下文信息。这种策略在大多数工作中流行起来。这种卷积只适用于密集的网络(而不是稀疏的网络),即使这样,也只能应用于输入流形扩张后的网络的更深层。在文献[86]中,利用子空间金字塔池化块(ASPP)引入了一个特征聚合模块,使用多尺度特征,其利用了多个带有不同膨胀速率的并行滤波器,如图8c所示。在文献[77]中提供了一个轻量级的ASPP。ASPP模块中的膨胀卷积可以被剩余膨胀块所取代,以增加空间环境和提升梯度流。在文献[19]中提出了一种放大融合特征的Guided Residual Block引导残差块(GRB)和一种通过3D全局池化聚合全局上下文的Global Aggregation全局聚合模块。在文献[177]中提出了一种额外的特征聚合策略,其中multi-context aggregation多上下文聚合通过级联金字塔体系结构实现的,如图8b所示。在文献[22]中,多尺度的特性被聚合了起来一起遵循一个Primal-Dual原始-对偶优化算法,它确保了语义上稳定的预测,并进一步作为学习的正则化器。

3.3.2、位置感知 Position awareness
在不同位置的体素中所包含的几何信息具有很高的变化性,即Local Geometric Anisotropy局部几何各向异性。特别是,一个对象内部的体素是homogeneous同质的,并且很可能属于与它们的邻居具有相同的语义类别。相反,在场景的表面、边缘和顶点上的体素提供了更丰富的几何信息,因为它们的周围环境有更高的差异。为了解决这个问题,PALNet提出了一个Position Aware loss位置感知损失(见4.4.1小节),它包括一个cross entropy loss交叉熵损失和根据其几何各向异性分配的individual voxel weights个体体素权值,提供稍快的收敛速度和可改进的结果。同样地,AM2FNet通过一个额外的交叉熵损失来监督轮廓信息,作为分割的补充线索。
在同样的工作中,EdgeNet计算出Canny边缘,然后与从深度图像中获得的f-TSDF融合。因此,它增加了沿着场景的几何边缘的梯度。此外,RGB边缘的检测可以识别缺乏几何显著性的对象。在文献[33]中使用同样的网络从全景RGB-D图像中预测完整的场景。
类似地,文献[17]通过从输入TSDF预测包含场景边缘的三维草图,从深度信息中引入了一种显式和紧凑的几何嵌入。他们显示了这个feature embedding特征嵌入是resolution-insensitive分辨率不敏感的,它带来了很高的好处,甚至来自于部分低分辨率的观测。
3.3.3、融合测量 Fusion strategies

3.3.4、轻量级设计 Lightweight designs
3.3.5、细化Refinement
评价指标
Joint Semantics-Geometry?SSC的首选度量指标是mean Jaccard Index平均Jaccard指数或者mean Intersection over Union平均交并比(mIoU),它考虑所有语义类的交并比IoU用于预测,而不考虑自由空间。平均交并比mIoU写成:

Geometry only纯几何?由于平均交并比mIoU考虑语义类,因此不包含纯几何重建的质量。因此,Intersection over Union(IoU)交并比,以及Precision准确率和Recall召回率是常用的未占用free/占用occupied二值场景的表示,通过映射所有语义类为occupy占用来获得。
二、MonoScene: Monocular 3D Semantic Scene Completion
这篇论文的主要任务是3D语义场景重建(Semantic Scene Completion,SSC),而且是以单图像输入完成这个目的。框架图如下

1、2D-3D backbone
特征提取方面2D用的是基于EfficientNetB7的预训练模型2D U-Net,3D用的是自定义的浅编解码器,只有两层。通过使用3D ASPP和Softmax层的completion head,从3D UNet输出的特征处理中获得SSC的输出。?
2、Features Line of Sight Projection (FLoSP)
一种将 2D 特征投影到 3D 的方法,对于 2d unet 的多尺度输出特征(1,2,4,8),分别过 1x1 conv,然后将多尺度的特征分别映射到 3d 空间中(映射方式是将 3d voxels 中心投影到 2d 特征上进行采样),最后对多尺度特征分别映射得到的 3d voxel 特征进行加和得到最终输出

