从零开始有图:pycharm实现某小说网站资源的获取
发布时间:2023年12月20日
运行环境
PyCharm 2023.2.1
python3.11
详细步骤
?1、安装requests,parsel和bs4库
点击终端

输入
pip install requestspip install parselpip install bs4
2、使用pycharm编写python代码,确保在pycharm中可以正常运行代码
不同网站获取方法有一定差距,以笔趣阁网站之一为例,网址为
https://www.biqugen.net搜索需要获取的书籍,进入如下界面,网址栏显示书籍编号(例如诛仙的书籍编号为1416)

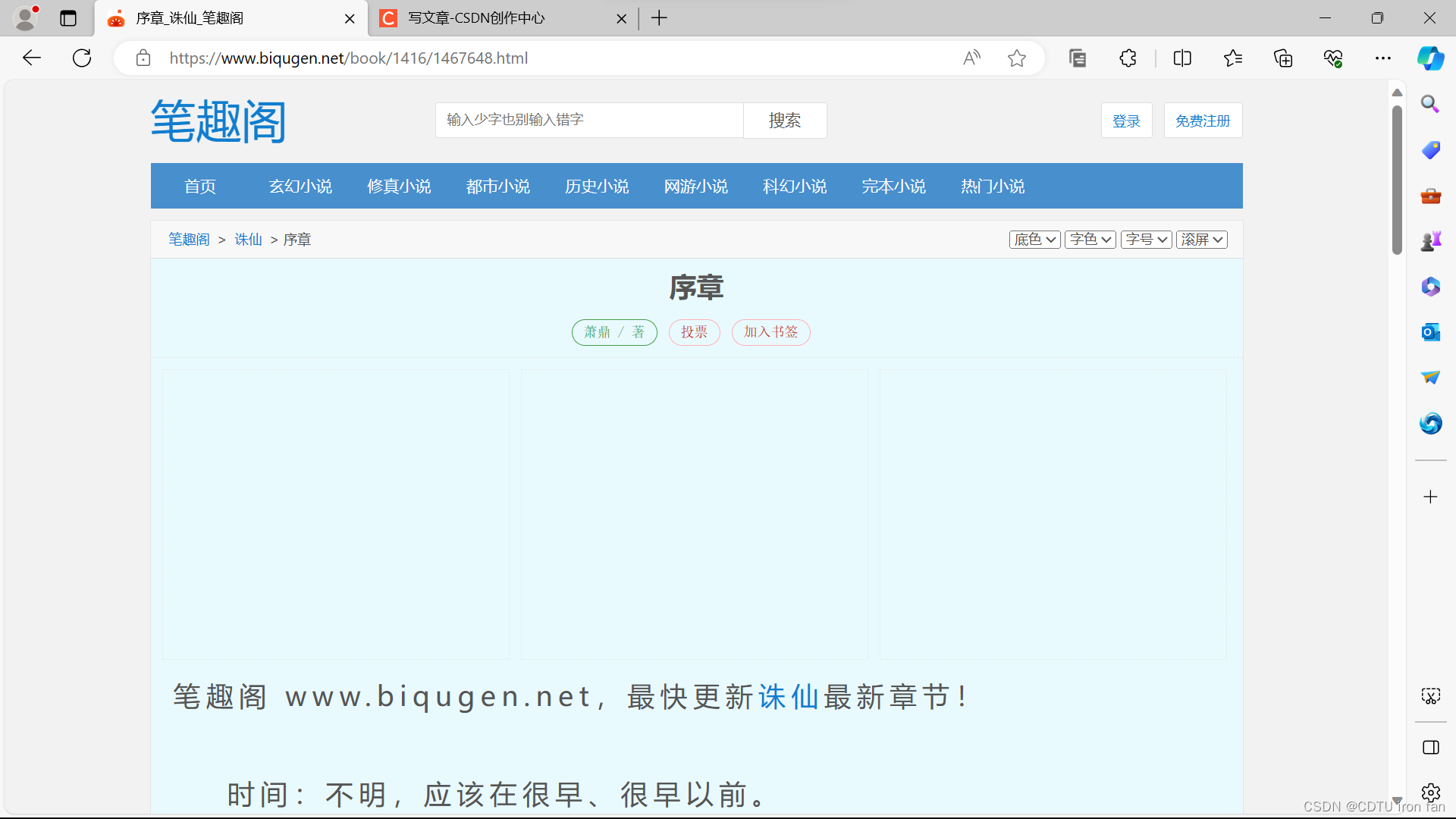
点击进入目录第一章,进入如下界面,网址栏显示书籍起始章节的网页编号(例如序章的网页编号为1467648)
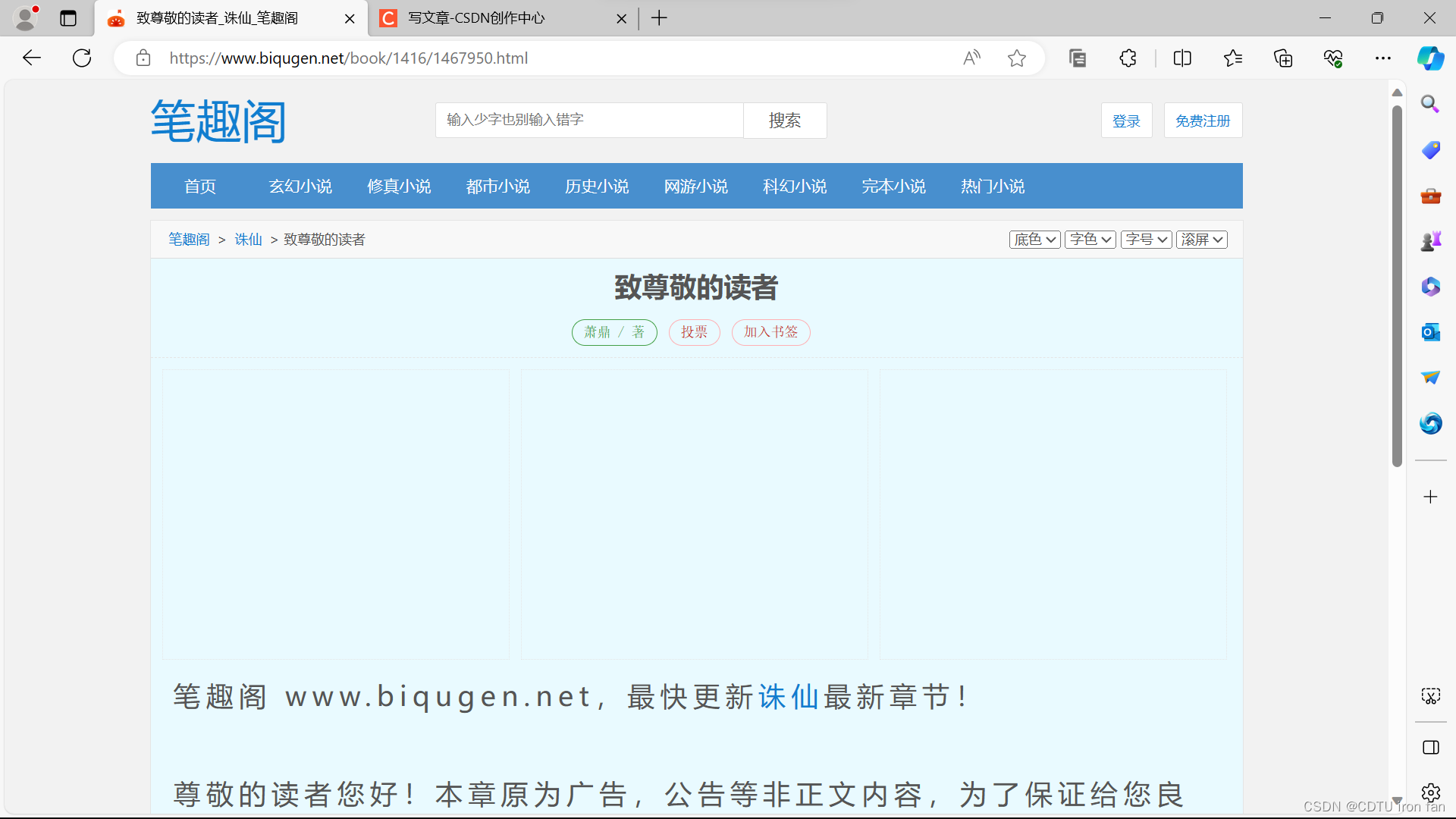
点击进入目录最后一章,进入如下界面,网址栏显示书籍结束章节的网页编号(例如序章的网页编号为1467950)
示例代码,可以通过在pycharm中运行该代码对该网站的内容进行获取
import requests
from bs4 import BeautifulSoup
from parsel import Selector
def get_novel_title(url):
try:
# 发送请求
response = requests.get(url)
# 检查请求是否成功
response.raise_for_status()
# 使用parsel提取小说名称
title_selector = Selector(response.text)
title = title_selector.css('h1::text').get()
