10个得心应手的数据网站,助你完成数据科学项目
本文将介绍10个获取所需数据的网站,助力数据科学项目。
当你的数据对你来说很枯燥或毫无意义时,要激励自己学习数据科学,或做数据科学项目真的很困难。
本文将介绍10个得心应手的网站,在这些网站上你可以为数据科学项目获取一些非常棒的数据。本文的目的是为了展示各种可能吸引你的数据。最终,这些网站应该能帮助你找到你关心的数据,做一个很酷的数据科学项目,并以此来获得一份工作。
如何审查数据源?
如果你在本文中看到一个网站,那是因为它包含的数据是:
-
免费提供。你不需要为它付费。
-
面向社区。它不仅仅是一个文件;会有一些评论和解释。
-
干净的。你可以练习数据科学的有趣部分——分析、可视化、共享等等。
-
与语言无关。你可以用Python、R、SQL或你喜欢的任何其他语言来深入研究这些内容。
10个网站为你的数据科学项目获取很棒的数据
让我们来挖掘一下最好的网站,以找到你真正关心并想用数据科学来探索的数据。
| 网站 | 特点 |
|---|---|
| Google Dataset Search | 超级广泛,质量不一 |
| Kaggle | 更为有限,但有很多背景和社区 |
| KDNuggets | 专门针对AI、ML、数据科学的网站 |
| Government websites | 种类繁多,学习资源丰富 |
| Pudding.cool | 流行文化、散文 |
| 538 | 体育、政治、清洁数据 |
| Tidy Tuesdays | 混乱的数据,伟大的社区 |
| GitHub | 大量的可搜索数据,有评论,质量不一 |
| Buzzfeed | 流行文化、散文、严谨的科学 |
| Awesome Public Datasets | 种类繁多,只有数据集,没有评论 |
技术交流&材料获取
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
资料干货、资料分享、数据、技术交流提升,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:dkl88194,备注:来自CSDN + 资料
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复: 资料
1、数据分析实战宝典