3、3D CRP
具体作用是加强学习体素间的关系,
- 学习 n 向体素?体素语义场景关系图,本文 n 为 4,主要包含以下 voxel 类型
- free:至少有一个 voxel 是 free
- similar
- different
- free:至少有一个 voxel 是 free
-
- occupied:所有 voxel 都是 occupied
- similar
- different
- occupied:所有 voxel 都是 occupied

3D Context Relation Prior Layer的具体结构
输入 3d map,经过 ASPP 卷积提升感受野,然后利用 1x1 conv 和 sigmoid 将 3d map 生成 M 组关系矩阵A^m,利用加权交叉熵损失进行训练;关系矩阵与重塑的超体素特征相乘,以收集全局上下文(或者,?A^m中的关系可以通过移除 Lrel 来自我发现(w/o M),即表现为注意力矩阵)



4、损失函数

4.1、Scene-Class Affinity Loss
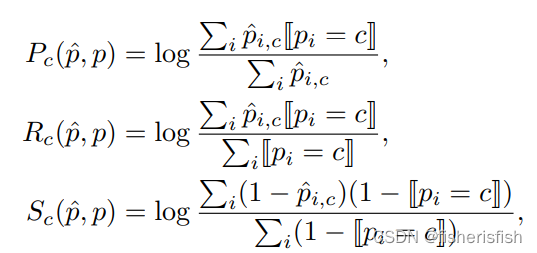

4.2、Frustum Proportion Loss


效果非常好?

三、VoxFormer: Sparse Voxel Transformer for Camera-based 3D Semantic Scene Completion

基于多帧单目图像的3D语义Occupancy预测方法
- 深度估计+占据栅格补全:生成一些类别无关的3D栅格Proposal用于后续query,代码中使用了双目相机进行深度估计,也可以换成单目深度估计
- 基于Deformable Transformer的语义栅格补全3D:栅格Proposal作为query从图像中取特征(Cross Attention),然后Self Attention更新这些特征
- 最后的预测head输出每个栅格是否占据+语义类别
1.1占据栅格补全(类别无关的3D栅格Proposal生成)
这一步主要是选择一些在相机视野内的,比较重要的栅格。主要通过深度估计+占据概率预测的方式实现。具体流程如下:
- 深度估计:使用单目或双目深度估计网络预测每个像素的深度(实验中使用了MobileStereoNet),然后根据相机内参投影和外参投影到世界坐标系中(KITTI中就是雷达坐标系)
- 深度修正(占据概率预测):深度估计直接投影的点云存在很多噪声,因此使用基于3D栅格的occupancy预测网络。具体是将深度投影的点云进行0-1栅格化,然后用3D Unet架构输出栅格分辨率更低的占据预测。(实验中使用了类似LMSCNet的网络。LMSCNet是一个基于激光雷达的3D语义补全方法,实际是将三维占据栅格看成二维图像,按照图像UNet的流程处理,最后转回3D栅格)
- query栅格生成:上一步预测的所有占据栅格作为query栅格
1.2语义栅格补全
主要分为3个部分,query栅格和图像特征的Cross Attention,以及query栅格和其他所有栅格的Self Attention,以及最后的输出。其中attention均采用Deformable Attention(Deformable DETR提出的,BEVFormer也是用的同款)
Deformable Transformer我理解的流程是这样的: 给定Query按照某种方式得到一个参考点,同时经过几个可学习layer得到offset和注意力权重(在此过程中并没有Key)->参考点附近按照offset采样Value -> Transformer的Cross Attention
Deformable Cross Attention?主要是把每一个Query栅格的坐标投影到各帧图像上,投影点作为Deformable Attention的参考点(reference point),参考点附近采样一些点(可学习),这些点对应的图像特征作为Value输入。同一个栅格可能会投到多帧图像上,那么多帧图像的attention输出进行平均,作为最终的输出。
Deformable Self Attention?是把所有栅格(HxWxZ)的特征作为输入,但对于非Query栅格,使用一个mask token替换原有特征。其中Deformable Attention参考点(reference point)为栅格中心坐标。
?损失函数
第一阶段的网络(类别无关的3D栅格Proposal生成)的loss为栅格是否占据的Cross-entropy Loss。
第二阶段的网络(Deformable Attention及输出层)的loss包括:
- 语义类别的Cross-entropy Loss
- MonoScene的Scene-Class Affinity Loss
效果确实更好,但是是序列图像输入,此外需要进行深度估计。
四、OccDepth: A Depth-Aware Method for 3D Semantic Scene Completion

