【数学建模】综合评价方法
文章目录
综合评价的基本理论和数据预处理
一个综合评价问题是由评价对象、评价指标、权重系数、综合评价模型和评价者五个基本要素组成
综合评价的基本概念
评价对象:研究对象,同类多个,记作
S
1
,
S
2
,
.
.
.
,
S
n
(
n
>
1
)
S_1, S_2,..., S_n(n>1)
S1?,S2?,...,Sn?(n>1)
评价指标:也称综合评价的指标体系,包含多个指标,用向量
x
x
x表示,记作
x
=
[
x
1
,
x
2
,
.
.
.
,
x
m
]
x=[x_1, x_2,..., x_m]
x=[x1?,x2?,...,xm?]
权重系数:刻画各个评价指标的相对重要性,用
w
j
(
j
=
1
,
2
,
.
.
.
,
m
)
w_j(j=1,2,...,m)
wj?(j=1,2,...,m)表示评价指标
j
j
j的权重系数,满足
w
j
≥
0
,
?
j
=
1
,
2
,
.
.
.
,
m
;
且
∑
j
=
1
m
w
j
=
1
w_j \geq 0,\ j=1,2,...,m; \quad 且\sum^m_{j=1}w_j=1
wj?≥0,?j=1,2,...,m;且∑j=1m?wj?=1
综合评价模型:实现将多个评价指标值综合得到一个整体的综合评价值,第
i
i
i个评价对象的综合评价值
b
i
b_i
bi?由评价指标
a
i
=
[
a
i
1
,
a
i
2
,
.
.
.
,
a
i
m
]
a_i=[a_{i1}, a_{i2},..., a_{im}]
ai?=[ai1?,ai2?,...,aim?]和权重向量
w
=
[
w
1
,
w
2
,
.
.
.
,
w
m
]
w=[w_1, w_2,..., w_m]
w=[w1?,w2?,...,wm?]根据评价模型
y
=
f
(
x
,
w
)
y=f(x, w)
y=f(x,w)得到
评价者
综合评价体系的构建
综合评价过程包括评价指标体系的建立、评价指标的预处理、指标权重的确定和评价模型的选择等重要环节
评价指标和评价指标体系
从指标特征分为:定性指标和定量指标
从指标变化对评价目的的影响来看:极大型指标、极小型指标、剧中型指标和区间型指标
评价指标的筛选
专家调研法:查阅相关资料得到
最小均方差法:排除不重要的指标,不重要的指标指各个评价对象在该指标上的观测值都差不多,即是根据指标的差异程度进行判断

综合指标的预处理方法
消除不同指标间有关类型、单位、数量级等的差异,避免出现不合理的评价结果
对指标进行一致化处理、无量纲化处理
指标一致化处理
将非极大型指标转化为极大型指标
极小转极大:取倒转化
x
j
˙
=
1
x
j
\dot{x_j} = \frac{1}{x_j}
xj?˙?=xj?1?、平移转化
x
j
˙
=
M
j
?
x
j
\dot{x_j} = M_j-x_j
xj?˙?=Mj??xj?其中
M
j
=
m
a
x
1
≤
i
≤
n
{
a
i
j
}
M_j=max_{1\leq i \leq n}\{a_{ij}\}
Mj?=max1≤i≤n?{aij?}
居中转极大:
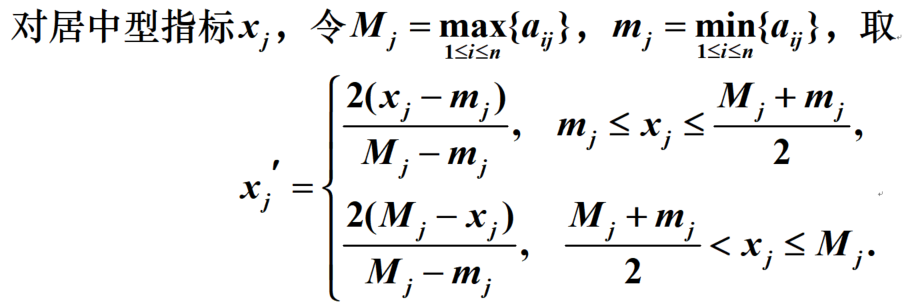
区间转极大:
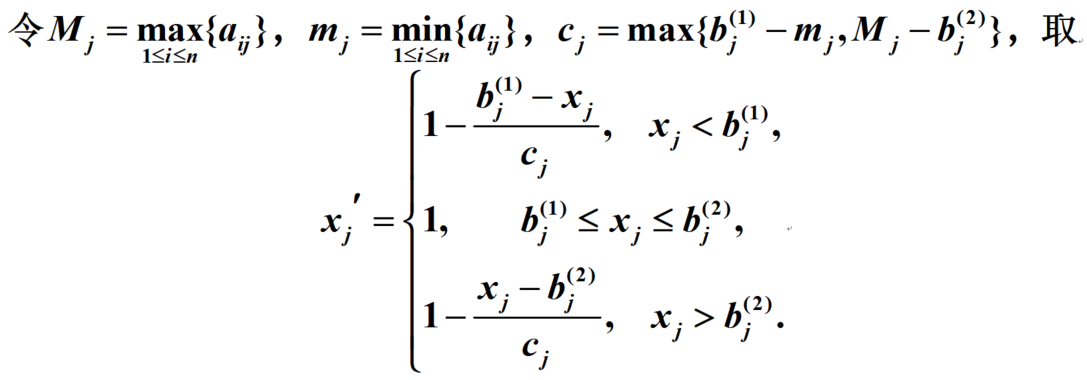
指标无量纲处理
将指标实际值转化为指标评价值
标准样本变换:

