软件测试题常见版
1、python深浅拷贝
- 浅拷贝,指的是重新分配一块内存,创建一个新的对象,但里面的元素是原对象中各个子对象的引用。
- 深拷贝,是指重新分配一块内存,创建一个新的对象,并且将原对象中的元素,以递归的方式,通过创建新的子对象拷贝到新对象中。因此,新对象和原对象没有任何关联。
2、什么是作用域
- 作用域是在运行时代码中的某些特定部分中变量,函数和对象的可访问性。换句话说,作用域决定了代码区块中变量和其他资源的可见性。
- 作用域就是一个独立的地盘,让变量不会外泄、暴露出去。也就是说作用域最大的用处就是隔离变量,不同作用域下同名变量不会有冲突。
3、闭包函数
- 闭包函数指有权访问另一个函数作用域中变量的函数。简单理解就是 ,一个作用域可以访问另外一个函数内部的局部变量。
- 作用:延伸变量的作用范围。
- 闭包有三个特性:
- 函数嵌套函数
- 函数内部可以引用外部的参数和变量
- 参数和变量不会被垃圾回收机制回收
闭包函数就是给函数体传参的一种方式,函数嵌套也就是在函数中定义另一个函数。
闭包函数的特点
闭:定义在函数内部的函数
包:就是内部函数引用了外部函数中的变量因为作用域的原因,在外层函数无法拿到内层函数中的变量和内部函数。所以当需要使用时,要将函数名作为
变量名返回。这是闭包最常用的方式。
4、接口测试开展的时间
-
后端开发写好了接口,但是前端开发没有写好页面的时候,我们提前介入接口测试,提前发现bug,减少功能测试阶段发现更多的bug。
-
接口测试的介入时间:需求评审澄清之后,前后端开发会对接接口文档,达成一致之后已经输出了接口文档。
-
接口测试的测试时间:后端开发把接口开发完成之后,并且达到提测的要求,就可以开始进行接口测试了。
-
接口测试的流程
一、需求评审,熟悉业务和需求
二、开发提供接口文档
三、编写接口测试用例
四、用例评审
五、提测后开始测试
六、提交测试报告
5、测试用例设计如何提高测试覆盖率
1、确保测试需求分析的全面性
2、引入测试设计技术
3、使用自动化测试用例工具
4、测试用例定期评审
5、建立有效测试管理流程
6、结合软件质量的八大特性进行思考
6、怎么保证测试没问题
什么是漏测?具体的说,什么是测试漏测?
测试漏测是指软件产品在测试结束后出现了在测试过程中没有被发现的bug。我们知道,漏测是每一个软件测试者最头疼的事,一旦出现漏测,
首先给客户带来了非常不好的影响,特别是严重的功能性bug被漏测;
其次增加bug修复的成本,包括人力物力财力上;
再者给自己的测试团队也带来了不利影响,容易被别人质疑能力不足,难以取得信任。
不漏侧这个很难避免的,微软的产品都天天打补丁呢,包括google, facebook都经常打补丁。测试人员是没有办法保证不漏侧的,但是尽可能少漏测,而且每次保证漏测的原因都是不一样的。
?如何避免漏测?
-
吃透业务需求
需求评审阶段,产品经理、开发、测试在开会之前,一般都会收到一份需求文档和原型图。在开会前,研读好需求文档后,做好理解不明确和产生歧义的地方,待产品经理组会来讲解需求时,针对不懂的地方进行提问,认真记录。 -
2.提高用例质量
提高用例覆盖率,结合业务设计有效业务场景,保证测试有效性。
-
做好用例评审
测试人员结合用例对需求进行反串讲,把对需求的理解讲一遍,列出所有的测试点和测试场景,产品和开发同事评审是否有遗漏场景,如果没有异议,这样就可以很大程度的避免漏测了。 -
增加交叉测试
? 一个人精力毕竟有限,如果条件和时间允许,可以把测试过的功能交给你的搭档,让他帮忙在测试一下,毕 竟 每个人的测试思路不一样,也许也有收获也不一定呢。
- 有效回归测试
? 梳理主流程用例,尤其随着版本迭代和功能的增加,回顾测试用例极为重要,毕竟每次发版时,要保证主流 程没问题吧,主流程都有问题,难道还敢上线?
