【数学建模】数据处理与可视化
文章目录
数值计算工具NumPy
两类基本对象
ndarray(N-dimensional Array Object):存储单一数据类型的多维数组
ufunc(Universal Funciton Object):对数组进行处理的通用函数
数组的创建、属性和操作
数组创建
- 向array函数传入列表/元组
- 利用arange、linspace、empty等函数生成数组
数组属性

数组元素索引
array数组和list列表的区别:list中的元素可以不同,array仅存储相同类型数据
一维数组:数组名[start: end: step]
二维数组:数组名[i,j]
一般索引
import numpy as np
a = np.array([2,4,8,20,16,30])
b = np.array(((1,2,3,4,5),(6,7,8,9,10),
(10,9,1,2,3),(4,5,6,8,9.0)))
print(a[[2,3,5]]) #一维数组索引,输出:[ 8 20 30]
print(a[[-1,-2,-3]]) #一维数组索引,输出:[30 16 20]
print(b[1,2]) #输出第2行第3列元素:8.0
print(b[2]) #输出第3行元素:[10. 9. 1. 2. 3.]
print(b[2,:]) #输出第3行元素:[10. 9. 1. 2. 3.]
print(b[:,1]) #输出第2列所有元素:[2. 7. 9. 5.]
print(b[[2,3],1:4]) #输出第3、4行,第2、3、4列的元素
print(b[1:3,1:3]) #输出第2、3行,第2、3列的元素
说明:
一维数组索引可将索引位置组装为列表
二维数组索引形式为[rows, cols],即方括号前半部分确定行索引,后半部分确定列索引,用:表示索引该行/该列所有元素
布尔索引
from numpy import array, nan, isnan
a=array([[1, nan, 2], [4, nan, 3]])
b=a[~isnan(a)] #提取a中非nan的数
print("b=",b)
print("b中大于2的元素有:", b[b>2])
说明:返回值为一维数组
花式索引
索引值为数组
若使用一维数组,索引一维数组,结果为对应位置的元素;索引数组为二维数组,结果为对应下标的行
若使用二维数组,索引为两个维度相同的一维数组时,索引结果为两个维度坐标组合索引得到单值组合的一维数组
数组修改
import numpy as np
x = np.array([[1,2],[3,4],[5,6]])
x[2,0] = -1 #修改第3行、第1列元素为-1
y=np.delete(x,2,axis=0) #删除数组的第3行
z=np.delete(y,0, axis=1) #删除数组的第1列
t1=np.append(x,[[7,8]],axis=0) #增加一行
t2=np.append(x,[[9],[10],[11]],axis=1) #增加一列
说明:索引修改
数组变形
import numpy as np
a=np.arange(4).reshape(2,2) #生成数组[[0,1],[2,3]]
b=np.arange(4).reshape(2,2) #生成数组[[0,1],[2,3]]
print(a.reshape(4,),'\n',a) #输出:[0 1 2 3]和[[0,1],[2,3]]
print(b.resize(4,),'\n',b) #输出:None和[0 1 2 3]
说明:reshape函数,参数为一个正整数元组指定数组在各个维度上的大小

数组降维
使用ravel()、flatten()、reshape()等方法
import numpy as np
a=np.arange(4).reshape(2,2) #生成数组[[0,1],[2,3]]
b=np.arange(4).reshape(2,2) #生成数组[[0,1],[2,3]]
c=np.arange(4).reshape(2,2) #生成数组[[0,1],[2,3]]
print(a.reshape(-1),'\n',a) #输出:[0 1 2 3]和[[0,1],[2,3]]
print(b.ravel(),'\n',b) #输出:[0 1 2 3]和[[0,1],[2,3]]