2、100个超强算法模型
我们打造了《100个超强算法模型》,特点:从0到1轻松学习,原理、代码、案例应有尽有,所有的算法模型都是按照这样的节奏进行表述,所以是一套完完整整的案例库。
很多初学者是有这么一个痛点,就是案例,案例的完整性直接影响同学的兴致。因此,我整理了 100个最常见的算法模型,在你的学习路上助推一把!

1. Google’s Dataset Search
链接:https://datasetsearch.research.google.com/
实际上这并不是一个真正的数据集的网站,而是一个数据集的搜索引擎。但它太好了,必须包括在内。
Google的数据集搜索就像Google一样,但针对的是数据集。你输入你的查询,Google就会返回它所拥有的关于该主题的尽可能多的数据集。
例如,搜索“猫”会给我带来一百多个数据集,其中一个数据集包含9000多张猫的图像。
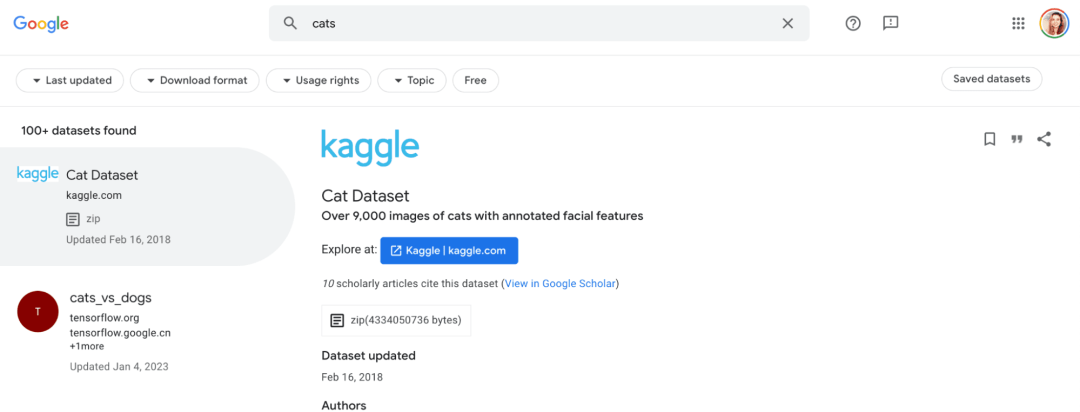
来源:Google Dataset Search
推荐这个网站的原因:
-
它的用途超级广泛。你几乎肯定会找到你关心的东西。
-
它是即时适用的。这个网站包括其他使用过这个数据集的论文,所以你可以看到其他人已经用这个数据做了什么有趣的事情。
-
你可以切换到只包括免费数据集。
-
它为你提取了背景,所以你会得到一些关于这个数据集是什么以及为什么收集它的解释。
这是一个很好的开始。
2. Kaggle
链接:https://www.kaggle.com/datasets
Kaggle的Datasets也是一个搜索引擎,但它的局限性更大,也更有针对性。
它更有局限性,因为它只包含人们在Kaggle发布的数据集。但它更有针对性,因为这些数据集并不是Google随意搜罗的数字集。Kaggle是一个数据科学竞赛的场所,所以它收集的数据集与数据科学极为相关。
这使得你可以根据自己的特定兴趣进行筛选。例如,如果我在启用“计算机视觉”过滤器的情况下搜索“猫”,我可能会偶然发现同一个猫数据集。
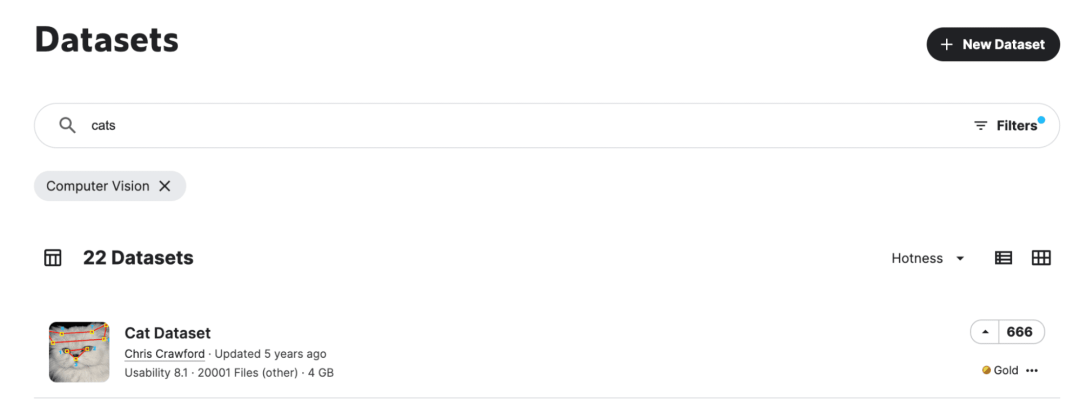
来源:Kaggle Datasets
推荐这个网站的原因:
-
社区方面是如此强大。点击那只猫的数据集,可以看到其他六个人在询问关于这个数据集的问题——并且得到了答案。
-
