VALL-E X语音大模型,支持跨语言文本语音合成、语音克隆
引言
“ Speak Foreign Languages with Your Own Voice: Cross-Lingual Neural Codec Language Modeling ”。
微软亚洲研究院最近发布了 VALL-E X,可以通过一个几秒的源语音片段生成目标语言的语音,并保留说话者的声音、情感和声学环境。VALL-E X 不需要说话人的跨语言语音进行训练即可执行各种语音生成任务,例如跨语言文本到语音、语音合成和语音到语音翻译。
VALL-E X 的应用范围非常广泛,可以用于跨语言文本到语音、语音合成和语音到语音翻译等各种任务。无论是商业用途还是个人用途,VALL-E X都可以帮助用户更轻松地进行跨语言交流和文本转语音任务。

论文地址:https://arxiv.org/pdf/2303.03926
Github地址:GitHub - Plachtaa/VALL-E-X
HuggingFace地址:https://huggingface.co/spaces/Plachta/VALL-E-X
项目主页:VALL-E (X)
1 摘要
本文提出了一种跨语言神经编解码器语言模型VALL-E X,用于跨语言语音合成。该模型可以通过使用源语言语音和目标语言文本作为提示来预测目标语言语音的声学令牌序列。实验结果表明,VALL-E X可以通过仅使用源语言语音作为提示来生成高质量的目标语言语音,同时保留未见过的说话者的声音、情感和声学环境。此外,VALL-E X有效地缓解了外语口音问题,可以通过语言ID进行控制。
2 简介
近年来,端到端的文本到语音合成技术取得了显著进展,但是跨语言语音合成的质量仍然落后于单语言模型,原因在于数据稀缺和模型能力不足。跨语言语音合成是一个新兴的任务,旨在将说话者的声音从一种语言转移到另一种语言。现有模型只能为特定语言和特定说话者生成高质量的语音。
以往的方法在端到端的TTS模型中加入特定的子网络来解决说话人和语言控制的挑战。然而,这些方法在零样本情况下合成目标语音时效果不佳,并且常常存在说话人相似度和第二语言口音的问题。
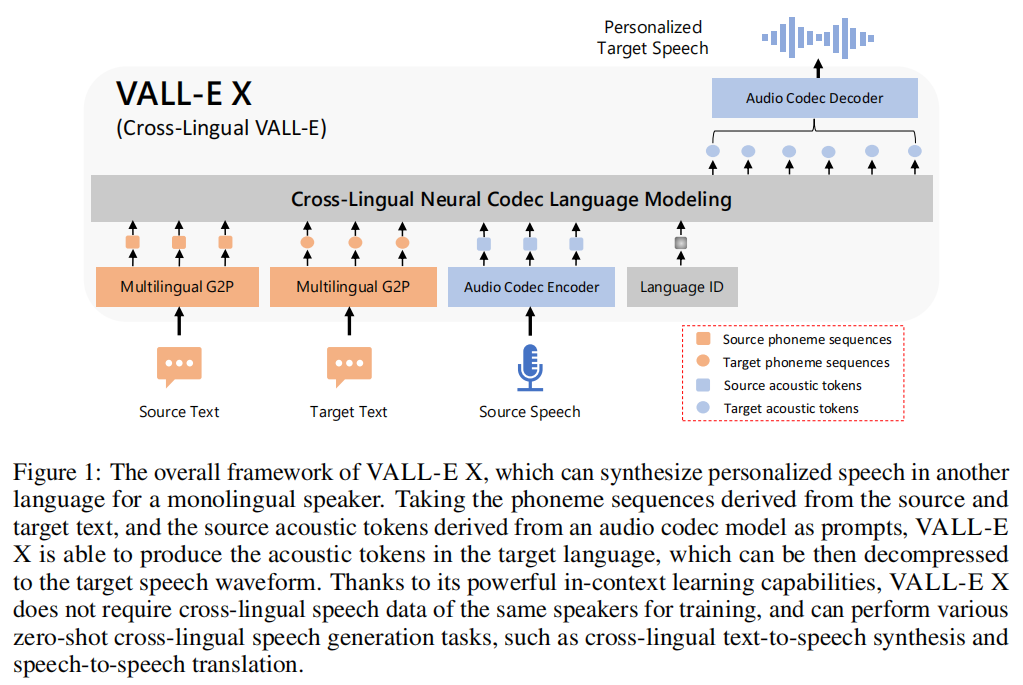
本文提出了一种新颖的跨语言神经编解码语言模型VALL-E X,通过强大的上下文学习能力实现高质量的零-shot跨语言语音合成。VALL-E X能够从源语言转移语音特征,包括说话人的声音、情感和语音背景,并减轻外语口音问题。通过获取多语言语音转录数据和离线神经编解码编码器,训练多语言条件语言模型。VALL-E X在大规模多说话人数据集上进行训练,包括英语有声读物数据和多领域中文ASR数据。VALL-E X是一种跨语言TTS系统,它通过使用多种语言的语音数据来提高覆盖范围和泛化能力。与以前的跨语言TTS系统相比,VALL-E X有更好的表现。