-
bug仲裁
在上线前,查看还有哪些问题,是未解决的,与产品、开发、测试经理商量,哪些bug是允许带到线上的,如果三方达成一致,那么线上再出问题,也是已知的,就没什么问题了。 -
做好漏测复盘
对待漏测态度上必须要重视,分析为何会漏测,是哪个环节出了问题,是流程问题还是技术问题?
同样的坑别踩第二次,技术不足的学习补齐,流程不足的规范流程。
把它当做一次提高的机会,也正因为这次机会,让你印象越深刻,能够避免下次不会再犯同样的错误。
- 总结
不得不说一句的是,漏测是不可能绝对避免的,我们能做的只能是尽量减少漏测现象,漏测现象会随着工作经验增加而逐渐减少。
所以测试的时候,一定要仔细、细致、认真,毕竟一次漏测可能会影响很多人,所以万万马虎不得呀。
7、软件交付时间紧,赶着上线怎么办?
1、安排业务熟悉的人做这个紧急版本的测试
2、把版本的的修改点, 新增需求搞清楚,搞清楚这些变更是如何实现的
3、罗列主流程的测试用例(思维导图),优先保证主流程没有问题,然后再发散测试
4、在执行测试过程中,把测试过的点记录下来,这样方便事后检查自己哪些测试点还没有测试到
5、发现bug还是要提交bug,不能因为时间紧,而不提交bug,导致bug遗漏
8、Postman断言(postman获取断言时,任何响应都必须转为JsonData 对象。)
-
在 postman 中我们是在Tests标签中编写断言,同时右侧封装了常用的断言,当然 Tests 除了可以作为断言,还可以当做后置处理器来编写一些后置处理代码,经常应用于:
- 获取当前接口的响应,传递给下一个接口
- 控制多个接口间的执行顺序。
-
常见断言方法
- 1、状态码断言
判断接口响应的状态码:Status code: code is 200 pm.test("Status code is 200", function () { //Status code is 200是断言名称,可以自行修改 pm.response.to.have.status(200); //这里填写的200是预期结果,实际结果是请求返回结果 }); 判断接口响应码是否与预期集合中的某个值一致 pm.test("Successful POST request", function () { pm.expect(pm.response.code).to.be.oneOf([201,202]); //检查响应码是否为201或者202 }); 判断状态码名称(也就是状态码后面的描述)是否包含某个字符串:Status code:code name has string pm.test("Status code name has string", function () { pm.response.to.have.status("OK"); //断言响应状态消息包含OK });- 2、响应内容断言
断言响应体中包含XXX字符串:Response body:Contains string pm.test("Body matches string", function () { pm.expect(pm.response.text()).to.include("string_you_want_to_search"); //pm.response.text() }); 响应结果如果是json,断言响应体(json)中某个键名对应的值:Response body : JSON value check pm.test("Your test name", function () { var jsonData = pm.response.json(); //获取响应体,以json显示,赋值给jsonData .注意:该响应体必须返会是的json,否则会报错 pm.expect(jsonData.value).to.eql(100); //获取jsonData中键名为value的值,然后和100进行比较 }); 断言响应体等于XXX字符串:Response body : is equal to a string pm.test("Body is correct", function () { pm.response.to.have.body("response_body_string"); //获取响应体等于response_body_string });- 3、响应头断言
断言响应头包含:Response headers:Content-Type header check pm.test("Content-Type is present", function () { pm.response.to.have.header("Content-Type"); //断言响应头存在"Content-Type" });=- 4、响应速度断言
判断实际响应时间是否与低于预期时间:Response time is less than 200ms
pm.test("Response time is less than 200ms", function () { pm.expect(pm.response.responseTime).to.be.below(200); });
-
常用断言对应的脚本
--清除一个环境变量 postman.clearEnvironmentVariable("variable_key"); --断言响应数据中是否存在某个元素 tests["//断言返回的数据中是否存在__pid__这个元素"] = responseBody.has("pid"); --断言response等于预期内容 tests["Body is correct"] = responseBody === "response_body_string"; --断言json解析后的key的值等于预期内容 tests["Args key contains argument passed as url parameter"] = 'test' in responseJSON.args --检查response的header信息是否有被测字段 tests["Content-Type is present"] = postman.getResponseHeader("Content-Type"); --校验响应数据中,返回的数据类型 var jsonData = JSON.parse(responseBody);//第一步先转化为json字符串。其中变量(jsonData)可以自行定义...... tests["//data.category.name__valuse的值的类型是不是string"] = typeof(jsonData.data.category[0].name) == "string"; --响应时间判断 tests["Response time is less than 200ms"] = responseTime < 200; --设置环境变量 postman.setEnvironmentVariable("variable_key", "variable_value"); --断言状态码 tests["Status code is 200"] = responseCode.code != 400; --检查响应码name tests["Status code name has string"] = responseCode.name.has("Created"); --断言成功的post请求返回码 tests["Successful POST request"] = responseCode.code === 201 || responseCode.cod
9、MySQL索引
什么是索引?请简述常用的索引有哪些种类?