说明:这个变换处理会出现负值,将不能直接用于后续的熵权法/几何加权法
比例变换法:变换签后属性值成比例
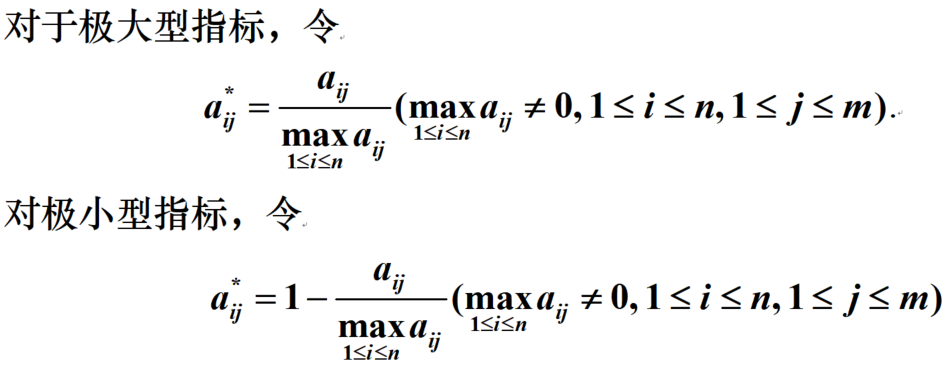
向量归一化法:

极差变换法:变换后
0
≤
a
i
j
?
≤
1
0 \leq a_{ij}^* \leq 1
0≤aij??≤1
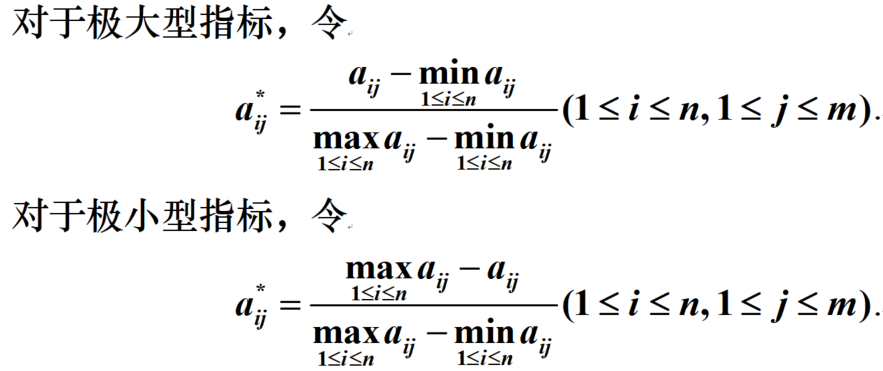
功效系数法:

定性指标定量化

评价指标预处理示例
根据下表所示的最大速度、飞行半径、最大负载、隐身性能、可靠性、灵敏度六个指标综合评价
A
1
,
?
A
2
,
?
A
3
,
?
A
4
A_1,\ A_2,\ A_3,\ A_4
A1?,?A2?,?A3?,?A4?四种战斗机性能
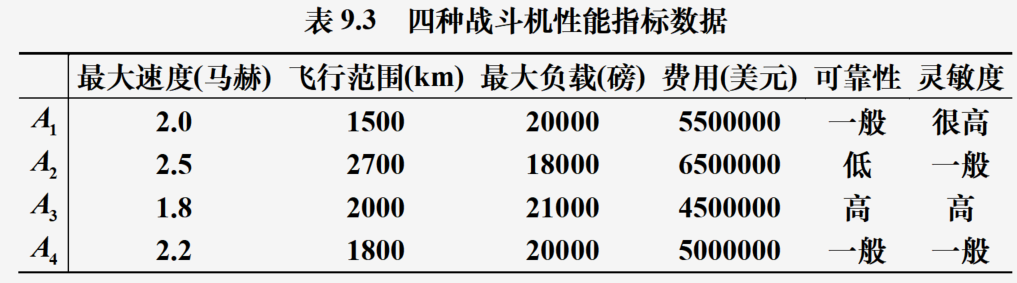
求解:
将6项指标依次记为
x
1
,
x
2
,
.
.
.
,
x
6
x_1,x_2,...,x_6
x1?,x2?,...,x6?,将
x
5
x_5
x5?和
x
6
x_6
x6?两项定性指标定量化
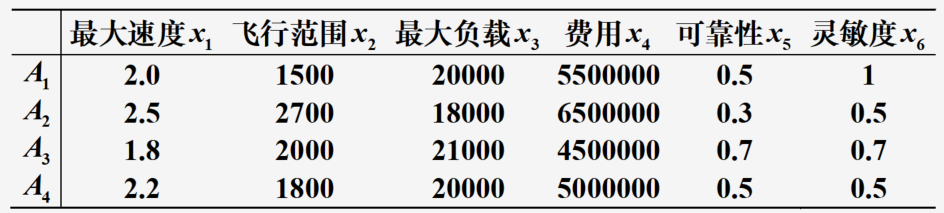
分别使用向量归一化、比例变换法和极差变换法标准化数值性指标数据
import numpy as np
import pandas as pd
a=np.loadtxt("Pdata9_1_1.txt",)
R1=a.copy(); R2=a.copy(); R3=a.copy() #初始化
#注意R1=a,它们的内存地址一样,R1改变时,a也改变
for j in [0,1,2,4,5]:
R1[:,j]=R1[:,j]/np.linalg.norm(R1[:,j]) #向量归一化
R2[:,j]=R1[:,j]/max(R1[:,j]) #比例变换
R3[:,j]=(R3[:,j]-min(R3[:,j]))/(max(R3[:,j])-min(R3[:,j]));
R1[:,3]=1-R1[:,3]/np.linalg.norm(R1[:,3])
R2[:,3]=min(R2[:,3])/R2[:,3]
R3[:,3]=(max(R3[:,3])-R3[:,3])/(max(R3[:,3])-min(R3[:,3]))
np.savetxt("Pdata9_1_2.txt", R1); #把数据写入文本文件,供下面使用
np.savetxt("Pdata9_1_3.txt", R2); np.savetxt("Pdata9_1_4.txt", R3)
DR1=pd.DataFrame(R1) #生成DataFrame类型数据
DR2=pd.DataFrame(R2); DR3=pd.DataFrame(R3)
f=pd.ExcelWriter('Pdata9_1_5.xlsx') #创建文件对象
DR1.to_excel(f,"sheet1") #把DR1写入Excel文件1号表单中,方便做表
DR2.to_excel(f,"sheet2"); DR3.to_excel(f, "Sheet3"); f.save()
常用的综合评价数学模型
综合评价数学模型:将同一评价对象不同方面的多个指标值综合在一起,得到一个整体性评价指标值的一个数学表达式
记号说明
n
n
n个评价对象,
m
m
m个评价指标
x
1
,
x
2
,
.
.
.
,
x
m
x_1,x_2,...,x_m
x1?,x2?,...,xm?
第
i
i
i个评价对象的指标指
a
i
=
[
a
i
1
,
a
i
2
,
.
.
.
,
a
i
m
]
a_i=[a_{i1}, a_{i2},..., a_{im}]
ai?=[ai1?,ai2?,...,aim?]
经过指标数据预处理得到的结果为
b
i
=
[
b
i
1
,
b
i
2
,
.
.
.
,
b
i
m
]
b_i=[b_{i1}, b_{i2},..., b_{im}]
bi?=[bi1?,bi2?,...,bim?]
指标变量的权重系数???怎么得到
线性加权综合评价模型
利用指标变量的权重系数
w
=
[
w
1
,
w
2
,
.
.
.
,
w
m
]
w=[w_1,w_2,...,w_m]
w=[w1?,w2?,...,wm?]
f
i
=
∑
j
=
1
m
w
j
b
i
j
?
(
i
=
1
,
2
,
.
.
.
,
n
)
f_i=\sum^m_{j=1}w_jb_{ij}\ (i=1,2,...,n)
fi?=j=1∑m?wj?bij??(i=1,2,...,n)
说明:适合各个评价指标相互独立的情况,若各个评价指标不完全独立将导致各指标间信息的重复起作用
TOPSIS法