return title
except requests.exceptions.RequestException as e:
print(f"Error: {e}")
# 如果请求失败,返回None
return None
def get_chapter_title_and_text(url):
try:
# 发送请求
response = requests.get(url)
# 检查请求是否成功
response.raise_for_status()
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 提取章节标题
title = soup.title.string
# 提取正文内容
content = soup.find('div', {'id': 'content'})
if content:
# 处理文本中的<br>标签
text_with_linebreaks = ''
for element in content.stripped_strings:
text_with_linebreaks += element + '\n'
return title, text_with_linebreaks
return None, None
except requests.exceptions.RequestException as e:
print(f"Error: {e}")
# 如果请求失败,返回None
return None, None
# 获取用户输入,添加循环以允许重新输入
while True:
book_id = input("请输入需要获取的书籍编号:")
book_url = f'https://www.biqugen.net/book/{book_id}/'
book_title = get_novel_title(book_url)
if book_title:
print(f"成功获取书籍信息:{book_title}")
break
else:
print(f"未能获取书籍信息,请重新输入!")
while True:
try:
start_chapter = int(input("请输入起始章节的网页编号:"))
end_chapter = int(input("请输入结束章节的网页编号:"))
output_file_path = input("请输入输出文件的位置:\n(例如C:\\Users\\Abit\\Desktop\\biqugen.txt): ")
print("章节获取情况:")
# 打开文件以写入模式
with open(output_file_path, 'w', encoding='utf-8') as output_file:
# 生成URL并遍历爬取每个网页的内容
for chapter_number in range(start_chapter, end_chapter + 1):
url = f'https://www.biqugen.net/book/{book_id}/{chapter_number}.html'
title, result = get_chapter_title_and_text(url)
# 将成功的章节名称和内容写入文件
if result:
output_file.write(f"{title}:\n{result}\n{'='*50}\n")
print(f"{chapter_number} {title}")
else:
print(f"{chapter_number} 未找到相关内容")
break
except ValueError:
print("输入的章节编号应为整数,请重新输入!")
