VGAN实现视网膜图像血管分割(基于pytorch)
背景介绍
另一方面,刚好这个项目作为我2023年的最后一个项目,就斗胆当作是2023年编程之旅的回顾,博主是在茫茫知识海洋漂泊的一叶小舟,还有许多的知识尚未学习,希望可以和大家互相交流学习!
2024年,冲鸭!!!!!
前言
生成对抗网络(Generative Adversarial Networks)在提出的时候是为了实现模型创造性的能力,如今在AI图像生成领域已经有非常广阔的应用,例如知名的Midjourney网站,就是通过用户输入的prompt提示,利用GAN的框架生成对应用户想要生成的图片;我自己对于这个模型的名声也是早有耳闻,刚好前一段时间看到了《Retinal Vessel Segmentation in Fundoscopic Images with Generative Adversarial Networks》这篇文章,内容里探究了把GAN模型应用到视网膜血管分割的领域,刚好可以与我本学期的生物医学创新实践联系在一起。
生成对抗网络介绍
生成对抗网络(Generative Adversarial Network)简称GAN,是深度学习领域的一种重要模型,由Ian Goodfellow在2014年提出。
GAN模型包括两部分:一个是生成器(Generator),另一个是判别器(Discriminator)。这两部分模型相互博弈,共同训练,赋予网络生成特定分布的数据的能力。
1. 生成器(Generator):该部分的目标是生成尽可能真实的数据。例如,如果我们想让网络生成一张风景图片,生成器的目标就是生成一张看上去就像是某个摄影师拍摄的风景照片。
2. 判别器(Discriminator):该部分的目标是尽可能好地区分出真实的和生成的数据。在风景图片的例子中,判别器需要区分出哪些图片是真实的风景照片,哪些是生成器生成的假照片。
两者相互博弈的过程中,判别器会不断提高对真假数据的判断能力,生成器也会不断提高生成数据的逼真度,理想状态下,生成器生成的数据将和真实数据无法区分,判别器对生成器的生成结果的判断是50%,即做出了随机猜测。这样,就完成了GAN的训练过程。
视网膜分割的GAN模型(VGAN)
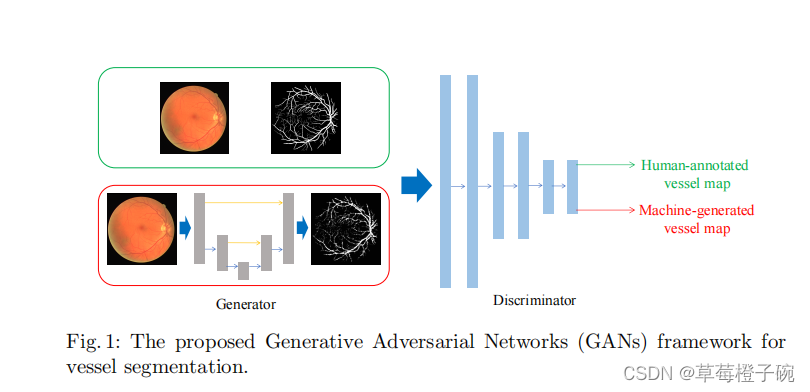
从上图中可以看出,模型中的GAN的generator是一个U-net形状的网络模型,每一层上采样层都与对称的下采样的输出进行连接,能够很好的处理图像的边缘及其他的细节特征;discriminator是一个多层的下采样的网络模型,最后是输出是实现一个二分类的效果,即,接近0表示判断机器生成的(generator),接近1表示判断为真实的血管分割标签,每层的generator和discriminator都是由基本的block卷积神经网络组成,block的代码构建为:
class block(nn.Module):
def __init__(self,in_filters,n_filters):
super(block,self).__init__()
self.deconv1 = nn.Sequential(
nn.Conv2d(in_filters, n_filters, 3, stride=1, padding=1),
nn.BatchNorm2d(n_filters),
nn.ReLU())
def forward(self, x):
x=self.deconv1(x)
return x?是用nn.Sequential()连接的包含卷积,标准化和池化的经典卷积层,卷积核为,步长为1,边缘补充为1,处理的视网膜图片是三通道彩色图盘,第一层的intput_channel为3;下面用pytorch的tensorboard工具对搭建的generator和discriminator进行网络结构的可视化


这里需要注意的是,在原论文中,Discriminator的输入并不是Generator直接生成的图片或者原数据集中的label,而是需要在C通道上与进行分割的原视网膜图片进行合并再进行输入。
损失函数
在训练Generator和训练Discriminator时,使用不同的损失函数,我们最后是使用Generator进行mask的生成,也就是使用Generator输入需要进行视网膜血管分割的图片,输出分割的结果,所以我们更加注重Generator损失函数的设计。
GAN整体的损失函数可以定义为

对于D(Discriminator),在代码中不设计具体的损失函数,从任务设计中可以得出,当输入到D的是真实的标签图像时,我们期望D输出越接近1越好;当输入到D的是Generator生成的图像时,我们期望D输出越接近0越好,基于这种关系,我们直接把D的输出作为损失函数,同时,为了避免GAN模型中常见的断层问题,引入了经典的WGAN方法(Gradient Penalty),即获得一个1-Lipschitz函数,保证GAN模型的训练曲线是足够平滑从而生成稳定的图片,在梯度计算中引入 作为梯度惩罚,则D的损失函数可以表示为:
作为梯度惩罚,则D的损失函数可以表示为:
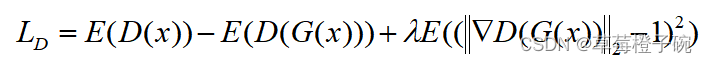