很多示例项目。你还可以看到其他人围绕这个数据建立或编码的内容。
-
你也可以反其道而行之——查看他们的比赛,看看是否有你感兴趣的东西,然后使用配套的数据集。
3. KDNuggets
链接:kdnuggets.com/datasets/index.html
KDNuggets策划了一套庞大的数据集,这些数据集专门用于数据科学、机器学习、AI和分析,非常好用。
其中许多不是KDNuggets的独家产品,但这是一个很好的列表,可以在其中探究。值得注意的是,当你注册成为KDNuggets的电子邮件订阅者时,你也可以访问World Data AI(https://worlddata.ai/partners/kdnuggets),它本身包含35亿个数据集。
来源:KDnuggets Datasets
推荐这个网站的原因:
-
专门针对数据科学的数据。这些数据集中有许多是为其他目的而策划的,但这些数据集都是专门为AI、机器学习和数据科学而设的。
-
对每个数据集的快速描述。仅仅是一点点的背景,以帮助你决定它是否是适合你的数据集。
4. Government websites
可以很容易地将获取政务数据集的网站清单扩大到大约一百万个,这里提供一个小清单:
-
http://datasf.org/
-
http://data.gov.uk
-
https://www.usa.gov/About/developer-resources/1usagov.shtml
-
https://www.census.gov/data/datasets.html
各国政府不断收集数据进行研究,其中许多政府在网上公布这些数据。

推荐这些网站的原因:
-
这些数据是用于研究的,所以它通常是相当干净和有组织的。
-
这些数据有一个真实的使用案例。有人为了一个真正的、与政府有关的真实原因而收集它。
-
这通常是非常最新的数据。
-
围绕着这些数据往往有一些很酷的故事。
-
许多政府已经投入资源向你展示如何访问或使用这些数据,如人口普查局。
5. Pudding.cool
链接:https://pudding.cool/2023/01/lit-canon/
如果你喜欢让数据紧随流行文化,那么Pudding.cool就是最佳选择。这个网站关注的话题多种多样,如重复的流行歌词、女性的口袋,以及《生活大爆炸》多么受欢迎。
