SegVol: Universal and Interactive Volumetric Medical Image Segmentation
Abstract
精确的图像分割为临床研究提供了有意义且结构良好的信息。尽管在医学图像分割方面取得了显著的进展,但仍然缺乏一种能够分割广泛解剖类别且易于用户交互的基础分割模型。
本文提出了一种通用的交互式体医学图像分割模型——SegVol。通过对90k个未标记的CT卷和6k个标记的CT卷进行训练,该基础模型支持使用语义和空间提示对200多个解剖类别进行分割。大量的实验证明,SegVol在多个细分基准测试中表现出色。
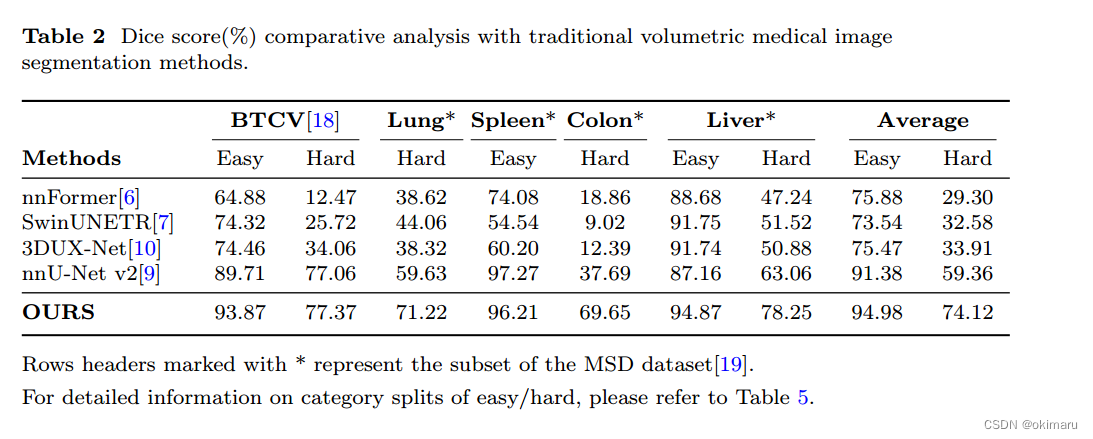
在三个具有挑战性的病变数据集上,该方法比nnU-Net的Dice得分高20%左右。
Introduction
体积图像分割通过准确提取器官、病变和组织等感兴趣的区域,在医学图像分析中起着至关重要的作用,在肿瘤监测[1]、手术计划[2]、疾病诊断[3]、治疗优化[4]等方面有着广泛的临床应用。
SegVol的主要特性总结如下:
1.在96k ct上对模型进行预训练,并利用伪标签来解耦数据集和分割类别之间的虚假相关性。
2. 通过将语言模型集成到分割模型中,并在25个数据集的200多个解剖类别上进行训练,从而实现文本提示分割。
3. 采用协同策略协调语义提示和空间提示,实现高精度分割。
4. 设计一种放大放大机制,显著降低计算成本,同时保持精确分割。
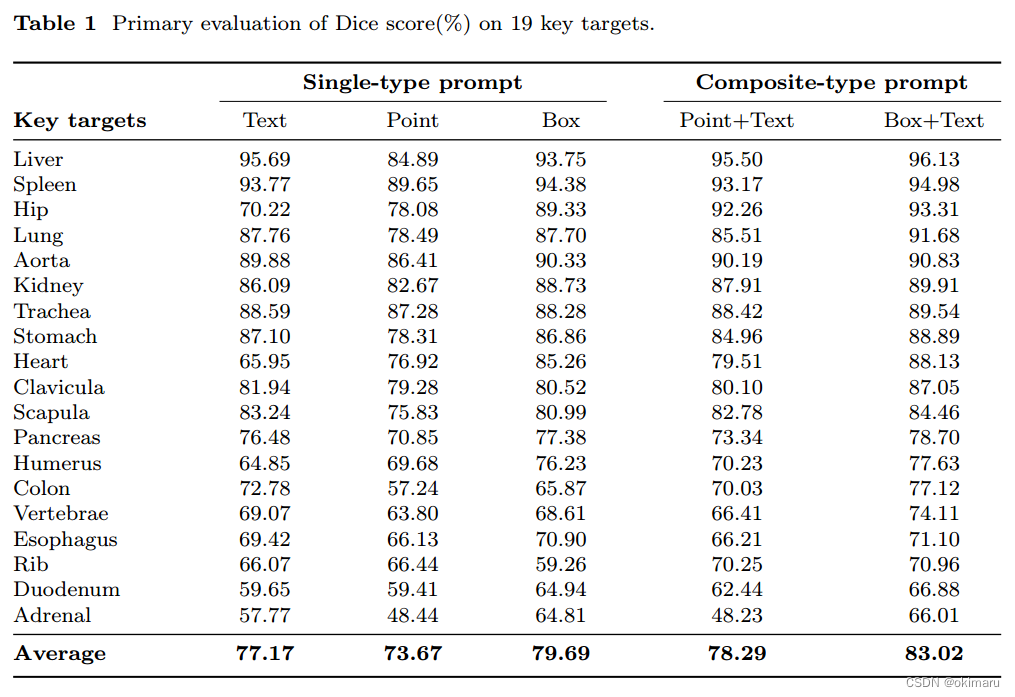
SegVol通用分割能力,Dice平均得分为83.02%。
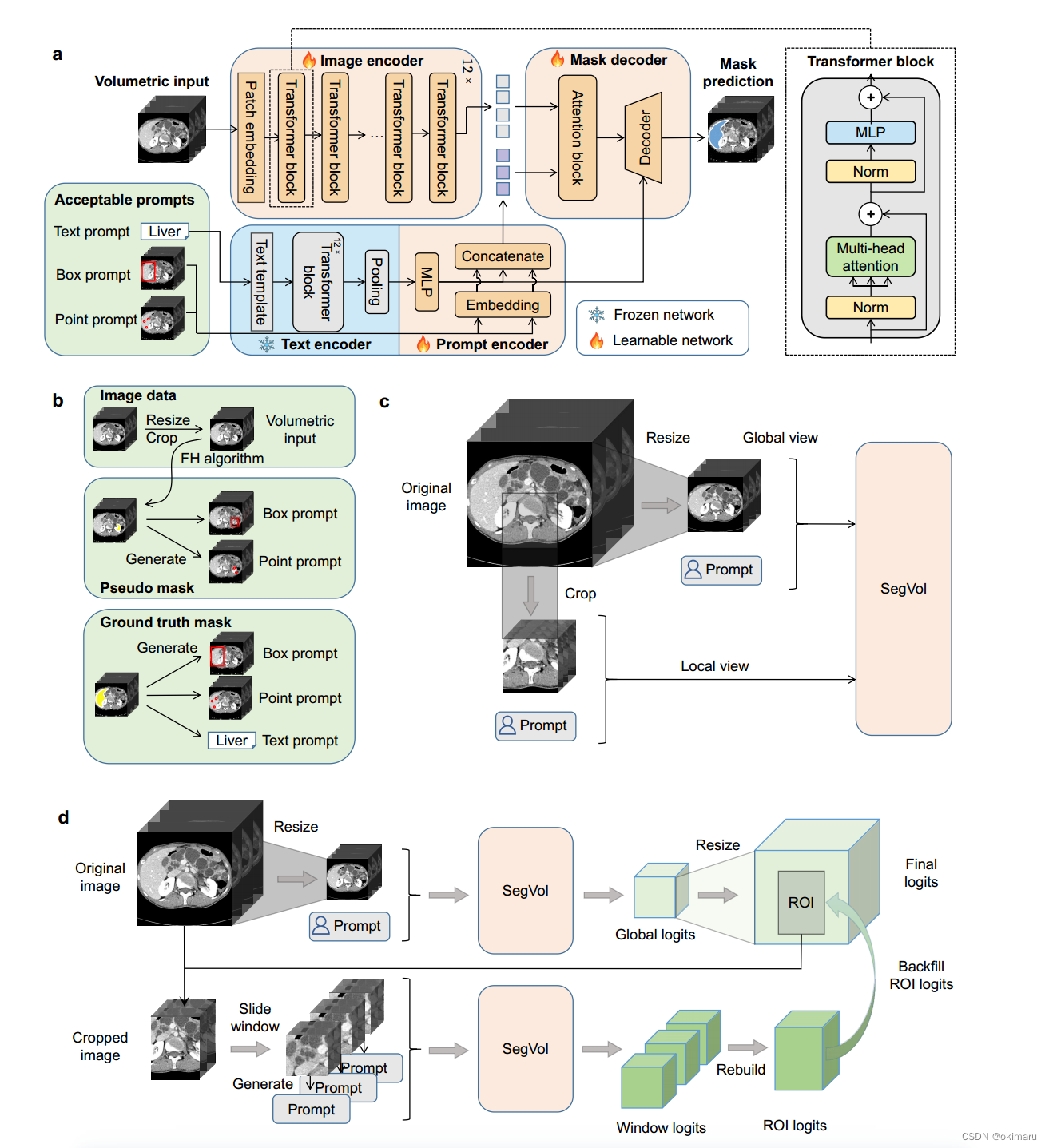
图1所提出的SegVol模型架构概述a. SegVol的主要结构包括图像编码器、文本编码器、提示编码器和掩码解码器。除了文本编码器,所有的网络都是可学习的。图像编码器提取体积输入的图像嵌入。将图像嵌入与提示嵌入一起馈送到解码器中以预测分割掩码。b.输入图像变换及提示符生成说明。c.放大放大训练:SegVol在全局和局部视图的数据上进行训练。d. Zoom-outzoom-in推理:SegVol首先进行全局推理,然后对提取的ROI进行局部推理,以细化结果。