print(c.flatten(),'\n',c) #输出:[0 1 2 3]和[[0,1],[2,3]]
说明:三种方法的效果相同,一般使用flatten()方法,该方法分配了新的内存
数组组合
vstack()和r_()实现垂直方向组合,hstack()和c_()实现水平方向组合
import numpy as np
a=np.arange(4).reshape(2,2) #生成数组[[0,1],[2,3]]
b=np.arange(4,8).reshape(2,2) #生成数组[[4,5],[6,7]]
c1=np.vstack([a,b]) #垂直方向组合
c2=np.r_[a,b] #垂直方向组合
d1=np.hstack([a,b]) #水平方向组合
d2=np.c_[a,b] #水平方向组合
数组分割
hsplit()实现垂直方向分割,vsplit()实现水平方向分割
import numpy as np
a=np.arange(4).reshape(2,2) #生成数组[[0,1],[2,3]]
b=np.arange(4,8).reshape(2,2) #生成数组[[4,5],[6,7]]
c1=np.vstack([a,b]) #垂直方向组合
c2=np.r_[a,b] #垂直方向组合
d1=np.hstack([a,b]) #水平方向组合
d2=np.c_[a,b] #水平方向组合
数组的运算、通用函数和广播运算
四则运算
运算符号+、-、* 、/、%、//、**
运算函数add()、substract()、multiply()、divide()、fmod()、modf()、power()
import numpy as np
a=np.arange(10,15); b=np.arange(5,10)
c=a+b; d=a*b #对应元素相加和相乘
e1=np.modf(a/b)[0] #对应元素相除的小数部分
e2=np.modf(a/b)[1] #对应元素相除的整数部分
比较运算
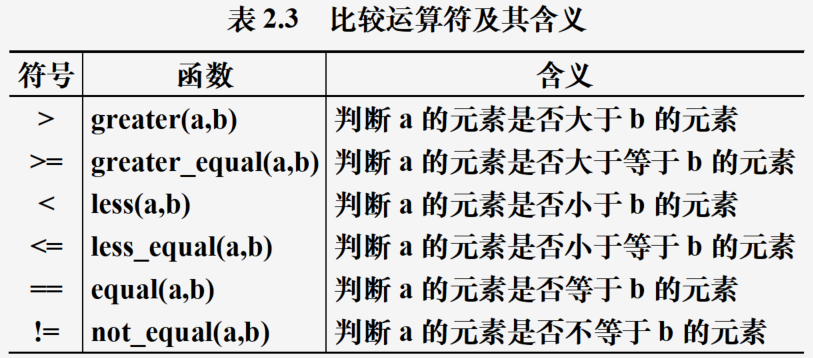
import numpy as np
a=np.array([[3,4,9],[12,15,1]])
b=np.array([[2,6,3],[7,8,12]])
print(a[a>b]) #取出a大于b的所有元素,输出:[ 3 9 12 15]
print(a[a>10]) #取出a大于10的所有元素,输出:[12 15]
print(np.where(a>10,-1,a)) #a中大于10的元素改为-1
print(np.where(a>10,-1,0)) #a中大于10的元素改为-1,否则为0
说明:多维数组使用bool索引得到结果为一维数组,使用np.where得到结果保持原来形状
ufunc函数
对数组进行逐元素操作的函数
# 比较math函数和ufunc函数的效率
import numpy as np, time, math
x=[i*0.01 for i in range(1000000)]
start=time.time() # 1970纪元后经过的浮点秒数
for (i,t) in enumerate(x): x[i]=math.sin(t)
print("math.sin:", time.time()-start)
y=np.array([i*0.01 for i in range(1000000)])
start=time.time()
y=np.sin(y)
print("numpy.sin:", time.time()-start)
广播机制
逐元素运算时对两个数组的维度要求
各输入数组从右到左的对应维度值相同,或其中之一为1
import numpy as np
a=np.arange(0, 20, 10).reshape(-1, 1) #变形为1列的数组,行数自动计算
b=np.arange(0, 3)
print(a+b)
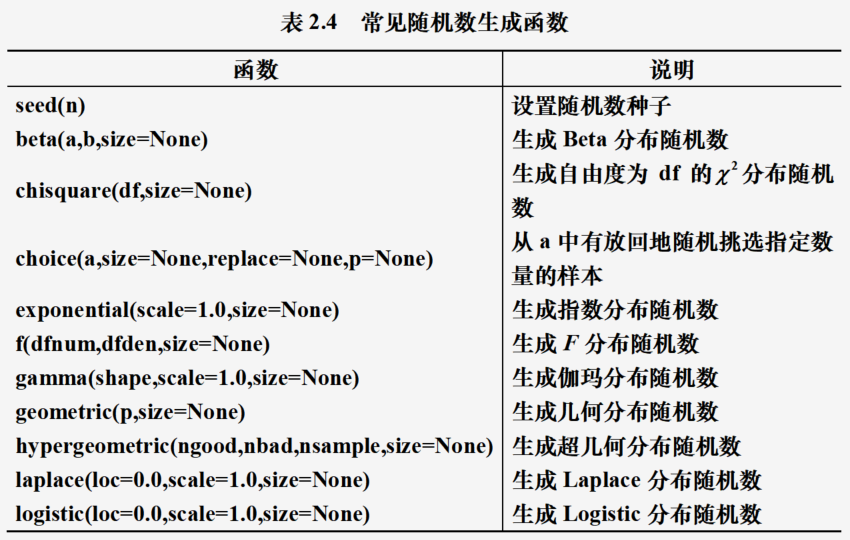
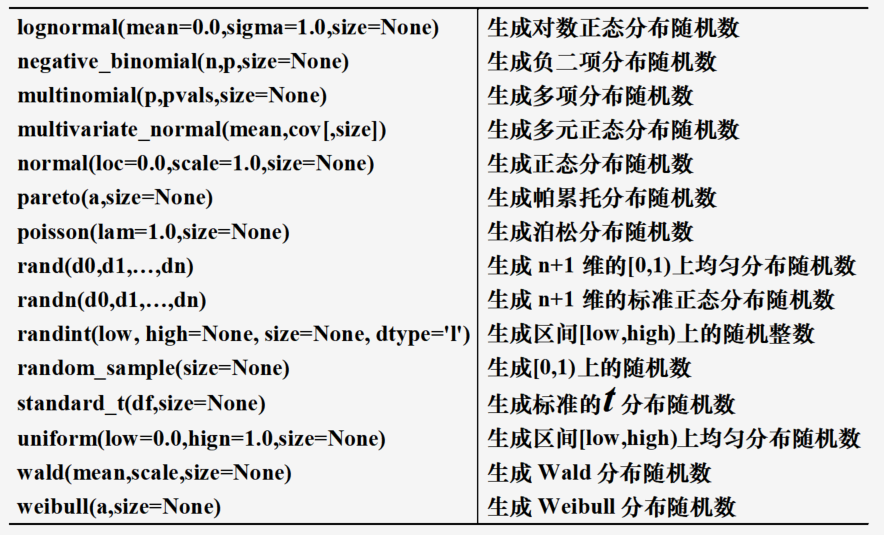
Numpy.random模块的随机数生成
相比Python内置的random模块,Numpy.random模块的随机数生成函数可以生成随机向量且可使用的函数丰富
文本文件和二进制文件存取
文件存取格式分类:二进制格式和文本格式
二进制格式文件分类:Numpy专用格式化二进制文件和无格式类型