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。如果想按特定职员的姓来查找他或她,则在表中搜索所有的行相比,索引有助于更快地获取信息
通俗的讲,索引就是数据的目录,就像看书一样,假如我想看第三章第四节的内容,如果有目录,我直接翻目录,找到第三章第四节的页码即可。如果没有目录,我就需要将从书的开头开始,一页一页翻,直到翻到第三章第四节的内容。
InnoDB:支持 B-tree,Full-text 等索引,不支持 Hash 索引;
MyISAM:支持 B-tree,Full-text 等索引,不支持 Hash 索引;
Memory:支持 B-tree,Hash 等索引,不支持 Full-text 索引;
NDB:支持 Hash 索引,不支持 B-tree、Full-text 等索引;
Archive:不支持 B-tree、Hash、Full-text 等索引;
10、postman接口关联(提取数据—验证—放入数据----执行 )
-
方法一:使用json提取器实现接口关联
-
方法二:使用正则表达式提取器实现接口关联
-
方法三:使用cookie提取器实现接口关联(通过cookie来取值)
11、OSI七层协议各层详解
OSI七层协议(Open System Interconnection reference model)是一个由国际标准化组织(ISO)提出的标准通信协议体系结构,该体系结构把计算机网络体系结构的各个方面分割成了七个不同的抽象层,每一层都有各自的通信功能。OSI七层协议由上往下依次为:
1.物理层(Physical Layer)
物理层是位于通信系统底层的协议层,主要负责把比特流转化为可以在物理介质上传输的物理信号。物理层主要涉及数据传输的物理介质、机械电气特性、接口标准、传输速率和数据传输距离等问题。
2.数据链路层(Data-Link layer)
数据链路层主要建立在物理层之上,是建立与当地网络协议所规定的接口进行通信的实体层。它定义了如何让类似的网络接口通信,并指定当网络层出现错误时,如何进行检测和纠正。数据链路层一般包括两个子层:逻辑链路控制(LLC)和介质访问控制(MAC)。
3.网络层(Network Layer)
网络层主要用于在不同网络之间进行数据传送和路由选择,通过网络地址来实现通信。主要协议有IP(Internet Protocol)协议、ICMP(Internet Control Message Protocol)协议、IGMP(Internet Group Management Protocol)协议、OSPF(Open Shortest Path First)协议等。
4.传输层(Transport Layer)
传输层负责对网络通信质量进行管理,可以为应用程序提供良好的数据传输服务。主要协议有TCP(Transmission Control Protocol)和UDP(User Datagram Protocol)。
5.会话层(Session Layer)
会话层主要负责建立、管理和终止会话连接,提供端到端的数据传输流控制和同步服务。主要协议有RPC(Remote Procedure Call)协议、NCP(NetWare Core Protocol)协议等。
6.表示层(Presentation Layer)
表示层用于处理交换数据的表示方式,例如数据压缩、加密、解密等操作。主要协议有ASCII、EBCDIC、JPEG、GIF等。
7.应用层(Application Layer)