这更像是一本数字杂志,撰写关于文化的长篇文章,同时在旁边展示大量的数据。我把它放在这里,是因为他们讲述了很棒的故事并分享了他们的数据。

来源:The Pudding
推荐这个网站的原因:
-
很棒且有趣的数据。
-
分享数据和脚本。
-
很多你可能关心的东西都是IRL。
6. 538
链接:https://data.fivethirtyeight.com/
另一个以论文为导向的流行文化网站,提供你可以使用的免费数据。他们更专注于体育和政务。
来源:FiveThirtyEight Data
推荐这个网站的原因:
-
有数据支持的智能故事,你可以深入研究。
-
数据采用干净的CSV格式。
-
数据来源高度可靠。
7. Tidy Tuesdays
链接:https://github.com/rfordatascience/tidytuesday
Tidy Tuesdays本身并不完全是一个包含数据集的网站,但它是一个每周一次的活动和社区,重点是使用数据科学来探索杂乱的数据。
每周都会推出一个新的数据集。鼓励参与者在GitHub和Twitter上互相分享他们的清理技术和可视化效果。
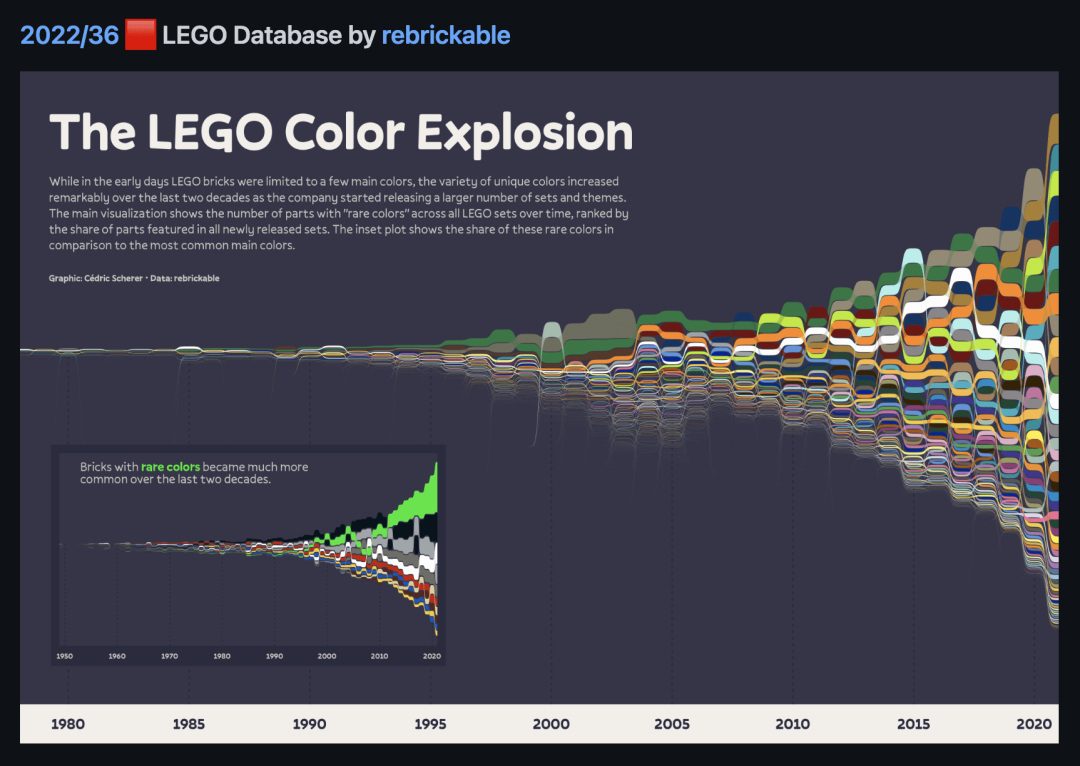
来源:TidyTuesday GitHub
推荐这个网站的原因:
-
这个社区是令人难以置信的。每周你都能学到新东西。
-
它是如此方便。不用去寻找数据集,获取每周的投放。
-
具有挑战性的、不整齐的数据。你在IRL中得到的数据很少会像这个列表中的其他数据那样经过消毒处理。Tidy Tuesdays帮助你学习如何处理混乱的数据。
8. GitHub
链接:https://github.com/
GitHub上有大量数据。你可以很轻松地搜索、过滤和下载数据,以便自己使用。然而,数据的质量参差不齐。因为任何人都可以上传数据,所以数据的状况并不总是很好。
但是,我觉得它的好处弥补了这一点。
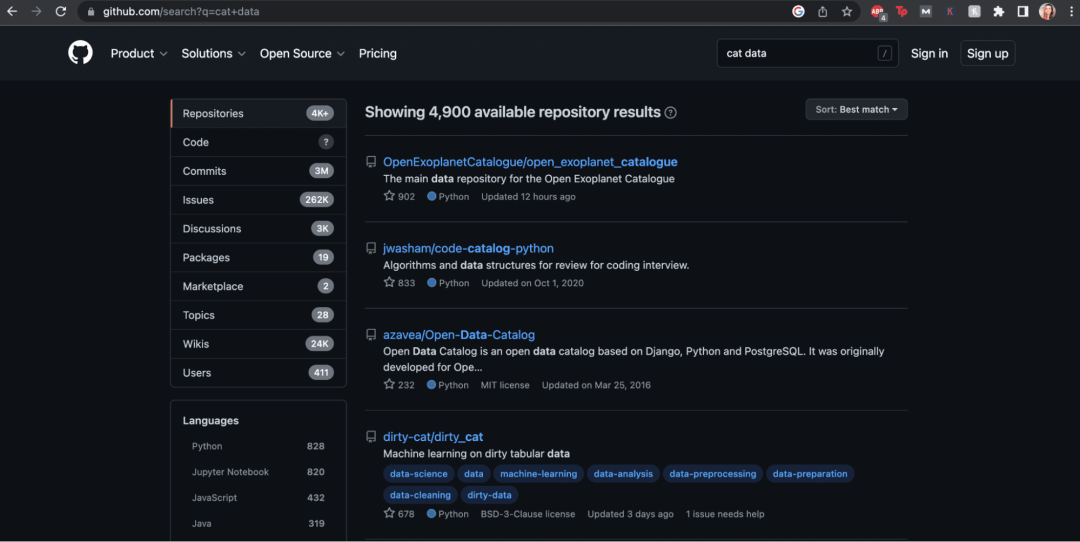
来源:GitHub Cat Data
推荐这个网站的原因:
-
你可以按语言过滤,如Python、Javascript或其他语言。
-
这里有大量的数据。
-
通常这些数据都带有某种评论或代码,你可以查看。
9. Buzzfeed
链接:https://github.com/BuzzFeedNews