正理想解和负理想解构造
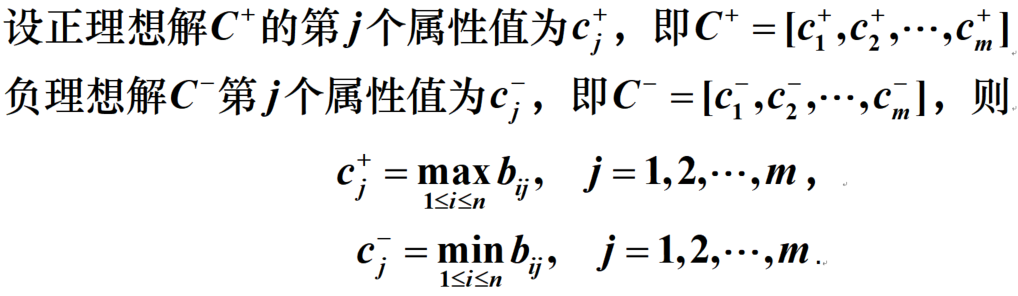


加权TOPSIS方法
根据得到的权重向量
w
w
w,修改评价矩阵
B
=
(
b
i
j
)
n
x
m
B=(b_{ij})_{nxm}
B=(bij?)nxm?,得到加权规范评价矩阵
B
^
\hat{B}
B^,其中每个值
b
i
j
^
=
w
j
b
i
j
\hat{b_{ij}} = w_jb_{ij}
bij?^?=wj?bij?,用
B
^
\hat{B}
B^按照上面的步骤进行处理
灰色关联度分析
设综合评价问题中有
n
n
n个评价对象
m
m
m个指标,相应的指标观测值分别为
a
i
j
(
i
=
1
,
2
,
.
.
.
,
n
;
j
=
1
,
2
,
.
.
.
,
m
)
a_{ij}(i=1,2,...,n;\quad j=1,2,...,m)
aij?(i=1,2,...,n;j=1,2,...,m)
具体步骤:
(1)数据预处理:对评价数据进行一致化和无量纲化处理,得到评价矩阵
B
=
(
B
i
j
)
n
m
B=(B_{ij})_{nm}
B=(Bij?)nm?
(2)确定比较序列和参考序列:比较序列即为矩阵
B
B
B的每一行,参考序列相当于TOPSIS方法中的最优解,记作
b
0
b_0
b0?
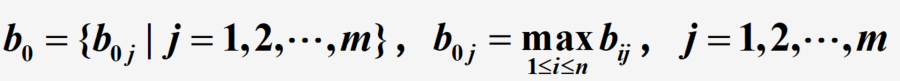
(3)计算灰色关联系数:
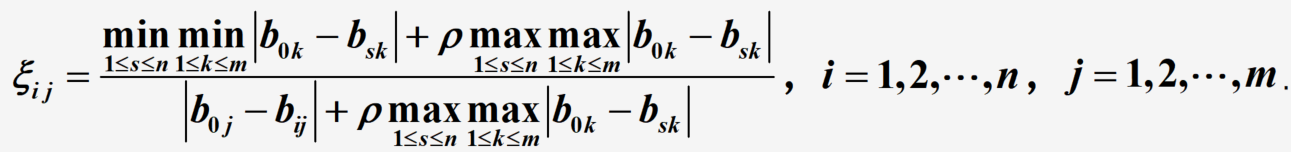
说明:上式计算的是比较序列
b
i
b_i
bi?对参考序列
b
0
b_0
b0?在第
j
j
j个指标上的关联系数;
σ
∈
[
0
,
1
]
\sigma \in [0,1]
σ∈[0,1]为分辨系数,分辨系数与分辨率正相关;称
m
i
n
1
≤
s
≤
n
m
i
n
1
≤
k
≤
m
∣
b
0
k
?
b
s
k
∣
min_{1 \leq s \leq n}min_{1 \leq k \leq m}|b_{0k}-b_{sk}|
min1≤s≤n?min1≤k≤m?∣b0k??bsk?∣为两级最小差,
m
a
x
1
≤
s
≤
n
m
a
x
1
≤
k
≤
m
∣
b
0
k
?
b
s
k
∣
max_{1 \leq s \leq n}max_{1 \leq k \leq m}|b_{0k}-b_{sk}|
max1≤s≤n?max1≤k≤m?∣b0k??bsk?∣为两级最大差
(4)计算灰色关联度:
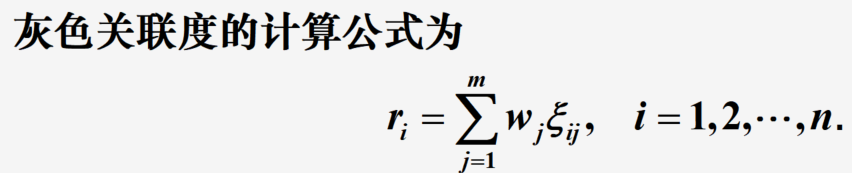
说明:式子中
w
j
w_j
wj?为第
j
j
j个指标的权重,计算结果
r
i
r_i
ri?为第
i
i
i个评价对象对理想对象的灰色关联度
(5)评价分析:
根据灰色关联度值对各评价对象进行排序,关联度越大评价结果越好
熵值法
使用目的:根据各指标的相对变化程度对系统整体的影响来确定指标权重系数
- 计算第
i
i
i个评价对象在第
j
j
j项指标的特征比重
p
i
j
p_{ij}
pij?