分别在零样本跨语言文本到语音合成和零样本语音到语音翻译两种跨语言语音生成任务上实验。VALL-E X框架在英语和中文的数据集上进行了评估,包括英语TTS和中文TTS,以及中英双向翻译任务。实验结果表明,VALL-E X在说话人相似度、语音质量、语音自然度和人类评估等方面均表现出色,优于强基线模型。作者的贡献在于提出了一种有效的跨语言语音生成框架,可以在不同语言之间实现高质量的语音合成和翻译。

本文贡献如下:
-
介绍了一种跨语言神经编解码器语言模型VALL-E X,利用大规模多语言、多说话人、多领域的不干净语音数据进行训练。
-
本模型可以生成跨语言语音,保持未知说话人的声音、情感和语音背景,只需一个源语言句子作为提示。
-
基于学习到的跨语言语音建模能力,VALL-E X可以为任何说话人生成本地语言的语音,并显著减少跨语言语音合成任务中的外语口音问题。
-
实验结果表明,VALL-E X在零样本跨语言文本到语音合成和零样本跨语言语音到语音翻译任务中表现优异。
3 相关工作
语音和音频合成。 近年来,神经网络的快速发展使得语音和音频合成取得了巨大进展,包括WaveNet、HiFi- GAN和Diffwave等不同的网络框架。学术和工业界也越来越关注从文本合成语音或声音,即文本到语音(TTS)或文本到声音。最近,将离散音频表示学习应用于音频合成也开始出现。与我们最相关的工作是VALL-E,它利用神经编解码语言模型实现单语文本到语音合成。VALL- E在大规模语音数据上训练,具有强大的内容学习能力,可以合成高质量的个性化语音。
跨语言语音合成 现有研究成果,包括使用共享音素输入表示和对抗目标来实现跨语言语音克隆、使用共享音素集和语音编码器模块来增强跨语言能力、通过多任务学习来提高合成语音与本地语音的相似度等。然而,现有方法仍存在说话人相似度低和零样本能力不足的问题。本文提出了一种基于神经编解码器语言模型的框架,利用大规模多语言多说话人ASR数据的上下文学习能力,有效缓解了这些问题。
语音到语音翻译(S2ST) 旨在将一种语言的语音翻译成另一种语言的语音。目前的研究主要集中在级联S2ST系统和端到端S2ST模型上。然而,目前仍存在一个未解决的问题,即如何在生成的语音中保留源语音的声音特征。为了解决这个问题,我们提出了一种跨语言神经编解码器语言模型,并展示了它在S2ST任务中保留声音特征的零- shot能力。
4 跨语言编解码器语言模型
4.1 背景
VALL-E X是跨语言的文本到语音合成器,采用神经编解码语言模型作为中间表示,将TTS视为条件语言建模任务。与传统的TTS方法不同,VALL- E采用声学令牌作为中间表示。VALL-E是一个使用两阶段建模的语音编解码器,可以生成个性化语音。VALL-E X是其跨语言版本,支持零- shot跨语言能力和跨语言TTS或语音翻译任务。它在大规模英语语音转录数据集上训练,具有强大的上下文学习能力。第一阶段使用自回归语言模型生成编解码器代码,第二阶段使用非自回归模型并行生成其余量化器的代码。