Buzzfeed并不只是做一些通过让你做salad来评论人类状况的测验。Buzzfeed可能在这方面不那么出名,但Buzzfeed做了很多高质量的数据新闻。
这也都是开源的。
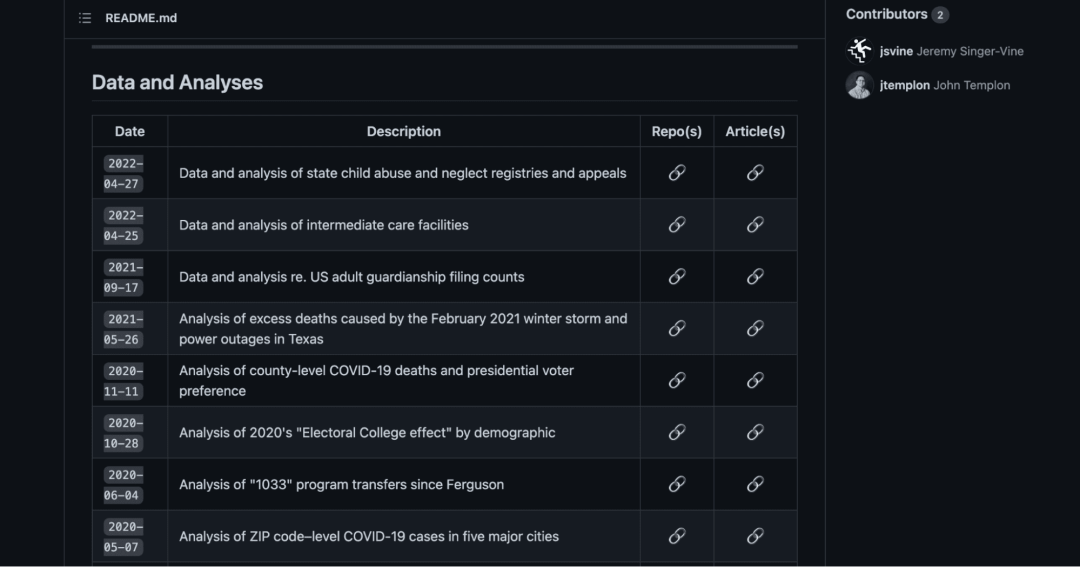
来源:BuzzFeed News GitHub
推荐这个网站的原因:
-
有趣的数据,经过预先清理,并以文章的形式附上精心编写的评论。
-
较重的话题。这里强调的是更复杂的话题,例如政治和健康,但也有很多其他话题。
10. Awesome Public Datasets
链接:https://github.com/awesomedata/awesome-public-datasets
Awesome Public Datasets位于GitHub上,包含了(大部分)免费的数据集,供人们探索。它们来自在线数据集、用户建议和研究论文。
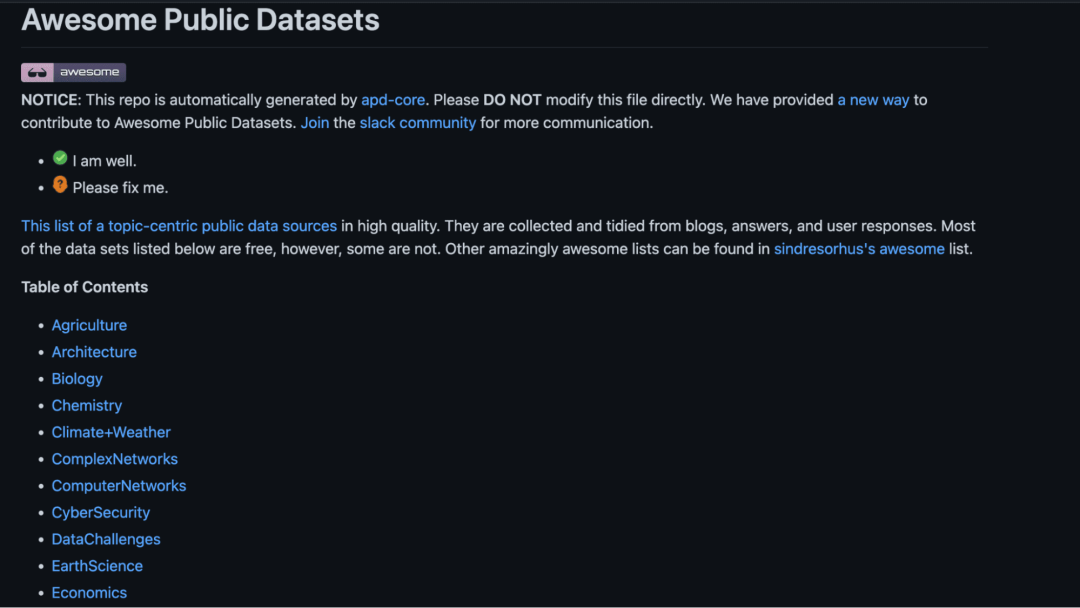
来源:Awesome Public Datasets GitHub
推荐这个网站的原因:
-
主题种类繁多。农业、金融、博物馆。你一定能找到让你心动的东西。
-
精心策划的。数据集的质量很高。
这些网站提供很棒的数据科学数据集
深入挖掘,你不仅可以利用数据,而且还可以利用社区、灵感和代码来学习和成长为一名数据科学家。
有了如此大量的可用数据,你可以始终寻找那些能激发你的灵感或能够让你兴奋地去调查的数据。希望这个清单能给你一些起点来做到这一点。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 什么猫粮比较好?主食冻干猫粮品牌如何选择?
- NPN PNP SS8050 SS8550 S8050
- GO数据库操作
- 天龙八部资源提取工具(提取+添加+修改+查看+教程)
- 网页全屏html视频动画效果
- 软件测试/测试开发丨Python内置库学习笔记
- 深度学习框架Pytorch学习笔记
- Wi-Fi 6 vs. Wi-Fi 6E: The differences between IPQ6018, IPQ6010 and IPQ5018
- 学习Java API(一):基础知识点一文通?
- 2024年天津体育学院专升本专业考试考生入场及考前须知