- 计算第
j
j
j项指标的熵值

- 计算第
j
j
j项指标的差异系数
g
i
g_i
gi?

- 确定第
j
j
j项指标的权重系数
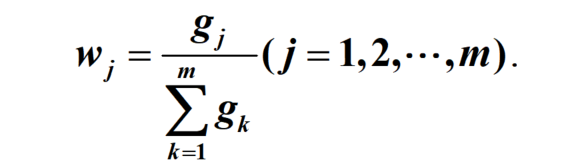
- 计算第
i
i
i个评价对象的综合评价值
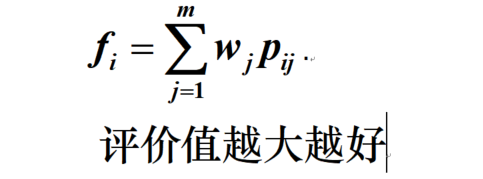
说明:在计算综合评价值时,可以只是使用熵值法来计算各个指标的权重系数,利用求得的权重系数结合其他综合评价方法得到各个评价对象的综合评价直,比如熵权法+TOPSIS方法为常用的综合评价策略
秩和比(RSR)法
Rank Sum Ratio, RSR
基本原理
在
n
n
n行
m
m
m列矩阵中通过秩转化,获得无量纲统计量RSR,使用RSR值对评价对象直接排序
样本秩

