nginx介绍
我们为什么需要学习Nginx呢?高性能,高稳定,优雅的模块化编程等就不提了,就说一个理由:Nginx是目前最受欢迎的web服务器,据统计,全球平均每3个网站,就有一个使用Nginx。如果你不懂Nginx,日常很多工作可能都无法开展。
Nginx总体架构:
Nginx之所以为广大码农喜爱,除了其高性能外,还有其优雅的系统架构。
master进程主要用来管理worker进程,具体包括如下4个主要功能:
接收来自外界的信号。
向各worker进程发送信号。
监控woker进程的运行状态。
当woker进程退出后(异常情况下),会自动重新启动新的woker进程。
与Memcached的经典多线程模型相比,Nginx是经典的多进程模型。Nginx启动后以daemon的方式在后台运行,后台进程包含一个master进程和多个worker进程,具体如下图:
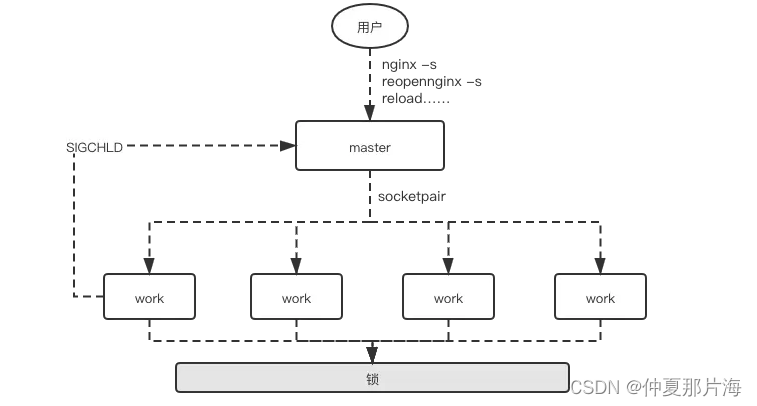
多个worker进程之间是对等且相互独立的,他们同等竞争来自客户端的请求。
一个请求,只可能在一个worker进程中处理,一个worker进程,不可能处理其它进程的请求。
worker进程的个数是可以设置的,一般我们会设置与机器cpu核数一致。更多的worker数,只会导致进程来竞争cpu资源了,从而带来不必要的上下文切换。而且,nginx为了更好的利用多核特性,具有cpu绑定选项,我们可以将某一个进程绑定在某一个核上,这样就不会因为进程的切换带来cache的失效
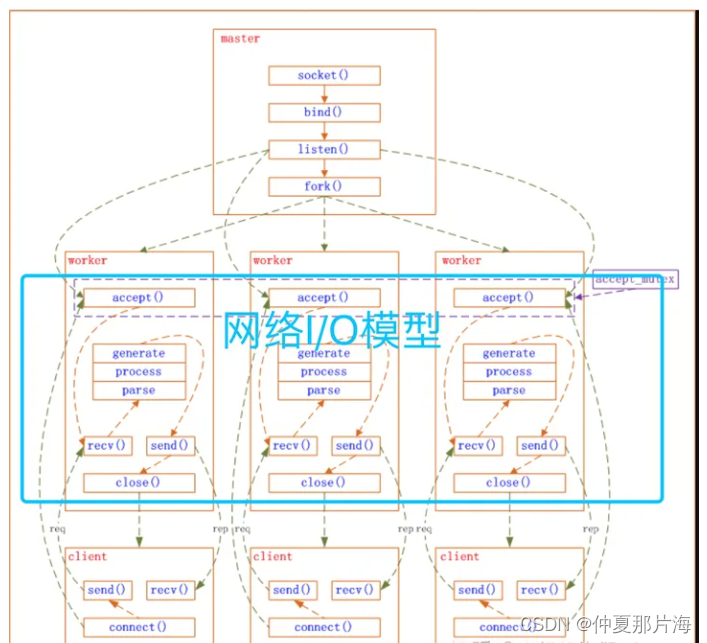
Nginx的socket实现大体逻辑
master进程先建好需要listen的socket后,然后再fork出多个woker进程,这样每个work进程都可以去accept这个socket。当一个client连接到来时,所有accept的work进程都会受到通知,但只有一个进程可以accept成功,其它的则会accept失败。Nginx提供了一把共享锁accept_mutex来保证同一时刻只有一个work进程在accept连接,从而解决惊群问题。当一个worker进程accept这个连接后,就开始读取请求,解析请求,处理请求,产生数据后,再返回给客户端,最后才断开连接,这样一个完成的请求就结束了。
Nginx由内核和模块组成
核心主要用于提供Web Server的基本功能,以及Web和Mail反向代理的功能;还用于启用网络协议,创建必要的运行时环境以及确保不同的模块之间平滑地进行交互。