对于G,为适应分割的任务不需要使用隐含空间的向量而是直接获取img的输入,具体地,在代码中使用二分类交叉熵损失函数获取与对应标签的loss值,同时加上来自D的反馈,具体的损失函数为:
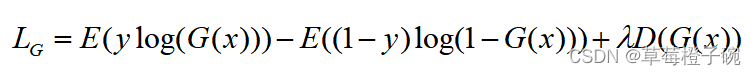
数据集预处理
本次项目使用的数据集是经典的视网膜血管分割数据集,含有20张训练集和20张测试集,每张视网膜眼底的图片是像素的三通道彩色tif格式图片,对应的标签是
像素单通道灰度tif图片
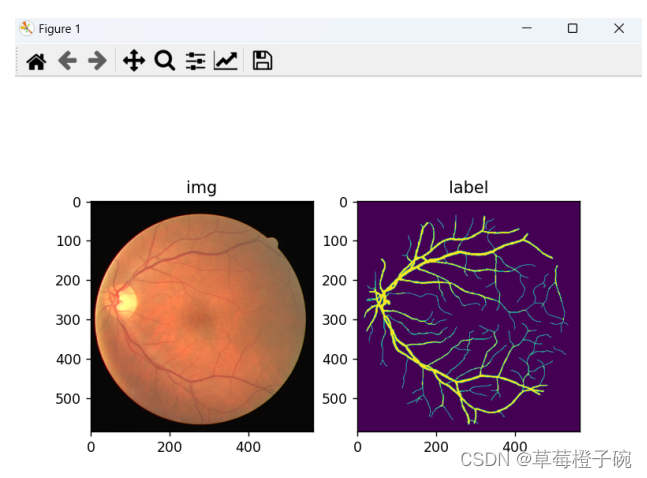
对img的预处理包括随机改变图片的亮度、对比度和色相,图片像素标准化、转换成tensor数据的经典图片训练格式[B,C,H,W];
对label的预处理包括图片像素标准化、转换成tensor数据的经典图片训练格式[B,C,H,W];
同时对img和label的预处理包括随机裁剪图片高和宽为像素大小,随机水平翻转和垂直翻转;
下面是对训练数据中的进行预处理后的结果可视化
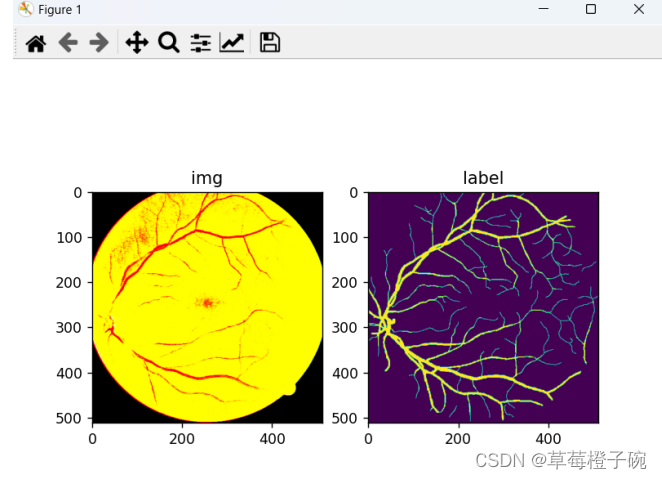
训练过程
一开始打算把本项目放到colab上跑或者服务器上跑,在此之前抱着试一试的态度先用本地的显卡1080ti加4G显存跑了50个epoch,结果竟然能跑得动!于是就先跑了300个epoch,显卡没崩,结果保存在./pth中。
对于GAN的结果,除了使用传统的评估方法外,也会对训练过程的结果进行输出可视化看看结果有没有生成奇奇怪怪的图像从而停止训练重新调整,不过对于本次项目,Generator的输入不包含隐含空间z,而且加入了WGAN进行约束,所以生成的图像基本上是比较完整的;作为视觉上直观地对GAN的效果进行评估,我们每跑50个epoch对应输出测试集生成的分割图像,保存在对应的文件夹名称里面,跑完全部epoch后,对应把D和G训练好的checkpoint也保存在./pth路径下。
300个epoch跑了一个多小时,显卡的散热吹风机感觉可以起飞了,不过结果其实可圈可点,为了不浪费训练好的资料,后面又写了一个re_train脚本,读取前一次训练好的模型权重再进行训练,又花了一个小时跑了300个epoch,结果保存在./pth2目录下,结构与./pth中文件相同,所以综合起来一共训练了600个epoch。
结果分析
?先对比每50个epoch生成的图像,选取测试集中的第一张图片

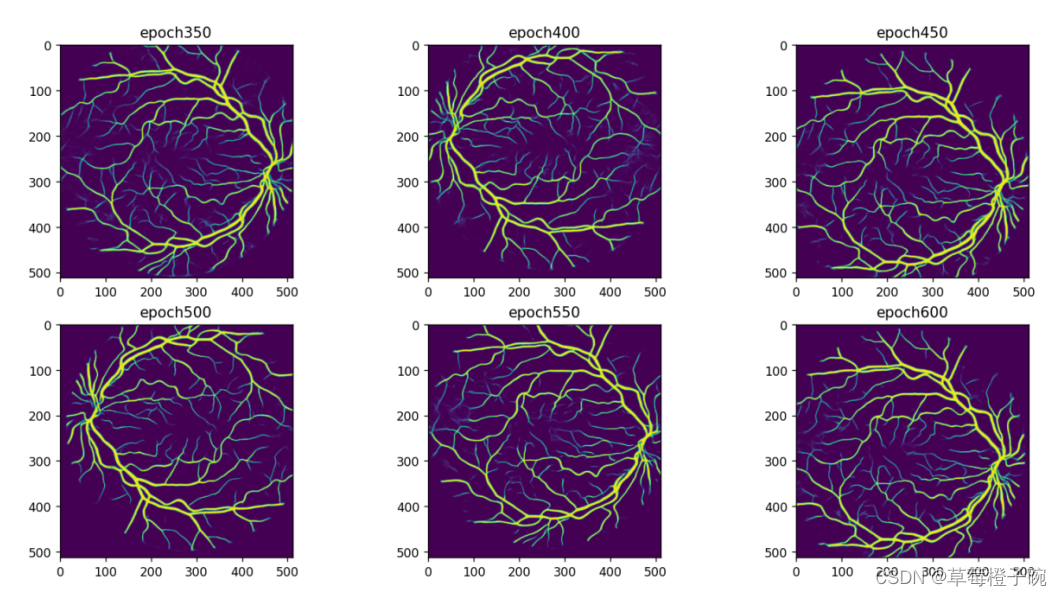