举个例子说明样本数据的秩统计量

设综合评价问题中有
n
n
n个评价对象
m
m
m个指标,相应的指标观测值分别为
a
i
j
(
i
=
1
,
2
,
.
.
.
,
n
;
j
=
1
,
2
,
.
.
.
,
m
)
a_{ij}(i=1,2,...,n;\quad j=1,2,...,m)
aij?(i=1,2,...,n;j=1,2,...,m)
构造得到数据矩阵
A
=
(
a
i
j
)
n
m
A=(a_{ij})_{nm}
A=(aij?)nm?
步骤
(1)编秩:对数据矩阵
A
A
A逐列编秩,即分别编出每个指标值的秩。具体为:将极大型指标从小到大编秩,极小型指标从大到小编秩,指标值相同时编平均秩,得到秩矩阵
R
=
(
R
i
j
)
n
m
R=(R_{ij})_{nm}
R=(Rij?)nm?
(2)计算秩和比(RSR):
R
S
R
i
=
1
n
∑
j
=
1
m
w
j
R
i
j
RSR_i=\frac{1}{n}\sum_{j=1}^mw_jR_{ij}
RSRi?=n1?∑j=1m?wj?Rij?,
w
j
w_{j}
wj?为第
j
j
j个指标的权重
(3)秩和比排序:RSR值越大,评价结果越好
综合评价示例
例题:
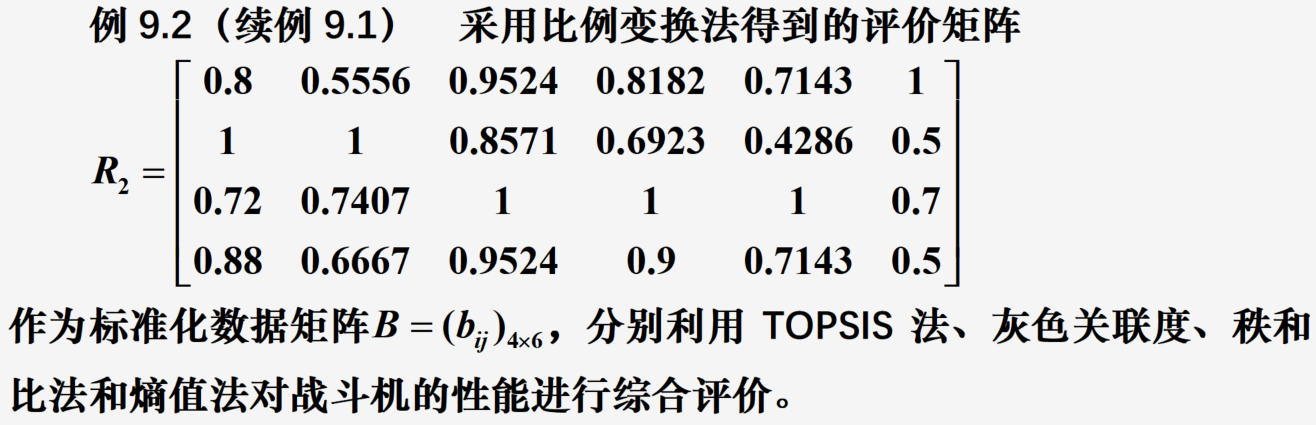
代码:
import numpy as np
from scipy.stats import rankdata
a=np.loadtxt("Pdata9_1_3.txt")
cplus=a.max(axis=0) #逐列求最大值
cminus=a.min(axis=0) #逐列求最小值
print("正理想解=",cplus,"负理想解=",cminus)
d1=np.linalg.norm(a-cplus, axis=1) #求到正理想解的距离
d2=np.linalg.norm(a-cminus, axis=1) #求到负理想解的距离
print(d1, d2) #显示到正理想解和负理想解的距离
f1=d2/(d1+d2); print("TOPSIS的评价值为:", f1)
t=cplus-a #计算参考序列与每个序列的差
mmin=t.min(); mmax=t.max() #计算最小差和最大差
rho=0.5 #分辨系数
xs=(mmin+rho*mmax)/(t+rho*mmax) #计算灰色关联系数
f2=xs.mean(axis=1) #求每一行的均值
print("\n关联系数=", xs,'\n关联度=',f2) #显示灰色关联系数和灰色关联度
[n, m]=a.shape
cs=a.sum(axis=0) #逐列求和
P=1/cs*a #求特征比重矩阵
e=-(P*np.log(P)).sum(axis=0)/np.log(n) #计算熵值
g=1-e #计算差异系数
w = g / sum(g) #计算权重
F = P @ w #计算各对象的评价值
print("\nP={}\n,e={}\n,g={}\n,w={}\nF={}".format(P,e,g,w,F))
R=[rankdata(a[:,i]) for i in np.arange(6)] #求每一列的秩
R=np.array(R).T #构造秩矩阵
print("\n秩矩阵为:\n",R)
RSR=R.mean(axis=1)/n; print("RSR=", RSR)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Android studio ViewPager2 底部圆点指示器应用设计
- 计算机系统的各个层次结构
- Spring Boot异常处理及单元测试
- MySQL常见面试题总结
- redis pipeline实现,合并多个请求,可有效降低redis访问延迟
- 医院网络安全建设:三网整体设计和云数据中心架构设计
- 跨境业务场景下数据安全问题研究
- 为什么企业要选择WhatsApp Business?
- 【Leetcode】466. 统计重复个数
- 如何修复卡在恢复模式的Android 手机并恢复丢失的数据