文本文件存取
savetxt()和loadtxt()方法
import numpy as np
a=np.arange(0,3,0.5).reshape(2,3) #生成2×3的数组
np.savetxt("Pdata2_18_1.txt", a) #缺省按照'%.18e'格式保存数值,以空格分隔
b=np.loadtxt("Pdata2_18_1.txt") #返回浮点型数组
print("b=",b)
np.savetxt("Pdata2_18_2.txt", a, fmt="%d", delimiter=",") #保存为整型数据,以逗号分隔
c=np.loadtxt("Pdata2_18_2.txt",delimiter=",") #读入的时候也需要指定逗号分隔
print("c=",c)
二进制格式文件存取
tofile()和fromfile()方法
import numpy as np
a=np.arange(6).reshape(2,3)
a.tofile('Pdata2_22.bin')
b=np.fromfile('Pdata2_22.bin',dtype=int).reshape(2,3)
print(b)
NumPy专用二进制文件存取
load()和save()方法
savez()方法将多个数组保存到一个文件中
import numpy as np
a=np.arange(6).reshape(2,3)
np.save("Pdata2_23_1.npy",a)
b=np.load("Pdata2_23_1.npy")
c=np.arange(6,12).reshape(2,3)
d=np.sin(c)
np.savez("Pdata2_23_2.npz",c,d)
e=np.load("Pdata2_23_2.npz")
f1=e["arr_0"] #提取第一个数组的数据
f2=e["arr_1"] #提取第二个数组的数据
文件操作
文件分类
文本文件:每个字节存放一个ASCII码,代表一个字符
二进制文件:将数据在内存中的存储形式直接输出到磁盘上存放
文件基本操作
打开文件
使用open()函数,返回值为对应文件的文件对象
文件对象名=open(文件名[, 打开方式[, 缓冲区] )
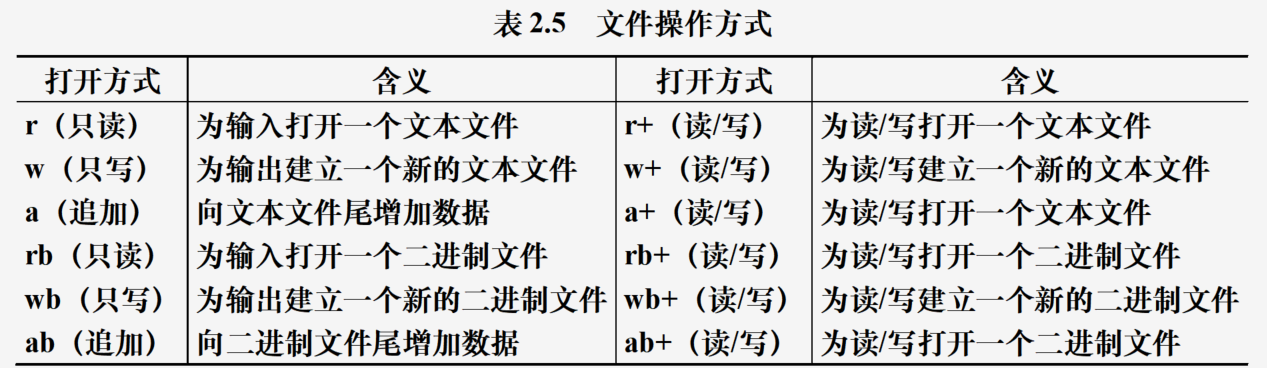
说明:使用with语句打开文件,则可以省略关闭文件的步骤,文件使用完后会自动关闭
文件对象属性
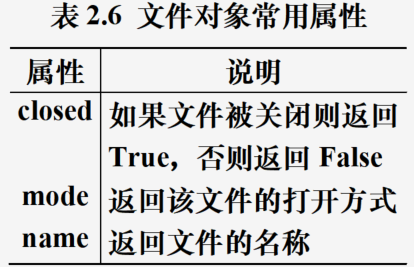
文件对象方法

关闭文件
文件对象名.close()
文件管理方法
文件和目录列表
os.listdir("目录名")
文件重命名
os.rename("当前文件名","新文件名")
目录操作
新建目录:os.mkdir("新目录名")
改变目录:os.chdir("新目录名")
显示当前目录名:os.getcwd()
删除空目录:os.rmdir("待删除目录名")(rmdir()方法只能删除一个空目录,即是删除目录中的所有内容后,才能删除当前目录)
数据处理工具Pandas
Python最强大的数据分析和探索工具之一
支持类似于SQL语句的模型,支持时间序列分析
解决数据的预处理问题,如数据类型的转换、缺失值的处理、描述性统计分析、数据的汇总等
Pandas中最重要的是Series和DataFrame子类
统计特征计算
算数平均值:mean()
标准差:std()
协方差矩阵:cov()
方差:var()
数据的基本情况:describe()
Series和DataFrame
Series:带标签的一维数组
DataFrame:带标签的二维数组
Panel:多维数据,通常包括不同时间的不同测量结果
Series构造
构建方法:使用同类型的列表或元组、通过字典、通过NumPy一维数组、通过DataFrame中某一列
import pandas as pd
import numpy as np
s1=pd.Series(np.array([10.5,20.5,30.5])) #由数组构造序列
s2=pd.Series({"北京":10.5,"上海":20.5,"广东":30.5}) #由字典构造序列
s3= pd.Series([10.5,20.5,30.5],index=['b','c','d']) #给出行标签命名
print(s1); print("--------------");