应用层主要用于提供给用户的网络服务。例如:FTP(File Transfer Protocol)协议、HTTP(Hyper Text Transfer Protocol)协议、SMTP(Simple Mail Transfer Protocol)协议、SSH(Secure Shell Protocol)协议以及DNS(Domain Name System)协议等。
计算机网络七层协议的功能:
计算机网络的七层协议是一个分层的通讯协议体系结构,每一层都定义了不同的功能,便于开发和实现网络通讯的标准化和互操作性。各层的主要功能如下:
1.物理层(Physical Layer):传输比特流,定义能传输的电气和物理特性。
2.数据链路层(Data Link Layer):传输帧,定义帧的格式、检测和控制差错,以及媒体访问控制。
3.网络层(Network Layer):地理位置传输,实现不同网络间的路由选择和数据传输。
4.传输层(Transport Layer):端到端传输,提供可靠的传输服务,例如 TCP 协议。
5.会话层(Session Layer):建立、管理和终止会话连接,提供端到端的数据传输流控制和同步服务。
6.表示层(Presentation Layer):处理交换数据的表示方式,例如数据压缩、加密、解密等操作。
7.应用层(Application Layer):提供特定的应用服务,例如文件传输、电子邮件、Web浏览等。
12、测试用例模板

13、怎么测试一个接口
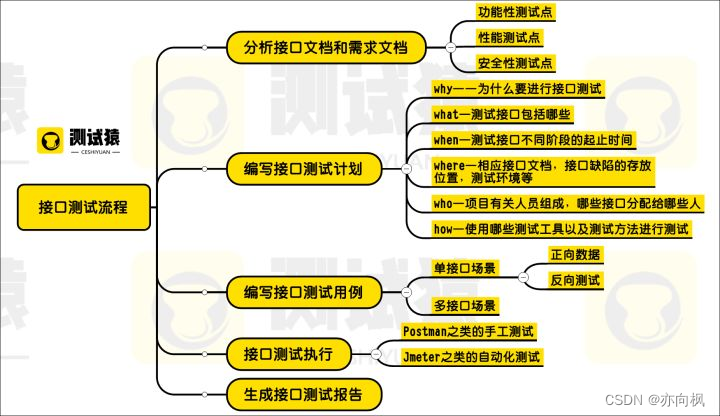
1、分析接口文档和需求文档
分析接口文档或者需求文档一般会去找测试点,那么接口测试的测试点我们一般从几种方向去找
· 功能性测试点
· 性能测试点
· 安全性测试点
2、编写接口测试计划
测试计划就是功能测试计划基本一样就是知名的5w1h了
- why——为什么要进行接口测试;
- what—测试接口包括哪些;
- when—测试接口不同阶段的起止时间;
- where—相应接口文档,接口缺陷的存放位置,测试环境等;
- who—项目有关人员组成,哪些接口分配给哪些人;
- how—使用哪些测试工具以及测试方法进行测试。
3、编写接口测试用例
测试用例就是根据具体的哪个接口来编写,一般会分为单接口和多接口两种场景来编写测试用例
- 单接口场景的测试
正向数据:也就是能正常发送请求,正常获取响应的数据,一般我们从三个方面去组织:
所有必填参数
全部参数(必填参数+选填参数)
参数组合(必填参数+某些选填参数)
反向测试:用不属于规定范围的数据区发送请求检查服务器能否正常处理
异常数据:数据为空,长度过多或者过少(边界值外),类型不符(需要数字类型传递str类型),错误的数据
异常的参数:不传参数,少传参数,多传参数,传递错误的参数
异常的业务数据:结合业务功能考虑输出的各种异常返回情况
2) 多接口场景的测试
业务场景功能测试(站在用户角度考虑常用的使用场景)
多业务场景功能测试主要是测试接口之间数据依赖
4、接口测试执行
根据设计的测试用例就可以执行测试用例当然执行的方式有几种
-
使用postman之类的工具,一个一个进行测试,这种方式我们叫做手工测试
-
使用jmeter之类的有自动化功能方式进行测试,这种叫做工具自动化测试
-
我们可以自己编写测试脚本,使用测试脚本自动加载测试,这种就是自动化测试了
5、生成接口测试报告。
测试完成了以后就可以生成测试报告了
14、GET和POST请求的区别
(1)post更安全(不会作为url的一部分,不会被缓存、保存在服务器日志、以及浏览器浏览记录中)
(2)post发送的数据更大(get有url长度限制)
(3)post能发送更多的数据类型(get只能发送ASCII字符)
(4)post比get慢
(5)post用于修改和写入数据,get一般用于搜索排序和筛选之类的操作(淘宝,支付宝的搜索查询都是get提交),目的是资源的获取,读取数据.