作为一个通用模型,该方法通过“文本”提示为200多个重要器官、组织和病变提供准确的分割结果。作为一种精确的分割模型,它还引入了“点”和“盒”空间提示来指导解剖结构的分割,从而获得高精度的分割响应。为了建立SegVol,从25个开源医疗数据集中收集了6k个带有150k个分割掩码注释的CT。此外,从网络上抓取了90k个未标记的CT数据,并获得了511k个由FH算法生成的伪体积掩码。
Result
如图2 a所示,收集到的关节数据集包括四个主要的人体区域:头颈部、胸腔、腹部和骨盆,包括47个重要区域的200多种器官、组织和病变类型。共有5772个ct参与了联合数据集的训练和测试,总共有149199个带语义的体积掩码标签。来自四个主要人体区域的联合数据集的样本以二维切片的形式显示在图2 c中。为了增强SegVol的空间分割能力,使用FH算法生成510k的伪体积掩码标签来填充这些实例的未注释区域。
数据集可视化
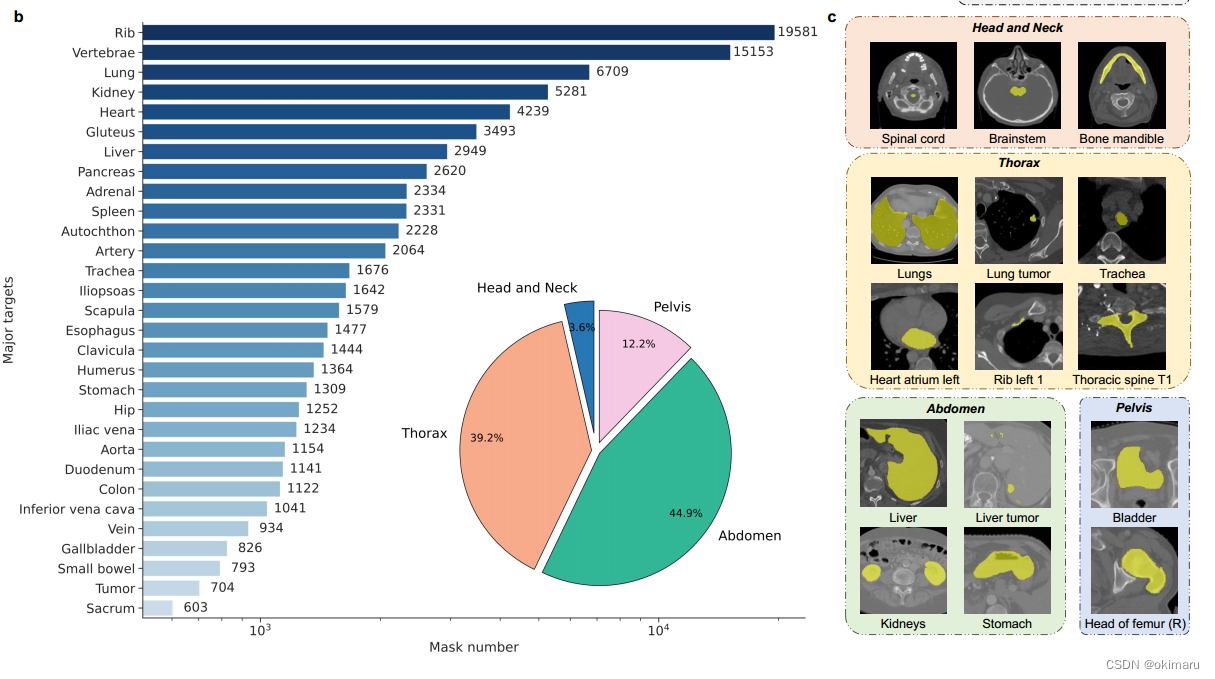
联合数据集的概述和示例。a、联合数据集概述。联合数据集包括47个重要区域,每个区域在该空间区域内包含一个或多个重要的解剖结构。b、联合数据集的主要类别:其掩码标签数量排名前30,在联合数据集内人体四个主要部位的掩码标签数量占比。c,从联合数据集中采样的15个不同类别的器官、组织和病变示例,以切片视图呈现。
SegVol显著优于传统模型的主要有三个因素:
1)固定类集的有限情况限制了传统模型的性能。相反,SegVol具有更广泛的学习范围,因为它结合了25个数据集进行训练。这使得它不仅可以从不同数据集的相同类别中收集知识,还可以从自然语言嵌入空间内固有相关的类别中收集知识。例如,SegVol可以从“左肾”和“肾”类别中学习,因为它们的自然语言相关性。这种从更广泛、更多样化的数据中学习的能力比传统模型更有优势,使其能够理解传统模型可能错过的分割目标的内在相关性。