print(s2)
print("--------------");
print(s3)
Series的索引和计算
import pandas as pd
import numpy as np
s=pd.Series([10.5,20.5,98],index=['a','b','c'])
a=s['b'] #取出序列的第2个元素,输出:20.5
b1=np.mean(s) #输出:43.0
b2=s.mean() #通过数列方法求均值,输出:43.0import pandas as pd
import numpy as np
s=pd.Series([10.5,20.5,98],index=['a','b','c'])
a=s['b'] #取出序列的第2个元素,输出:20.5
b1=np.mean(s) #输出:43.0
b2=s.mean() #通过数列方法求均值,输出:43.0
DataFrame的创建方法
DataFrame(data=二维数据 [, index=行索引[, columns=列索引[, dtype=数据类型]]])
import pandas as pd
import numpy as np
a=np.arange(1,7).reshape(3,2)
df1=pd.DataFrame(a)
df2=pd.DataFrame(a,index=['a','b','c'], columns=['x1','x2'])
df3=pd.DataFrame({'x1':a[:,0],'x2':a[:,1]})
print(df1);
print("---------");
print(df2)
print("---------");
print(df3)
外部文件存取
从文本文件、Excel表格中读取
文本文件的读取
read_csv()函数,读取txt或csv文件
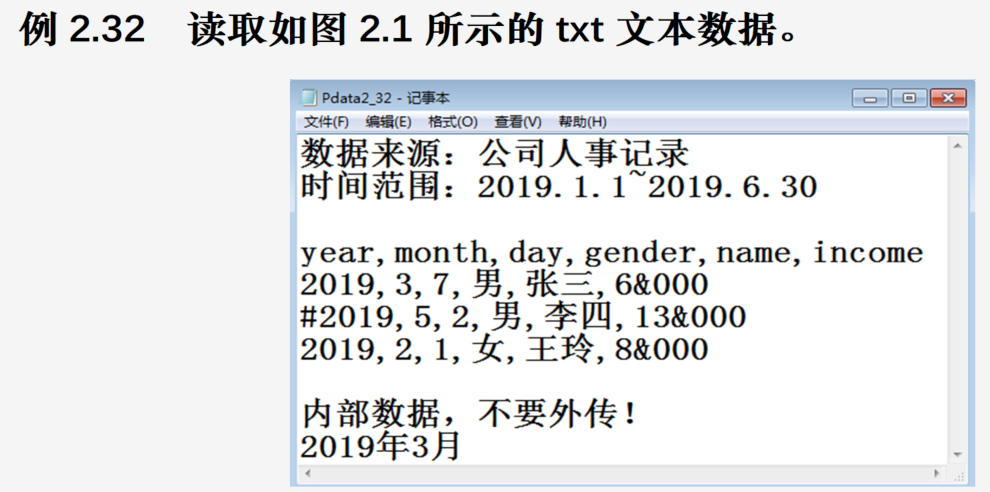
import pandas as pd
a=pd.read_csv("Pdata2_32.txt",sep=',',parse_dates={'birthday':[0,1,2]},
#parse_dates参数通过字典实现前三列的日期解析,并合并为新字段birthday
skiprows=2,skipfooter=2,comment='#',thousands='&',engine='python')
print(a)
读取Excel文件
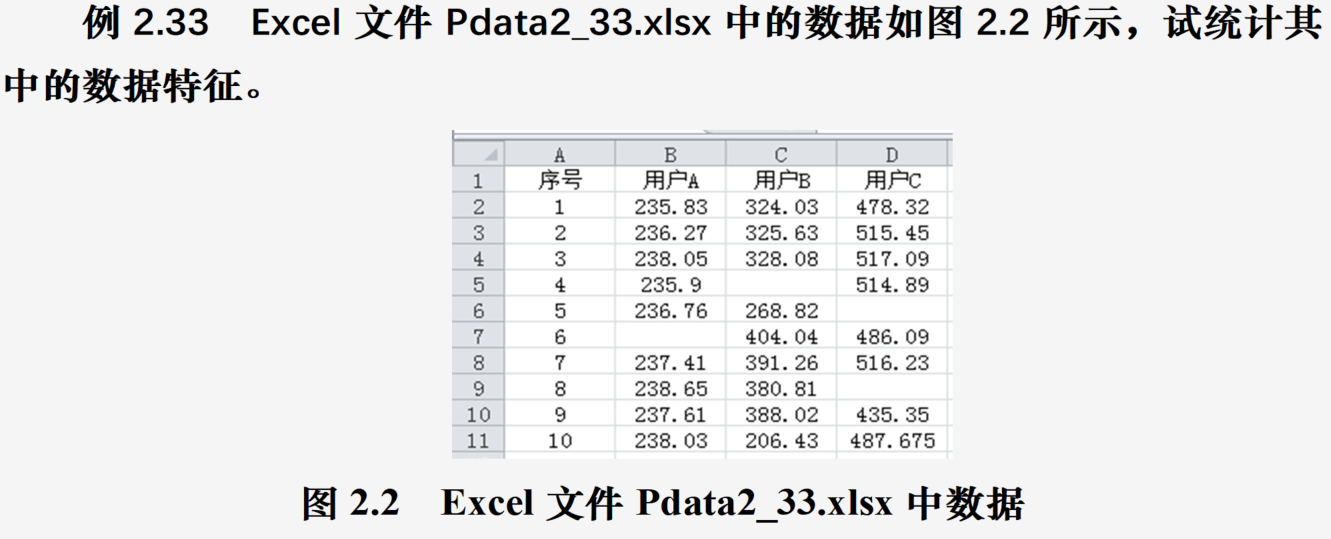
import pandas as pd
a=pd.read_excel("Pdata2_33.xlsx",usecols=range(1,4)) #提取第2列到第4列的数据
b=a.values #提取其中的数据
c=a.describe() #对数据进行统计描述
print(c)
向Excel文件写入数据
# 读入Excel文件Pdata2_33.xlsx中的数据
# 然后写入另一个文件Pdata2_34.xlsx中的两个表单“sheet1”和“sheet2”中
import pandas as pd
import numpy as np
a=pd.read_excel("Pdata2_33.xlsx",usecols=range(1,4)) #提取第2列到第4列的数据
b=a.values #提取其中的数据
#生成DataFrame类型数据
c=pd.DataFrame(b,index=np.arange(1,11),columns=["用户A","用户B","用户C"])
f=pd.ExcelWriter('Pdata2_34.xlsx') #创建文件对象
c.to_excel(f,"sheet1") #把c写入Excel文件
c.to_excel(f,"sheet2") #c再写入另一个表单中
f.save()
获取数据子集
iloc()方法和loc()方法,筛选[rows_select, cols_select]
iloc()方法使用行号和列号筛选数据
loc()方法使用行标签/列标签筛选数据
# 读取用户A和用户B的前6个数据
import pandas as pd
import numpy as np
a=pd.read_excel("Pdata2_33.xlsx",usecols=range(1,4)) #提取第2列到第4列的数据