总结:GET把参数包含在URL中,POST通过request body传递参数,所以Post更加安全一些;Get的效率比Post高一些,但是Get请求发送的参数是有限的,而Post请求是没有限制的(理论上来讲)。
15、jmeter的使用
- 添加线程组
- 添加HTTP请求
- 添加查看结果树
- 看查看结果树的返回
16、测试方法
-
常用的黑盒测试方法有:等价类划分法;边界值分析法;因果图法;场景法;正交实验设计法;判定表驱动分析法;错误推测法;功能图分析法。
-
常用白盒测试方法:
静态测试:不用运行程序的测试,包括代码检查、静态结构分析、代码质量度量、文档测试等等。它可以由人工进行,充分发挥人的逻辑思维优势,也可以借助软件工具(Fxcop)自动进行。
动态测试:需要执行代码,通过运行程序找到问题,包括功能确认与接口测试、覆盖率分析、性能分析、内存分析等。
白盒测试中的逻辑覆盖包括语句覆盖、判定覆盖、条件覆盖、判定/条件覆盖、条件组合覆盖和路径覆盖。六种覆盖标准发现错误的能力呈由弱到强的变化:
1.语句覆盖:每条语句至少执行一次。
2.判定覆盖:每个判定的每个分支至少执行一次。
3.条件覆盖:每个判定的每个条件应取到各种可能的值。
4.判定/条件覆盖:同时满足判定覆盖和条件覆盖。
5.条件组合覆盖:每个判定中各条件的每一种组合至少出现一次。
6.路径覆盖:使程序中每一条可能的路径至少执行一次。
17、B/S,C/S架构的优缺点
1、B/S架构的优点:
①、具有分布性特点,可以随时随地进行查询,浏览等业务处理;
②、业务扩展简单方便,通过增加网页即可增加服务器功能;
③、维护简单方便,只需要改变网页,即可实现所有用户的同步更新;
④、开发简单,共享性强。
2、B/S架构的缺点:
①、在跨浏览器上B/S架构不尽如人意;
②、表现要达到C/S程序的程度要花费不少的精力;
③、在速度和安全性上需要花费巨大的设计成本,这是B/S架构的最大问题;
④、客户端服务端的交互是请求-响应模式,需要刷新页面;
3、C/S架构的优点:
①、C/S架构的界面和操作可以很丰富;
②、安全性能可以很容易保证,实现多层认证也不难;
③、由于只有一层交互,因此响应速度较快;
4、C/S架构的缺点:
①、适用面窄,通常用于局域网中。
②、用户群固定。由于程序需要安装才可使用,因此不适合面向一些不可知的用户。
③、维护成本高,发生一次升级,则所有客户端的程序都需要改变。
简单的说:b/s:分布性强、开发简单、共享性强、维护方便;c/s:速度快、体验佳、处理能力强
18、jmeter中的事务
- 事务是用户自定义的一个标识,是一个或多个操作完成一个业务所花费的时间,事务时间反映的是一个操作过程的响应时间
19、jmeter怎么参数化批量操作
-
1、用户定义的变量(User Defined Variables)
用于存放不需要随迭代发生改变的参数(只取一次值的参数),比如host、端口号、url
-
2、CSV Data Set Config
同一个变量有多组值时,可以使用这种方式,比如验证多个用户登录。
-
函数助手
测试过程中,需要生成一些随机变量,比如订单号不能重复,可以用函数助手常用的几个函数来生成。引用的时候直接引用函数的表达式即可
__Random随机数,填写最小值和最大值,点击生成即可生成函数表达式
? __time获取当前时间
-
4、用户参数(User Parameters)
这个方式和CSV Data Set Config有着异曲同工之妙
-
5、正则表达式提取器
测试过程中,会遇到token动态变化/需要从上个接口的返回取值的情况
-
6、json提取器
20、什么时候开始性能测试?