2)传统模型仅仅依靠整数代码来发现语义信息,而SegVol采用了更全面的快速学习方法。它不仅利用语义提示来理解目标,还利用空间提示来获得对目标的进一步空间认知。这种交互式分割模式使SegVol能够取得明显更好的结果,特别是在硬案例的精确分割中。
3)对大规模未标记数据的预训练使SegVol能够学习更广义的特征表示。该过程显著增强了其对下游任务的适应性和鲁棒性。
Method
医学图像分割数据集D = {(xi, yi)}由一个三维图像基准xi∈RC×D×H×W和K个掩码标签yi∈{0,1}K×D×H×W组成,对应K个目标类别。经典分割模型[5-10]F(?,θ)基于体积输入xi学习预测属于K个类别的掩码yi,即oi = F(xi, θ),其中oi∈RK×D×H×W。因此,传统的模型不能推广到看不见的类别。
受二维自然图像分割的最新进展,分割任何(SAM)[43]的启发,我们设计了一种新的交互式和通用的体医学图像分割方法,称为SegVol。我们在图1a中说明了该模型。
SegVol支持三种类型的交互式分割提示:“box”提示,b∈R6表示两个对角线顶点的坐标;' point '提示符,包含一组(P)个点P∈RP ×3;和“文本”提示符,如“肝脏”或“颈椎C2”,它被标记为张量t。SegVol由四个模块组成,即图像编码器FIE(?,θIE),文本编码器FTE(?,θTE),提示编码器FPE(?,θPE)和掩码解码器FMD(?,θMD)。我们将在下面介绍每个模块。
图像编码器。我们使用ViT (Vision Transformer)[44]作为图像编码器,当在大规模数据集上进行预训练时,它比卷积模型[45]具有显著的优势。我们首先在全部收集到的96k ct上使用MAE算法[46]对ViT进行预训练,然后用150k标记分割掩码对6k ct进行进一步的监督训练。图像编码器记为FIE(?,θIE),以体积图像x∈RC×D×H×W作为输入。首先,将x分割为一组补丁,记为xpatch∈rnx (C×PD×PH×PW),其中N = D×H×W PD×PH×PW。PD、PH、PW为patch的大小。然后将这些补丁输入到网络中,该网络输出一个嵌入zimage = FIE(xpatch, θIE), zimage∈RN×F。F表示特征维度,本文默认设置为768。