4.2 模型架构
 VALL-E X是一个跨语言编解码语言模型,利用多语言自回归编解码模型和多语言非自回归编解码模型生成不同粒度的声学标记。EnCodec是我们采用的神经编解码模型,用于声学量化。在我们的实验中,我们选择了8个量化层,每层以75Hz生成1024个量化代码。
VALL-E X是一个跨语言编解码语言模型,利用多语言自回归编解码模型和多语言非自回归编解码模型生成不同粒度的声学标记。EnCodec是我们采用的神经编解码模型,用于声学量化。在我们的实验中,我们选择了8个量化层,每层以75Hz生成1024个量化代码。
多语言自回归编解码器LM。 LMφMAR是一个多语言自回归编解码器,根据语义标记(音素序列)自回归生成声学标记。为了提高句子级训练效率和推理过程中的解码速度,类似于VALL-E,跨语言自回归编解码器φMAR仅用于从EnCodec模型的第一个量化器预测声学标记。
模型使用配对的语音转录数据,将语音转录为音素序列S和第一层声学令牌A1。通过训练自回归解码器φMAR,模拟S和A1的连接序列,预测A1。优化目标是最大化对数似然。
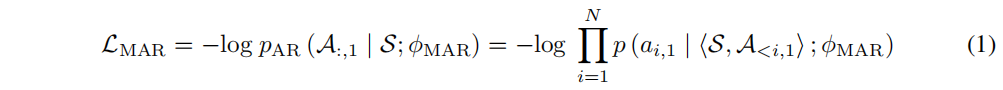 多语言非自回归编解码器LM。 LMφMNAR是一种多语言非自回归编解码器语言模型,旨在从第一层开始迭代生成声学令牌的其余层。它使用当前句子的音素序列和具有相同说话人的另一句子的声学令牌序列作为参考,以克隆目标语音。它类似于VALL-E,使用前面层的声学令牌嵌入作为输入来生成每一层的声学令牌。学习目标是生成每一层的声学令牌。
多语言非自回归编解码器LM。 LMφMNAR是一种多语言非自回归编解码器语言模型,旨在从第一层开始迭代生成声学令牌的其余层。它使用当前句子的音素序列和具有相同说话人的另一句子的声学令牌序列作为参考,以克隆目标语音。它类似于VALL-E,使用前面层的声学令牌嵌入作为输入来生成每一层的声学令牌。学习目标是生成每一层的声学令牌。
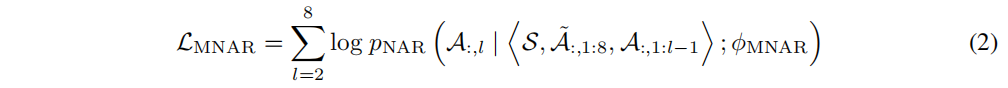
4.3 多语言训练
为了学习跨语言声学转换信息,用于跨语言TTS和语音翻译任务,我们利用双语音频-文本对训练多语言编解码器LMs φMAR和φMNAR。其中,s和t代表两种不同的语言。
语言ID模块。 VALL-E X使用语言ID模块来指导语音生成,以适应不同语言的特点。语言ID可以有效地引导正确的发音风格,并缓解L2口音问题。具体来说,将语言ID嵌入到密集向量中,并添加到声学标记的嵌入中。