except Exception as e:
print(f"发生错误: {e}")
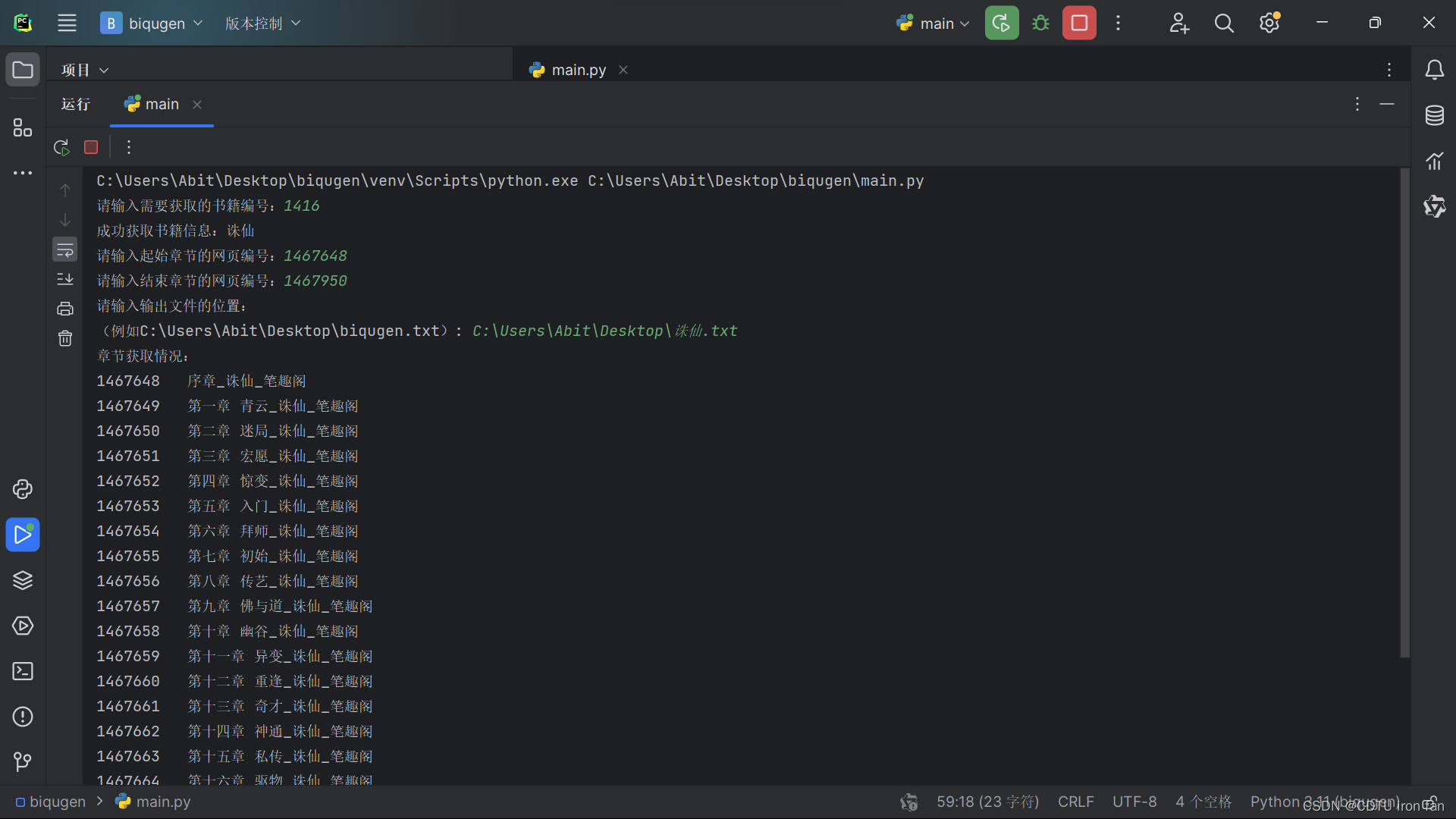
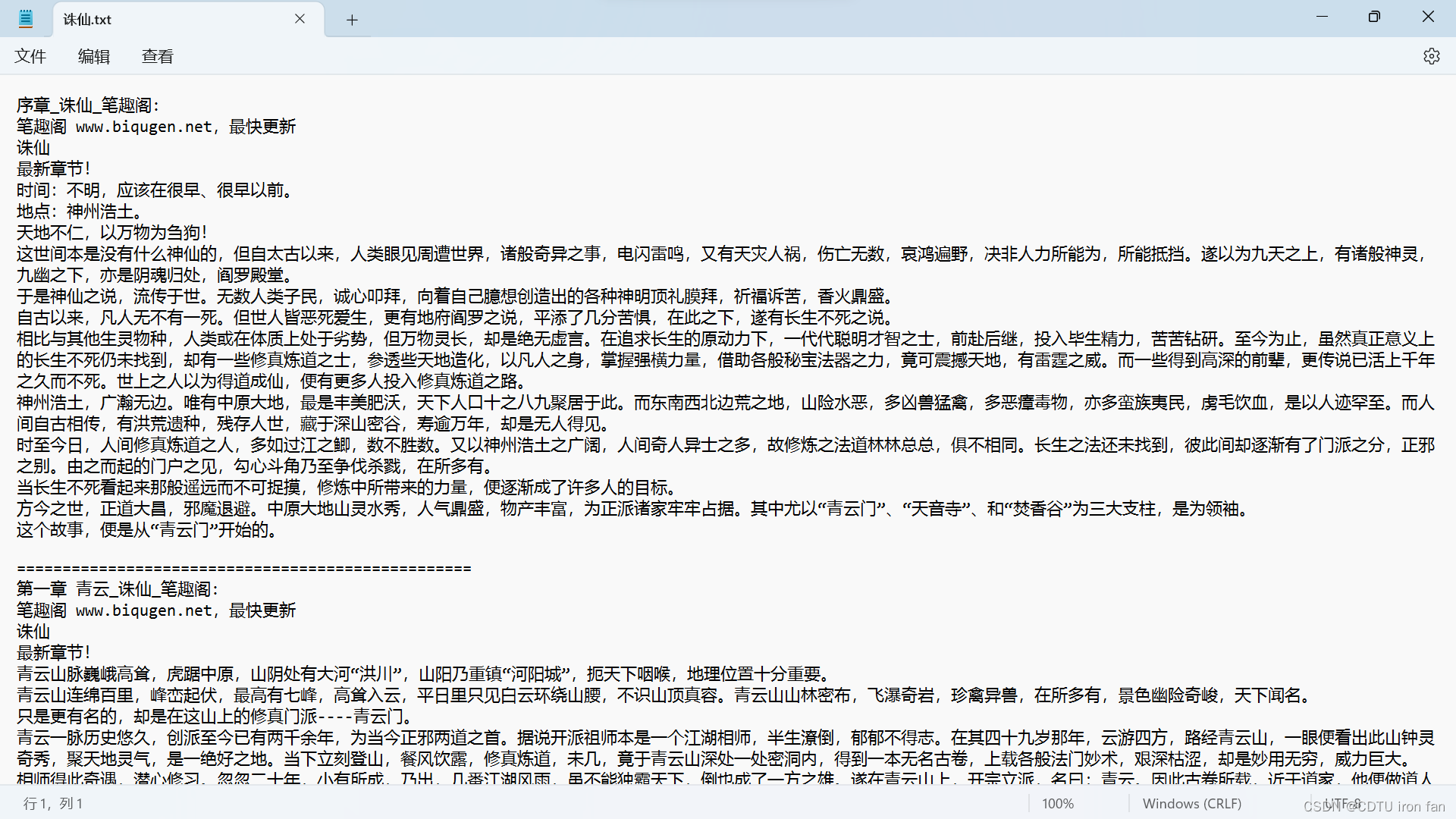
运行结果如图
注意事项
如果出现以下问题
pip : 无法将“pip”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。请检查名称的拼写,如果包括路径,请确保路径正确,然后再试一次。?
注意环境变量的配置,需要将你的python的安装目录下的Script文件夹的路径添加到Path中,比如C:\Program Files\Python311\Scripts
文章来源:https://blog.csdn.net/m0_74865737/article/details/134997670
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- apkpure下载Google Play中APP的APK安装包
- 《面试专题-----经典高频面试题收集二》解锁 Java 面试的关键:深度解析常见Map高频经典面试题(第二篇)
- 【密码学引论】密码协议
- JVM初识-----01章
- ASP.NET Core 依赖注入
- 【Python百宝箱】优化Python开发体验:日志记录、错误监控与高级调试
- 二叉树算法题(一)
- AI-图片转换绚丽动漫人物-UGATIT
- HTML5+CSS3+JS小实例:仿优酷视频轮播图
- 逸学Docker【java工程师基础】1.认识docker并且安装