文本提示编码器。传统分割模型的一个主要限制是模型学习的数据集特定的标签编码为整数,不能推广到新的数据集或任务,限制了它在现实世界中的应用。我们通过利用文本提示实现跨数据集的通用分割。我们使用CLIP模型[47]中的文本编码器对输入文本提示进行编码,因为CLIP[47]已经被训练成在网络规模的图像-文本对上对齐图像和文本。我们将文本提示编码器表示为FTE(?,θTE)。给定一个单词或短语作为提示符,我们使用模板s = '[文本提示符]的计算机断层扫描'[48]来完成它。
然后将s标记为t。文本编码器接受t作为输入并输出文本嵌入ztext = FTE(t, θTE),其中ztext∈RF。由于CT数据集中的文本数据量很少,我们在训练过程中冻结了现成的文本编码器
空间提示编码器。根据SAM[43],我们对点提示符p和框提示符b使用位置编码[49],得到点嵌入zpoint∈RF和框嵌入zbox∈RF。我们将三种提示符的嵌入连接为zprompt = FPE(p, b, s, θPE) = [zpoint, zbox, ztext]。
掩码译码器。在获得图像嵌入zimage、提示嵌入zprompt和文本嵌入ztext后,我们将它们输入到掩码解码器中,并预测掩码p = FMD(zimage, zprompt, ztext, θMD)。我们在两个方向上使用自注意和交叉注意[50]来混合图像嵌入和提示嵌入,然后使用转置卷积和插值操作来生成掩码。由于文本嵌入是通用分割的关键,并且文本和体积区域之间的相关性也很难学习,因此我们通过在联合提示符嵌入zprompt旁边引入并行文本输入ztext来增强文本信息。我们进一步计算了转置卷积输出的放大嵌入与掩码解码器中的文本嵌入之间的相似矩阵。在插值之前,将相似矩阵与掩码预测进行逐元相乘,然后模型输出掩码。
Training procedure
提示的一代。SegVol可以接受多种提示类型,包括单个点提示,框提示和文本提示,以及它们的组合。为了充分利用分割训练数据,我们为每个数据生成各种提示。然后,利用提示对和掩码对计算训练损失。SegVol支持“点”提示,“框”提示和“文本”提示。