对于测试集的预处理也包括随机裁剪像素像素大小与随机水平翻转与垂直翻转,所以生成的图像包含有不同的方向和裁剪风格。
从第50个epoch到第600个epoch结果,可以明显的看出图片质量提升的效果,说明Generator的学习是非常有效果的,没有出现GAN中经常出现的图片断层效果。
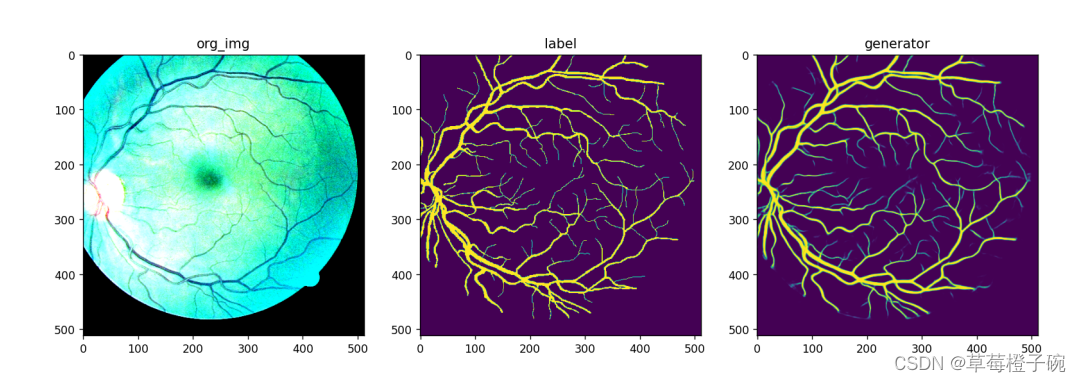
对比一下对应的眼底原图和血管分割标签图:

从视觉上来看,GAN生成图像与原图像的分割标签是比较接近的。
接下来我们使用训练好的Generator模型进行量化的对比:
绘制对应的PR曲线与ROC曲线:

从两个曲线的效果可以看出,训练出来的模型在测试集上也具有比较好的效果,本次项目使用的VGAN在处理视网膜血管分割的任务上体现出比较好的性能。
参考文献
- Son, J., Park, S.J., & Jung, K. (2017). Retinal Vessel Segmentation in Fundoscopic Images with Generative Adversarial Networks. ArXiv, abs/1706.09318.
- Arjovsky, M., Chintala, S., & Bottou, L. (2017). Wasserstein GAN. ArXiv, abs/1701.07875.
彩蛋
我们都知道GAN以创作能力而闻名,那我们试一下用上面训练好的模型接受随机初始化满足正态分布的z隐含空间的数据会输出怎么样的图像
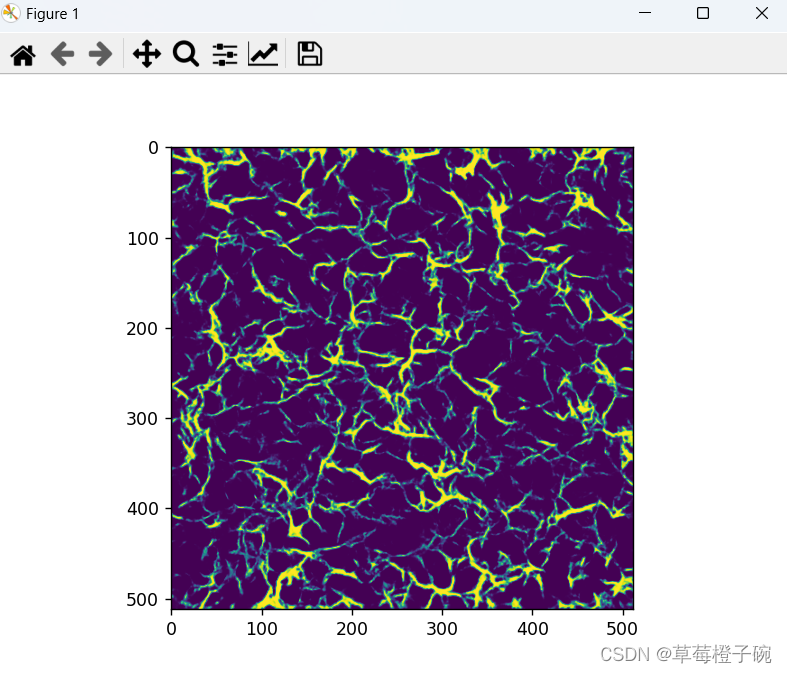
嗯...看来想要GAN生成像样的图片,还是需要再训练机制里面下手
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- LangChain学习二:提示-实战(下半部分)
- 深度掌握 Nginx Ingress:解锁高级功能,打造 Kubernetes 中的流量掌控艺术
- WebGL开发三维解剖学应用
- 四元数的理解
- BurpSuite信息收集篇
- linux设置http代理
- 什么是ERP 企业资源计划(ERP)系统功能作用详细介绍
- brew 安装openapi-generator提示@@HOMEBREW_JAVA@@/bin/java: No such file or directory
- linfeng-love 基于Spring Boot的线上交友系统
- 《WebKit 技术内幕》学习之十(2): 插件与JavaScript扩展