4.4 跨语言推理
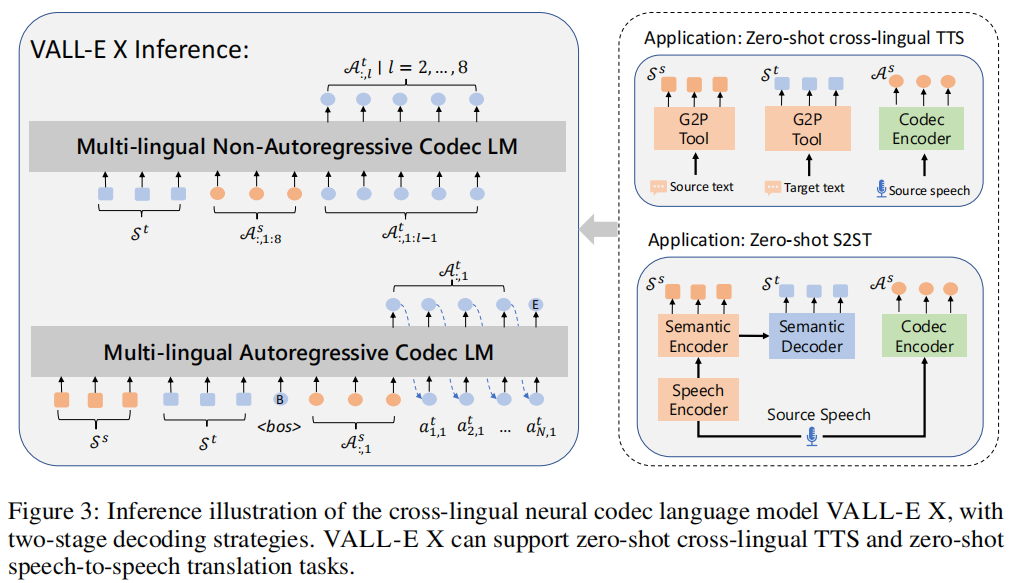
VALL-E X经过训练后可以进行跨语言语音合成。它使用源语言音素和目标语言音素作为提示,并以源语言声学标记作为解码前缀,通过多语言自回归编解码器生成目标语言声学标记。
![]()
基于概率抽样的采样方法,通过停止采样直到遇到句子结束标记。使用语言识别来控制生成语音的说话风格。首先获取第一层目标声学标记,然后使用多语言非自回归编解码器预测剩余层的声学标记。预测过程采用贪婪搜索,选择具有最大概率的标记。
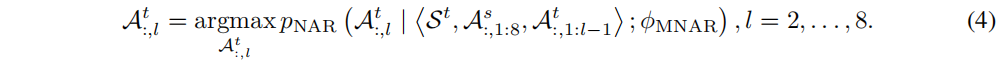
最后,使用EnCodec的解码器从完整的目标声学令牌At:,1:8中合成目标语音。
5 VALL-E X应用
5.1 零样本跨语言TTS
VALL-E X是适用于零样本跨语言TTS任务的模型。传统方法需要使用额外的说话人和语言网络来建模说话人和语言信息,而VALL-E X通过大型语言模型的上下文学习能力,出人意料地展现了零样本跨语言语音合成的能力。具体来说,给定源语音、源文本和目标文本,我们首先使用神经编解码模型EnCodec的编码器将源语音转换为源声学标记As,使用G2P工具将源文本和目标文本转换为源音素Ss和目标音素St。然后,VALL-E X生成完整层的目标声学标记,并通过EnCodec解码器将其解压缩为目标语音。
5.2 语音到语音翻译
我们可以使用VALL-E X来进行零-shot语音到语音翻译任务,需要额外的语音识别和翻译模型,负责同时识别和翻译源语音到源语音和目标音素序列。
语音识别和翻译模型。 使用改进的SpeechUT模型作为语音识别和翻译模型,该模型使用音素作为隐藏单元,支持ASR和ST任务。模型包括语音编码器、音素编码器和音素解码器,通过ASR和MT语料库进行预训练。模型经过预训练后,使用(ST语料库)的(Xs, Ss, St)三元组数据进行微调。在多任务学习中,使用CTC损失函数预测源音素,使用交叉熵损失函数预测目标音素。
推理。 图3展示了语音到语音翻译的推理过程。通过语义编码器和解码器生成源音素和目标音素,同时使用EnCodec编码器将源语音压缩成源声学令牌。将源音素、目标音素和源声学令牌拼接成VALL-E X的输入,生成目标语音的声学令牌序列,并使用EnCodec解码器将其转换为最终的目标语音。
5.3 验证
本文对VALL-E X使用多种评估标准进行了验证,包括说话人相似度、语音质量、翻译质量、自然度和人工评估等。评估结果表明,该系统具有较高的性能和质量。
6 实验
我们在零射跨语言TTS和零射S2ST上评估了提出的模型,包括由中文说话者提示的英文TTS和由英文说话者提示的中文TTS,以及中文→英文和英文→中文方向的零射S2ST。我们在我们的演示页面上提供了合成的音频样本,以更好地展示VALL-E X的性能。