不过,大多跟协议相关的功能和某应用特有的功能都是由nginx的模块实现的。这些功能模块大致可以分为:事件模块、阶段性处理器、输出过滤器、变量处理器、协议、upstream和负载均衡几个类别,这些共同组成了nginx的http功能。
事件模块主要用于提供OS独立的(不同操作系统的事件机制有所不同)事件通知机制如kqueue或epoll等。
协议模块则负责实现nginx通过http、tls/ssl、smtp、pop3以及imap与对应的客户端建立会话。在Nginx内部,进程间的通信是通过模块的pipeline或chain实现的;换句话说,每一个功能或操作都由一个模块来实现。例如,压缩、通过FastCGI或uwsgi协议与upstream服务器通信,以及与memcached建立会话等。
| 模块 | 功能 |
|---|---|
| ngx_epoll_module | 基于epoll的事件处理模块 |
| ngx_http_limit_req_module | 按请求qps限流 |
| ngx_http_proxy_module | 按HTTP协议转发请求到上游 |
| ngx_http_fastcgi_module | 按fastcgi协议转发请求到上游 |
| ngx_http_upstream_ip_hash_module | iphsh负载均衡 |
| … | … |
模块使用
以下是nginx官网提供的附加模块
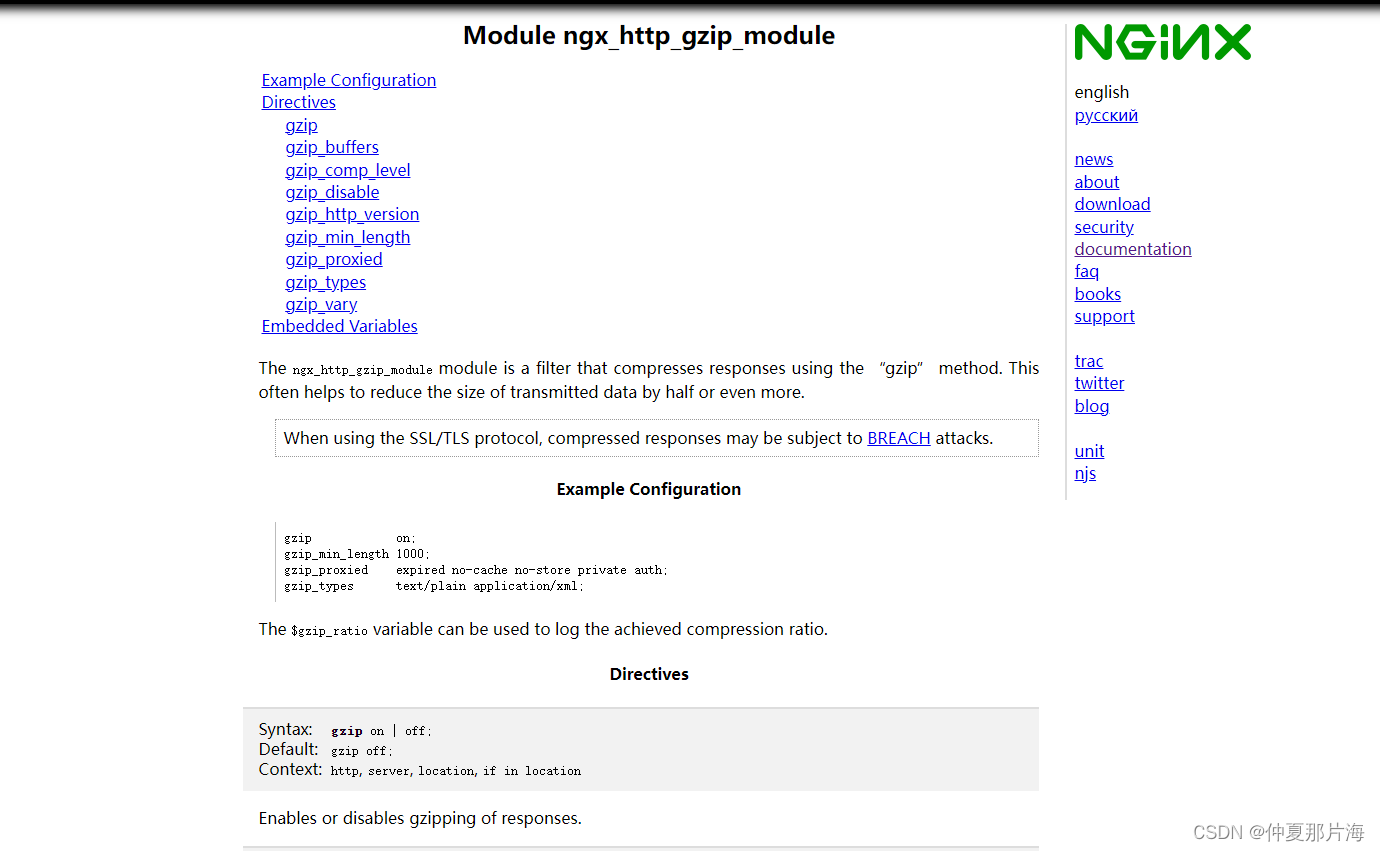
以ngx_http_gzip_module举例:
点击进入ngx_http_gzip_module链接进入可看到配置信息和说明
这里不详细讲如何配置-后面的文章将如何配置
惊群现象
什么事惊群现象
惊群简单来说就是多个进程或者线程在等待同一个事件,当事件发生时,所有线程和进程都会被内核唤醒。唤醒后通常只有一个进程获得了该事件并进行处理,其他进程发现获取事件失败后又继续进入了等待状态,在一定程度上降低了系统性能。具体来说惊群通常发生在服务器的监听等待调用上,服务器创建监听socket,后fork多个进程,在每个进程中调用accept或者epoll_wait等待终端的连接。
nginx的惊群现象
每个worker进程都是从master进程fork过来。在master进程里面,先建立好需要listen的socket之 后,然后再fork出多个worker进程,这样每个worker进程都可以去accept这个socket(当然不是同一个socket,只是每个进程 的这个socket会监控在同一个ip地址与端口,这个在网络协议里面是允许的)。一般来说,当一个连接进来后,所有在accept在这个socket上 面的进程,都会收到通知,而只有一个进程可以accept这个连接,其它的则accept失败。