b1=a.iloc[np.arange(6),[0,1]] #通过标号筛选数据
b2=a.loc[np.arange(6),["用户A","用户B"]] #通过标签筛选数据
Matplotlib可视化
Python强大的数据可视化工具,类似MATLAB语言
基础用法
四种对象容器
Figure:图形大小、位置等操作
Axes:坐标轴位置、绘图等操作
Axis:坐标轴的设置等操作
Tick:格式化刻度的样式等操作
折线图
plot(x, y, s):x为数据
x
x
x坐标,y为数据
y
y
y坐标,s为指定线条颜色、样式和数据点形状的字符串
plot(x, y, linestyle, linewidth, color, marker, markersize, markeredgecolor, markerfacecolor, markeredgewidth, label, alpha)

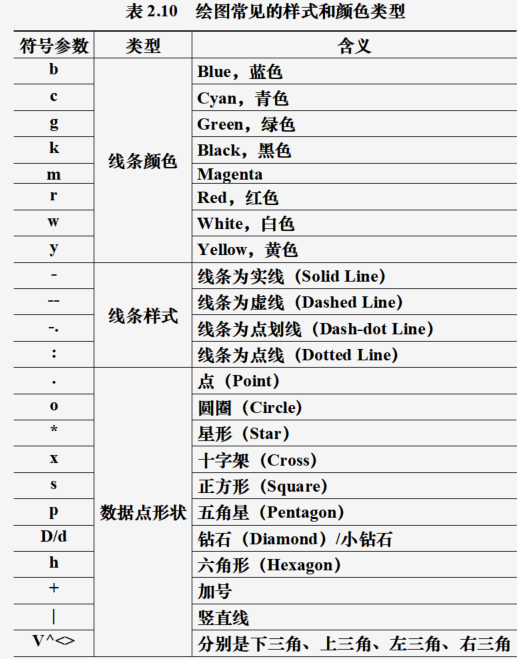
常用绘图函数
pie():饼状图
bar():柱状图
hist():二维直方图
scatter():散点图
模块加载
方式一:import matplotlib.pyplot as plt或from matplotlib import pyplot as plt,画图函数调用为plt.plot()
方式二:from matplotlib.pyplot import *,画图函数调用为plot()
画图步骤
(1)导入Matplotlib.pyplot模块。
(2)设置绘图的数据及参数。
(3)调用Matplotlib.pyplot模块的plot()、pie()、bar()、hist()、scatter()等函数进行绘图。
(4)设置绘图的x轴、y轴、标题、网格线、图例等内容
(5)调用show()函数显示已绘制的图形。
中文和负号的显示设置
rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
rcParams['axes.unicode_minus']=False #用来正常显示负号
可视化应用
散点图

import numpy as np
from matplotlib.pyplot import *
x=np.array(range(8))
y='27.0 26.8 26.5 26.3 26.1 25.7 25.3 24.8' #数据是粘贴过来的
y=",".join(y.split()) #把空格替换成逗号
y=np.array(eval(y)) #数据之间加逗号太麻烦,我们用程序转换
scatter(x,y)
savefig('figure2_23.png',dpi=500); show()
多个图形显示在一个图形画面

import numpy as np
from matplotlib.pyplot import *
x=np.linspace(0,2*np.pi,200)
y1=np.sin(x); y2=np.cos(pow(x,2))
rc('font',size=16); rc('text', usetex=True) #调用tex字库
plot(x,y1,'r',label='$sin(x)$',linewidth=2) #Latex格式显示公式
plot(x,y2,'b--',label='$cos(x^2)$')
xlabel('$x$');
ylabel('$y$',rotation=0)
savefig('figure2_38.png',dpi=500);
legend();
show()
多个图形单独显示
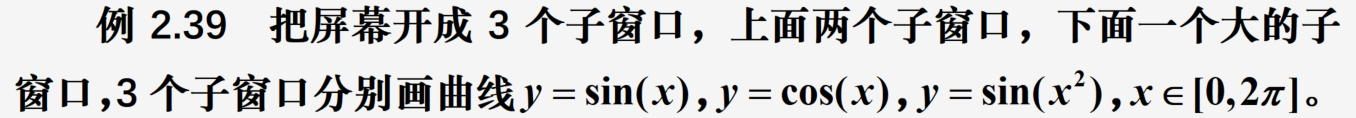
import numpy as np
from matplotlib.pyplot import *
x=np.linspace(0,2*np.pi,200)
y1=np.sin(x);
y2=np.cos(x);
y3=np.sin(x*x)
rc('font',size=16);
rc('text', usetex=True) #调用tex字库
ax1=subplot(2,2,1) #新建左上1号子窗口
ax1.plot(x,y1,'r',label='$sin(x)$') #画图
legend() #添加图例
ax2=subplot(2,2,2) #新建右上2号子窗口
ax2.plot(x,y2,'b--',label='$cos(x)$');