损失函数。我们将二元交叉熵(BCE)损失和Dice损失结合起来作为损失函数L(θ;D)训练参数为θ的模型,其中θ = [θ ie, θ pe, θ md], D为训练数据集。损失函数为:
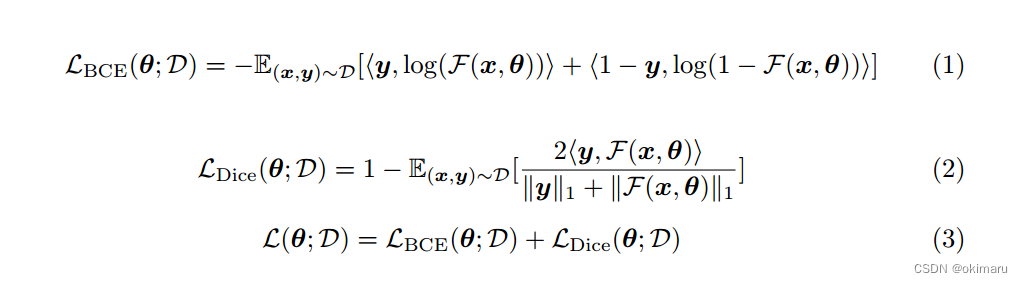
Zoom-out-zoom-in机制。
????????多视点的训练。为了适应不同大小的体积数据并实现放大-放大推理,我们构造了两类训练数据。一种是调整大尺寸CT的尺寸以适应模型的输入尺寸,获得放大视图的训练数据。另一种方法是根据模型的输入尺寸将原始大尺寸CT裁剪成立方体。这样,我们就得到了放大视图的训练数据。该过程如图1c所示。
????????Zoom-out-zoom-in推理。图1d说明了我们的放大放大推理。我们首先缩小并实现全局推理。给定一个大体积的图像,它被调整大小,然后输入到SegVol模型中。在根据用户提示获得全局预测分割掩码后,定位感兴趣区域(ROI)并进行放大,即从原始尺寸的图像中裁剪该区域。我们在裁剪区域上应用滑动窗口,实现更精确的局部推理。我们针对局部推理调整了输入提示,因为当放大时,用户输入的原始点框提示可能不适用于局部推理区域。具体来说,我们忽略局部区域外的正点或负点。与第4.3节中的训练框提示生成类似,我们将局部区域的全局预测掩码作为伪掩码来生成局部框提示。最后用局部分割掩码填充全局分割掩码的ROI区域。放大放大机构同时实现了高效和精确的推理。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java解决第一个错误的版本
- 年近五十,还能做技术,感恩所有人
- 【Linux】tree命令使用
- maven 配置http私服Since Maven 3.8.1 http repositories are blocked. 报错处理
- 基于ssm家具销售库存管理信息系统的设计与实现论文
- 大路灯和台灯哪个更适合学生?公认好用大路灯推荐
- Nginx到底是怎么转发的
- IDEA配置文件乱码
- 为什么要选择服务器虚拟化?服务器虚拟化有哪些好处?
- 1118. 分成互质组(DFS之搜索顺序)