6.1 数据集
VALL-E X使用双语音频转录数据进行训练,其中中文ASR数据来自WenetSpeech,英文ASR数据来自LibriLight。使用Kaldi ASR模型在Librispeech数据集上生成伪转录。
为了训练S2ST的语音识别和翻译模型,我们使用了额外的机器翻译和语音翻译数据。机器翻译数据来自AI Challenger5、OpenSubtitles2018和WMT2020,包含约13M、10M和50M个句子对。语音翻译数据来自GigaST和WenetSpeech,分别用强大的机器翻译系统进行翻译。其中,GigaST是通过翻译GigaSpeech的转录创建的,而WenetSpeech则是通过我们自己训练的机器翻译模型进行翻译的。
本文评估了零样本S2ST 和零样本跨语言TTS的性能,使用了EMIME数据集和Librispeech数据集。EMIME数据集包含25对中英双语句子,共350个测试样例。实验分为两个设置,分别使用Librispeech英语TTS和EMIME中文TTS。
6.2 实验设置
音素化和量化。 本文使用了国际音标为基础的BigCiDian9统一音素集,通过Kaldi强制对齐工具进行转换和对齐,使用神经音频编解码器EnCodec将语音量化为离散编解码器代码。
模型架构。 本模型是用于跨语言编解码器的语言模型,包括LMφMAR和LMφMNAR两种12层Transformer解码器,具有1024的注意力维度和4096的FFN维度。LMφMAR模型通过注意力掩码实现自回归。Sinuous位置嵌入分别为LMφMAR和LMφMNAR模型中的每个提示序列计算。此外,LMφMNAR模型使用单独的层归一化来生成每个声学令牌的每一层。在附录A.1.2中介绍了语音识别和翻译的模型架构。在后续实验中,我们将跨语言TTS模型和S2ST模型称为VALL-E X和VALL-E X Trans。
训练细节。 最大句子长度为20秒,学习率为5e-4,训练步数为800k,LMφMAR的批量大小为每GPU 120秒,LMφMNAR的批量大小为每GPU 66秒。在优化LMφMNAR时,为了提高效率,每次随机选择一层进行优化。语音识别和翻译模型的训练细节可以在附录A.1.3中找到。
基线。 我们采用YourTTS12作为零射多语言TTS的基准。YourTTS是一个适用于所有人的零射多说话人TTS模型,其说话人信息基于从参考语音中提取的说话人嵌入。由于先前的研究表明,当前的端到端S2ST系统表现不如级联的S2ST系统,我们还构建了一个级联的S2ST基准,其中包括一个ASR模型、一个MT模型和一个多说话人的YourTTS。在使用YourTTS合成目标语音时,源语音作为参考语音。ASR模型是在第4.3节介绍的发布的HuBERT模型,MT模型是我们自己在第5.1节介绍的MT数据上训练的一个普通Transformer模型。由于YourTTS仅适用于英语,我们无法得到其在英语→中文翻译方向上的性能。