legend()
ax3=subplot(2,1,2) #新建两行、1列的下面子窗口
ax3.plot(x,y3,'k--',label='$sin(x^2)$');
legend();
savefig('figure2_39.png',dpi=500);
show()
三维空间的曲线
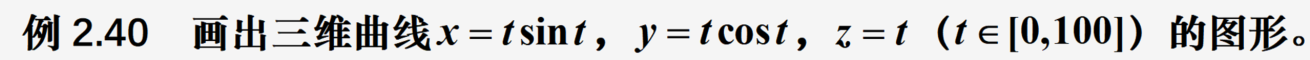
from mpl_toolkits import mplot3d
import matplotlib.pyplot as plt
import numpy as np
ax=plt.axes(projection='3d') #设置三维图形模式
z=np.linspace(0, 100, 1000)
x=np.sin(z)*z;
y=np.cos(z)*z
ax.plot3D(x, y, z, 'k')
plt.savefig('figure2_40.png',dpi=500);
plt.show()
三维曲面图形
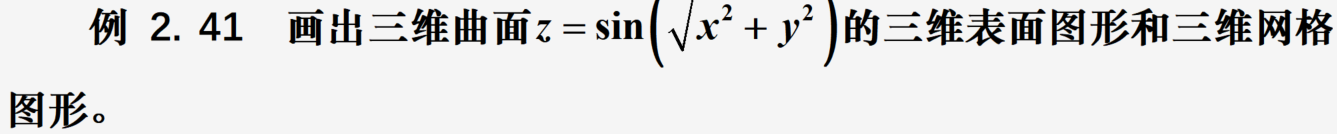
from mpl_toolkits import mplot3d
import matplotlib.pyplot as plt
import numpy as np
x=np.linspace(-6,6,30)
y=np.linspace(-6,6,30)
X,Y=np.meshgrid(x, y)
Z= np.sin(np.sqrt(X ** 2 + Y ** 2))
ax1=plt.subplot(1,2,1,projection='3d')
ax1.plot_surface(X, Y, Z,cmap='viridis')
ax1.set_xlabel('x'); ax1.set_ylabel('y'); ax1.set_zlabel('z')
ax2=plt.subplot(1,2,2,projection='3d');
ax2.plot_wireframe(X, Y, Z,color='c')
ax2.set_xlabel('x'); ax2.set_ylabel('y'); ax2.set_zlabel('z')
plt.savefig('figure2_41.png',dpi=500); plt.show()
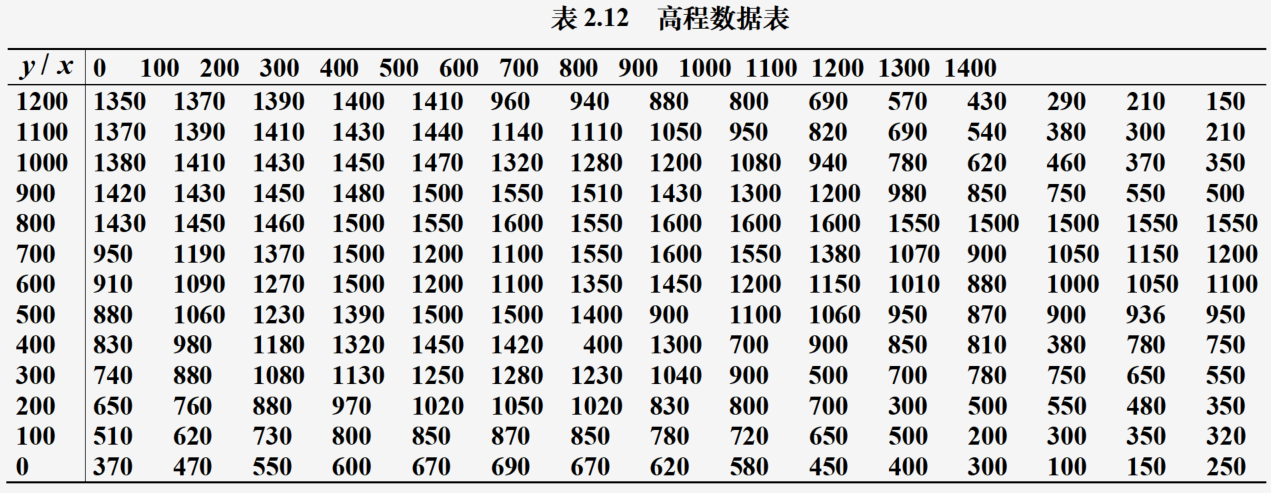
等高线图
画出区域的等高线和三维表面图
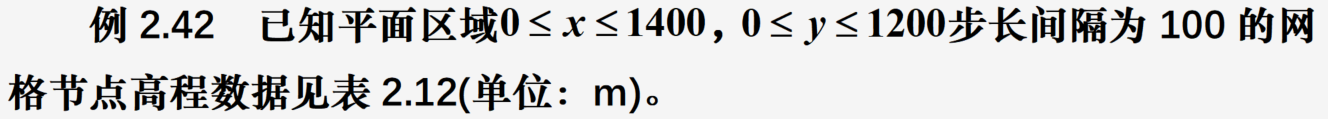
from mpl_toolkits import mplot3d
import matplotlib.pyplot as plt
import numpy as np
z=np.loadtxt("Pdata2_42.txt") #加载高程数据
x=np.arange(0,1500,100)
y=np.arange(1200,-10,-100)
contr=plt.contour(x,y,z); plt.clabel(contr) #画等高线并标注
plt.xlabel('$x$'); plt.ylabel('$y$',rotation=0)
plt.savefig('figure2_42_1.png',dpi=500)
plt.figure() #创建一个绘图对象
ax=plt.axes(projection='3d') #用这个绘图对象创建一个三维坐标轴对象
X,Y=np.meshgrid(x,y)
ax.plot_surface(X, Y, z,cmap='viridis')
ax.set_xlabel('x'); ax.set_ylabel('y'); ax.set_zlabel('z')
plt.savefig('figure2_42_2.png',dpi=500); plt.show()
可视化综合应用
使用subplot函数将多种图形组合在一起
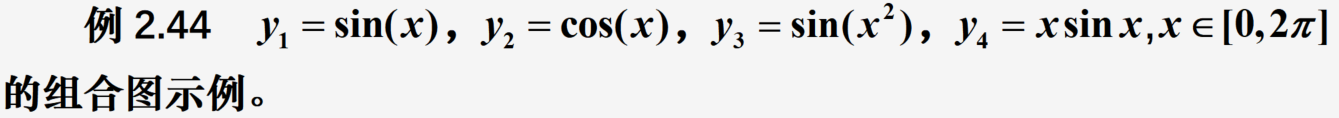
import numpy as np
from matplotlib.pyplot import *
x=np.linspace(0,2*np.pi,200)
y1=np.sin(x); y2=np.cos(x); y3=np.sin(x*x); y4=x*np.sin(x)
rc('font',size=16); rc('text', usetex=True) #调用tex字库