应用双目RGB图像进行 3D场景语义补全,此外还应用了知识蒸馏模块,和monoscene比较类似
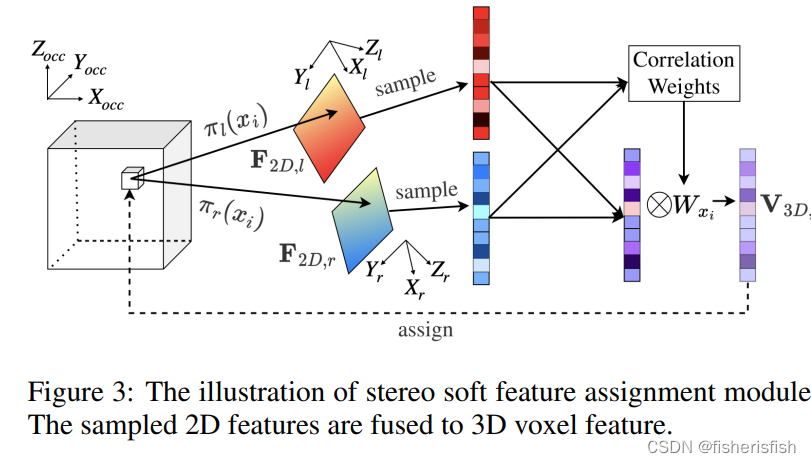
Stereo Soft Feature Assignment Module双目特征软融合模块
和monoscene中的FLoSP类似,都是将二维特征聚合到三维,这里用的双目图像


Occupancy-Aware Depth Module Module Structure?占用感知的深度蒸馏模块
这个模块进行深度预测,同时有蒸馏学习进行辅助

![]()
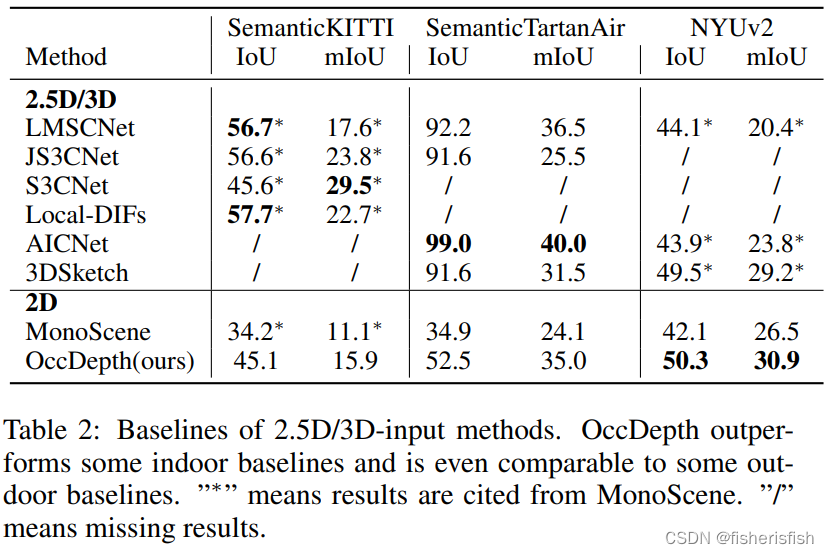
室内场景效果非常优秀?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- ChatGLM基于LangChain应用开发实践(二)
- 介绍 yarn 的安装及使用流程
- sklearn学习的一个例子用pycharm jupyter
- 大语言模型&向量数据库
- main参数传递、反汇编、汇编混合编程
- 了解ansible中的角色
- 当项目出现oom异常,应该如何去排查定位
- 目标检测YOLO实战应用案例100讲-基于双模特征融合的目标检测
- 面试常见问题回答干货
- 提升UI设计水平的关键技能,轻松打造专业形象!