6.3 零样本跨语言TTS验证
从LibriSpeech dev- clean数据集中选择长度在4到10秒之间的样本,共有40个说话者和1373个样本。对于英文TTS,我们从EMIME数据集中随机选择一个音频作为每个目标句子的中文提示。对于中文TTS,我们使用EMIME数据集提供的额外149个中文文本句子,并将其重复到1373个,以便可以逐个由LibriSpeech音频提示。在合成目标语言语音时,使用源语言语音的整个序列作为提示。
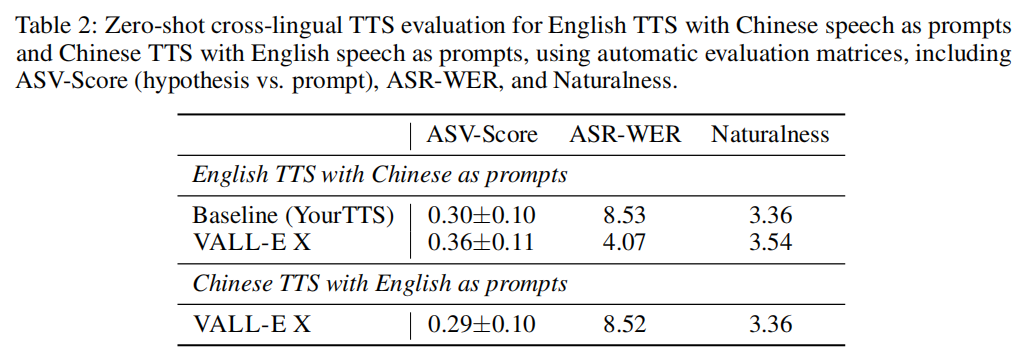
自动评估。 包括中文语音提示的英语TTS和英语语音提示的中文TTS。使用自动说话人验证模型(ASV)来衡量说话人相似度。结果表明,VALL-E X方法比基线更有效,具有更好的说话人相似度、更低的WER和更好的语音自然度。同时,还列出了中文TTS与英语提示的结果。
人脸评估。 使用中文语音作为提示,评估结果表明该模型在保持语音特征方面具有优越性。人工评估结果显示,VALL-E X比基线模型在语音合成质量上获得了更高的分数。

6.4 零样本S2ST验证
S2ST在EMIME数据集上进行了双向中英文评估,评估指标包括说话人相似度、翻译质量、语音自然度和人类评估。
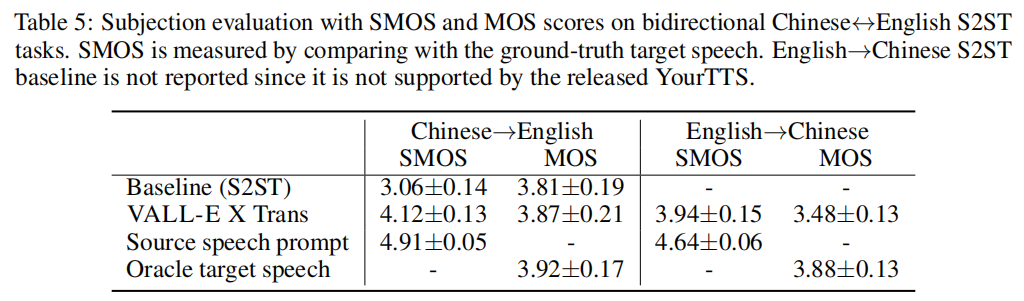
说话人相似度。 本文研究了跨语言语音转换的问题,通过ASV-Score评估了生成语音中是否保留了原始说话人的声音特征。结果表明,VALL-E X Trans模型在中文→英文方向上表现优异,能够有效地保留原始说话人的声音特征。但在英文→中文方向上,跨语言声音转移的可行性仍有待提高。此外,研究还发现,生成语音的质量对声音转移的影响较小。
 翻译质量。 VALL-E X Trans的翻译表4显示了其翻译性能。使用VALL-E X的ASR- BLEU与神谕目标文本作为输入时,可以视为翻译完全正确的上限。使用神谕目标文本作为输入时,VALL-E X Trans可以达到约84~87 BLEU分数的性能,这也反映了我们神经编解码语言模型的高性能。对于中文→英文,VALL-E X Trans在基准线上实现了更高的BLEU分数(30.66 vs. 27.49),这表明将端到端的语音到音素翻译应用于S2ST任务时比传统的级联语音到文本翻译更有效。