ax1=subplot(2,3,1) #新建左上1号子窗口
ax1.plot(x,y1,'r',label='$sin(x)$') #画图
legend() #添加图例
ax2=subplot(2,3,2) #新建2号子窗口
ax2.plot(x,y2,'b--',label='$cos(x)$'); legend()
ax3=subplot(2,3,(3,6)) #3、6子窗口合并
ax3.plot(x,y3,'k--',label='$sin(x^2)$'); legend()
ax4=subplot(2,3,(4,5)) #4、5号子窗口合并
ax4.plot(x,y4,'k--',label='$xsin(x)$'); legend()
savefig('figure2_44.png',dpi=500); show()
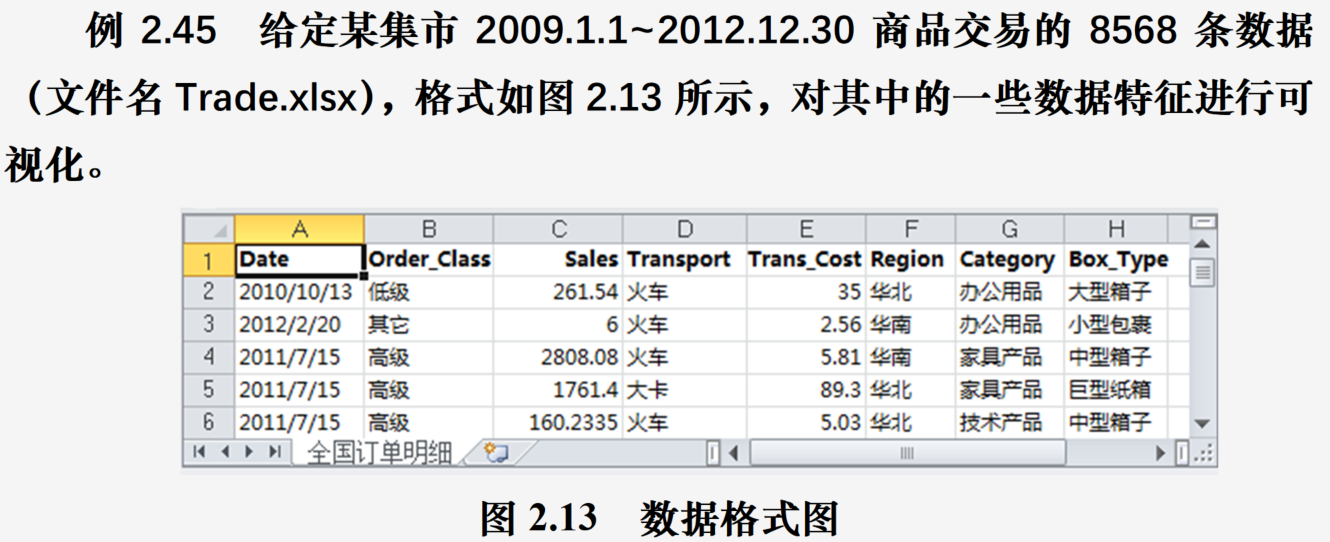
import numpy as np
import pandas as pd
from matplotlib.pyplot import *
a=pd.read_excel("Trade.xlsx")
a['year']=a.Date.dt.year #添加交易年份字段
a['month']=a.Date.dt.month #添加交易月份字段
rc('font',family='SimHei') #用来正常显示中文标签
ax1=subplot(2,3,1) #建立第一个子图窗口
Class_Counts=a.Order_Class[a.year==2012].value_counts()
Class_Percent=Class_Counts/Class_Counts.sum()
ax1.set_aspect(aspect='equal') #设置纵横轴比例相等
ax1.pie(Class_Percent,labels=Class_Percent.index,
autopct="%.1f%%") #添加格式化的百分比显示
ax1.set_title("2012年各等级订单比例")
ax2=subplot(232) #建立第2个子图窗口
#统计2012年每月销售额
Month_Sales=a[a.year==2012].groupby(by='month').aggregate({'Sales':np.sum})
#下面使用Pandas画图
Month_Sales.plot(title="2012年各月销售趋势",ax=ax2, legend=False)
ax2.set_xlabel('')
ax3=subplot(2,3,(3,6))
cost=a['Trans_Cost'].groupby(a['Transport'])
ts = list(cost.groups.keys())
dd = np.array(list(map(cost.get_group, ts)))
boxplot(dd); gca().set_xticklabels(ts)
ax4=subplot(2,3,(4,5))
hist(a.Sales[a.year==2012],bins=40, density=True)
ax4.set_title("2012年销售额分布图");
ax4.set_xlabel("销售额");
savefig("figure2_45.png"); show()
scipy.stats模块简介
随机变量及分布
scipy.stats模块包含多种概率分布的随机变量,随机变量分为连续型和离散型两种
连续型随机变量为rv_continuous的派生类的对象
离散型随机变量为rv_discrete的派生类的对象
连续型随机变量
# 获得scipy.stats模块中所有的连续型随机变量
from scipy import stats
[k for k, v in stats.__dict__.items() if isinstance(v, stats.rv_continuous]
常用方法:

常用概率密度函数:

正态分布的主要函数:

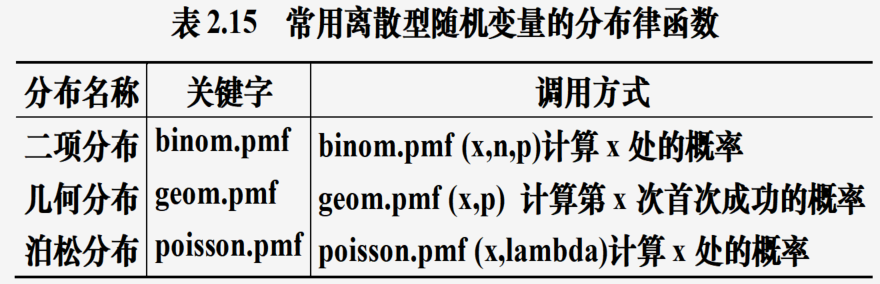
离散型随机变量
# 获得scipy.stats模块中所有的离散型随机变量
from scipy import stats