nginx如何处理惊群
内核解决epoll的惊群效应是比较晚的,因此nginx自身解决了该问题(更准确的说是避免了)。其具体思路是:不让多个进程在同一时间监听接受连接的socket,而是让每个进程轮流监听,这样当有连接过来的时候,就只有一个进程在监听那肯定就没有惊群的问题。具体做法是:利用一把进程间锁,每个进程中都尝试获得这把锁,如果获取成功将监听socket加入wait集合中,并设置超时等待连接到来,没有获得所的进程则将监听socket从wait集合去除。这里只是简单讨论nginx在处理惊群问题基本做法,实际其代码还处理了很多细节问题,例如简单的连接的负载均衡、定时事件处理等等。
核心的代码如下
void ngx_process_events_and_timers(ngx_cycle_t *cycle){
...
//这里面会对监听socket处理
//1、获得锁则加入wait集合,没有获得则去除
if (ngx_trylock_accept_mutex(cycle) == NGX_ERROR) {
return;
}
...
//设置网络读写事件延迟处理标志,即在释放锁后处理
if (ngx_accept_mutex_held) {
flags |= NGX_POST_EVENTS;
}
...
//这里面epollwait等待网络事件
//网络连接事件,放入ngx_posted_accept_events队列
//网络读写事件,放入ngx_posted_events队列
(void) ngx_process_events(cycle, timer, flags);
...
//先处理网络连接事件,只有获取到锁,这里才会有连接事件
ngx_event_process_posted(cycle, &ngx_posted_accept_events);
//释放锁,让其他进程也能够拿到
if (ngx_accept_mutex_held) {
ngx_shmtx_unlock(&ngx_accept_mutex);
}
//处理网络读写事件
ngx_event_process_posted(cycle, &ngx_posted_events);
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!