翻译质量。 VALL-E X Trans的翻译表4显示了其翻译性能。使用VALL-E X的ASR- BLEU与神谕目标文本作为输入时,可以视为翻译完全正确的上限。使用神谕目标文本作为输入时,VALL-E X Trans可以达到约84~87 BLEU分数的性能,这也反映了我们神经编解码语言模型的高性能。对于中文→英文,VALL-E X Trans在基准线上实现了更高的BLEU分数(30.66 vs. 27.49),这表明将端到端的语音到音素翻译应用于S2ST任务时比传统的级联语音到文本翻译更有效。
演讲自然度。 本文研究了语音翻译任务中的自然度问题,使用开源工具NISQA评估了S2ST输出的自然度。结果表明,相比基线模型,VALL-E X Trans的自然度得分更高,能够生成更自然的目标语言语音。
人类评估。 VALL-E X Trans在说话人相似性评估中表现优于基线模型,但仍有改进空间。在语音质量方面,VALL-E X略优于基线模型。
6.5 分析
本节首先分析了语言识别的影响,然后探讨了外语口音问题,并对我们提出的模型在维持语音情感和合成代码切换语音方面的能力进行了定性调查。
语言ID影响。 本文研究了语言ID对语音合成的影响。实验结果表明,没有或使用错误的语言ID会降低翻译质量,但会增加说话人之间的相似度。这表明语言ID对于内容的准确性非常重要,同时也说明目标语言ID可以减少信息传递,从而更好地保持原始说话人的声音。
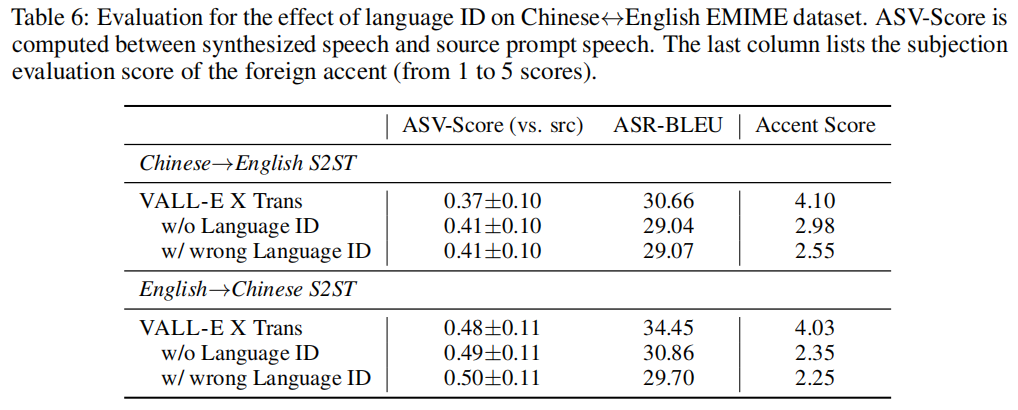 外国口音控制。 研究发现,在跨语言的TTS系统中,语种识别(LID)可以提高语音质量,帮助控制外语口音问题。通过主观评估,发现使用正确的LID嵌入可以减轻外语口音问题。
外国口音控制。 研究发现,在跨语言的TTS系统中,语种识别(LID)可以提高语音质量,帮助控制外语口音问题。通过主观评估,发现使用正确的LID嵌入可以减轻外语口音问题。
语音情感维护。 语音情感维护是语音合成中的难点,传统的TTS方法需要使用带有情感标签的数据进行训练。VALL-E X可以在保持源说话人情感的同时生成目标语音。该模型使用大规模多语言多说话人语音转录数据进行训练,并具有强大的上下文学习能力。实验结果表明,VALL-E X可以在一定程度上保持情感一致性。
转换码语音合成。 VALL-E X模型可以用于生成流畅一致的代码切换语音。该模型在多语言语音数据上训练,具有强大的上下文学习能力。演示页面上的代码切换样本证明了该模型的有效性。
6 总结
本文提出了VALL-E X,一种跨语言神经编解码语言模型,可以在生成的目标语言语音中重新训练源语言说话者的声音。VALL-E X不需要来自同一说话者的跨语言配对数据。通过在大规模多语言多说话者语音转录数据上训练,VALL-E X表现出强大的上下文学习能力,并支持零- shot跨语言文本到语音和零-shot保留语音到语音翻译任务。未来的工作计划是扩大数据和语言范围。
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!