[k for k, v in stats.__dict__.items() if isinstance(v, stats.rv_discrete)]
常用概率密度函数:
概率密度函数可视化
看一个Gamma分布的例子
# 四条Gamma分布的图形
from pylab import plot, legend, xlabel, ylabel, savefig, show, rc
from scipy.stats import gamma
from numpy import linspace
x=linspace(0,15,100); rc('font',size=15); rc('text', usetex=True)
plot(x,gamma.pdf(x,4,0,2),'r*-',label="$\\alpha=4, \\beta=2$")
plot(x,gamma.pdf(x,4,0,1),'bp-',label="$\\alpha=4, \\beta=1$")
plot(x,gamma.pdf(x,4,0,0.5),'.k-',label="$\\alpha=4, \\beta=0.5$")
plot(x,gamma.pdf(x,2,0,0.5),'>g-',label="$\\alpha=2, \\beta=0.5$")
legend(); xlabel('$x$'); ylabel('$f(x)$')
savefig("figure2_46.png",dpi=500); show()
正态分布
# 四个正态分布的图形
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import norm
mu0 = [-1, 0]; s0 = [0.5, 1]
x = np.linspace(-7, 7, 100); plt.rc('font',size=15)
plt.rc('text', usetex=True); plt.rc('axes',unicode_minus=False)
f, ax = plt.subplots(len(mu0), len(s0), sharex=True, sharey=True)
for i in range(2):
for j in range(2):
mu = mu0[i]; s = s0[j]
y = norm(mu, s).pdf(x)
ax[i,j].plot(x, y)
ax[i,j].plot(1,0,label="$\\mu$ = {:3.2f}\n$\\sigma$ = {:3.2f}".format(mu,s))
ax[i,j].legend(fontsize=12)
ax[1,1].set_xlabel('$x$')
ax[0,0].set_ylabel('pdf($x$)')
plt.savefig('figure2_47.png'); plt.show()
二项分布
# 二项分布
from scipy.stats import binom
import matplotlib.pyplot as plt
import numpy as np
n, p=5, 0.4
x=np.arange(6); y=binom.pmf(x,n,p)
plt.subplot(121); plt.plot(x, y, 'ro')
plt.vlines(x, 0, y, 'k', lw=3, alpha=0.5) #vlines(x, ymin, ymax)画竖线图
#lw设置线宽度,alpha设置图的透明度
plt.subplot(122); plt.stem(x, y, use_line_collection=True)
plt.savefig("figure2_48.png", dpi=500); plt.show()
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- [javascript]使用fs.existsSync方法判断文件是否存在时,返回值一直是false
- 如何在自己的项目中使用私有Go模块
- VMware15安装Linux,CentOS-7x86_64
- FPGA 底层资源介绍
- 30天精通Nodejs--第二十一天:express-依赖注入
- Matlab交互式的局部放大图
- 1.Swing的概述(JFrame和JDialog)
- 【RK3288 Android6 T8, 突然无声音问题排查】
- 哈希排序C++
- 分布式缓存Redis