1.功能测试已完成,系统能够正常运行;
2.已经了解了性能测试的基本指标(磁盘,内存,cpu,io);
3.了解所测系统的接口文档;
4.确保压力测试在测试环境下进行;


性能测试有关术语是什么意思?
(1)负载:模拟业务操作对服务器造成压力的过程,比如模拟100个用户进行发帖。
(2)性能测试(Performance Testing):模拟用户负载来测试系统在负载情况下,系统的响应时间、吞吐量等指标是否满足性能要求。
(3)负载测试(Load Testing):在一定软硬件环境下,通过不断加大负载(不同虚拟用户数)来确定在满足性能指标情况下能够承受的最大用户数。简单说,可以帮我们对系统进行定容定量,找出系统性能的拐点,给予生产环境规划建议。这里的性能指标包括TPS(每秒事务数)、RT (事务平均响应时间)、CPUUsing (CPU利用率)、 Mem Using(内存使用情况)等软硬件指标。从操作层面上来说,负载测试也是一种性能测试手段,比如下面的配置测试就需要变换不同的负载来进行测试。
(4)配置测试(Configuration Testing):为了合理地调配资源,提高系统运行效率,通过测试手段来获取、验证、调整配置信息的过程。通过这个过程我们可以收集到不同配置反映出来的不同性能,从而为设备选择、设备配置提供参考。
(5)压力度测试(Stress Testing):在一定软硬件环境下,通过高负载的手段来使服务器资源(强调服务器资源,硬件资源)处于极限状态,测试系统在极限状态下长时间运行是否稳定,确定是否稳定的指示包括TPS、RT、CPU Using、Mem Using等。
(6)稳定性测试(Endurance Testing):在一定软硬件环境下,长时间运行一定负载,确定系统在满足性能指标的前提下是否运行稳定。与上面的压力度测试区别在于负载并不强调是在极限状态下(很多测试人员会持保守观念,在测试时会验证极限状态下的稳定性),着重的是满足性能要求的情况下,系统的稳定性、比如响应时间是否稳定、TPS是否稳定。一般我们会在满足性能要求的负载情况加大1.5到2倍的负载量进行测试。
(7)TPS:每秒完成的事务数,通常指每少成功的事务数,性能测试中重要的综合性性能指标。一个事务是一个业务度量单位,有时一个事务会包括多个子操作,但为了方便统计,我们会把这多个子操作计为一个事务。比如笔电子支付操作,在后台系统中可能会经历会员系统、账务系统、支付系统、会计系统、银行网关等,但对于用户来说只想知道整笔支付花费了多长时间。
(8) RT/ART (Response Timelavernge Response
Time):响应时间平均响应时间,指一个事务花费多长时间完成(多长时间响应客户请求),为了使这个响应时间更具代表性,会统计更多的响应时间然后取平均值,即得到了事务平均响应时间(ART),为了方便大家通常会直接用RT来代替ART, ART 与RT是代表同一个意思。
(9) PV (Page View):每秒用户访问页面的次数,此参数用来分析平均每秒有多少用户访问页面。(10) Vuser 虚拟用户(Virtual user):模拟真实业务逻辑步骤的虚拟用户,虚拟用户模拟的操作步骤都被记录在虚拟用户脚本里。Vuser脚本用于描述Vuser在场景中执行的操作。
(11)Concurreney并发,并发分为狭义和广义两类。狭义的并发,即所有的用户在同具时刻做同一一件事情或操作,这种操作一般针对同一类型的业务,或者所有用户进行完全一样的操作,目的是测试数据库和程序对并发操作的处理。广义的并发,即多个用户对系统发出了请求或者进行了操作,但是这些请求或操作可以是不同的。对整个系统而言,仍然有很多用户同时进行操作。狭义并发强调对系统的请求操作是完全相同的,多适用于性能测试、负载测试、压力测试、稳定性测试场景;广义并发不限制对系统的请求操作,多适用于混合场景、稳定性测试场景。
(12)场景(Scenario):性能测试过程中为了模拟真实用户的业务处理过程,在LoadRunner中构建的基于事务、脚本、虚拟用户、运行设置、运行计划、监控、分析等的一系列动作的集合,称之为性能测试场景。场景中包含了待执行脚本、脚本组、并发用户数、负载生成器、测试目标、测试执行时的配置条件等。
(13) 思考时间(Think Time):模拟正式用户在实际操作时的停顿间隔时间。从业务的角度来讲,思考时间指的是用户在进行操作时,每个请求之间的间隔时间。在测试脚本中,思考时间体现为脚本中两个请求语句之间的间隔时间。
(14)标准差(Std. Deviation):该标准差根据数理统计的概念得来,标准差越小,说明波动越小,系统越稳定,反之,标准差越大,说明波动越大,系统越不稳定。包括响应时间标准差、TPS标准差、Running、Vuser 标准差、Load 标准差、CPU资源利用率标准差、WebResources 标准差等。举例响应时间标准差。
21、Redis支持哪几种数据类型?
答:Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
还有一些数据结构如HyperLogLog、Geo、Pub/Sub等,我们也最好知道,另外像Redis Module,像BloomFilter,RedisSearch,Redis-ML等,能有个印象,哪怕知其然不知其所以然也比听都没听过好点。
22、数据库的存储过程
存储过程(Stored Procedure)是一组为了完成特定功能的SQL语句集。经编译后存储在数据库中。存储过程是数据库中的一个重要对象,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是由流控制和 SQL语句书写的过程,这个过程经编译和优化后存储在数据库服务器中。存储过程可由应用程序通过一个调用来执行,而且允许用户声明变量。同时,存储过程可以接收和输出参数、返回执行存储过程的状态值,也可以嵌套调用。
23、常用状态码
一、1开头的状态码(信息类)
100,接受的请求正在处理,信息类状态码
二、2开头的状态码(成功类)
2xx(成功)表示成功处理了请求的状态码
200(成功)服务器已成功处理了请求。
三、3开头的状态码(重定向)
3xx(重定向)表示要完成请求,需要进一步操作。通常这些状态代码用来重定向。
301,永久性重定向,表示资源已被分配了新的 URL
302,临时性重定向,表示资源临时被分配了新的 URL
303,表示资源存在另一个URL,用GET方法获取资源
304,(未修改)自从上次请求后,请求网页未修改过。服务器返回此响应时,不会返回网页内容
四、4开头的状态码(客户端错误)
4xx(请求错误)这些状态码表示请求可能出错,妨碍了服务器的处理
400(错误请求)服务器不理解请求的语法
401表示发送的请求需要有通过HTTP认证的认证信息
403(禁止)服务器拒绝请求
404(未找到)服务器找不到请求网页
五、5开头的状态码(服务器错误)
5xx(服务器错误)这些状态码表示服务器在尝试处理请求时发生内部错误。这些错误可能是服务器本身的错误,而不是请求的错误
500,(服务器内部错误)服务器遇到错误,无法完成请求
503,表示服务器处于停机维护或超负载,无法处理请求
24、ll和ls的区别
"ls"是列出文件和目录的基本命令,而"ll"是"ls -l"的缩写,用于以长格式列出文件和目录的详细属性信息。
25、接口测试用例模板

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 使用FinalShell连接Linux系统
- MySQL第九讲·索引怎么提高查询的速度?
- 【51单片机】如何利用PZ-ISP将代码烧入到51单片机?
- 人工智能起源哪个国家?
- Sobit:将BRC20资产桥接到Solana ,加速铭文市场的火热
- 秒级弹性!探索弹性调度与虚拟节点如何迅速响应瞬时算力需求?
- 51单片机之LED灯
- 【uniapp】 uniapp 修改tabBar图标大小和navigationBar字体大小
- 一篇文章告诉你为什么要使用MybatisPlus框架
- 鸿蒙HarmonyOS-图表应用