Stable Diffusion 系列教程 - 6 Dreambooth及训练
Stable-Diffusion、Imagen等文生图大模型已经具备了强大的生成能力,假设我们的Prompt为?[Cyberpunk Style],SD或许能很快画出赛博朋克风格的一幅画。但你作为一个不知名的人,不能奢求SD在训练的时候把你自己想要的风格也加进去吧?这时就需要我们能自己个性化调整一下原始的基础大模型。我们日常所用的底模的参数量是巨大的,自己训练是完全不可能的(训练整个Stable-Diffusion-1.4大概要15万GPU小时)。Dreambooth是谷歌的一种微调模型的方案。LORA是Dreambooth的一个简化版。通常来说Dreambooth对于一些比较抽象的或者泛指的概念来说性能是比LORA好很多的,对数据集的宽容度更高(比如天空背景,妆容等),LORA更适合于一个确定的事物。Dreambooth的训练和LORA基本上是一致的,唯一的不同就是Dreambooth不需要预处理。

DreamBooth方法是对整个扩散模型进行的微调。经过DreamBooth微调后的大模型能够同时对我们自己想要的风格和它过去已有的风格进行认知。为什么叫微调?比如你要教小朋友乘法,你不可能为了让他学会,就打印几千几万道所有的题目让他做。也就是说我们希望大模型能够在很小的代价下(几张图像)学习。请注意,这对于DreamBooth来说是不会产生过拟合的,因为大的扩散模型会在不丢失原有的参数以及不对小样本过拟合的情况下,将新的信息整合进入其输出域中。
训练
DB训练画风有100张左右的数据集就能出相当不错的效果,超过300张的话意义就不是很大了,除非是你想在训练画风的同时训练大量角色或服饰等等。虽说DB训练对数据集比较宽容,再加上由于自带分桶训练,也不需要对数据集进行裁剪,但还是需要进行一些筛选来确保数据集本身有较高质量。在挑选数据集图片时,如果可以的话,尽量选择一手图片而非截图,截图多多少少会存在失真,这些失真也会被当成特征被学进去,进而反应在产出的图片上。
训练脚本:秋叶大佬的训练器(WebUI的更新会导致插件版的训练频繁出现问题,秋叶大佬的训练器本质上运行的是Kohya_ss GUI脚本,秋叶大佬将其进行了汉化,并做了很多的防呆机制)

数据集的准备参考《Stable Diffusion 系列教程 - 3》
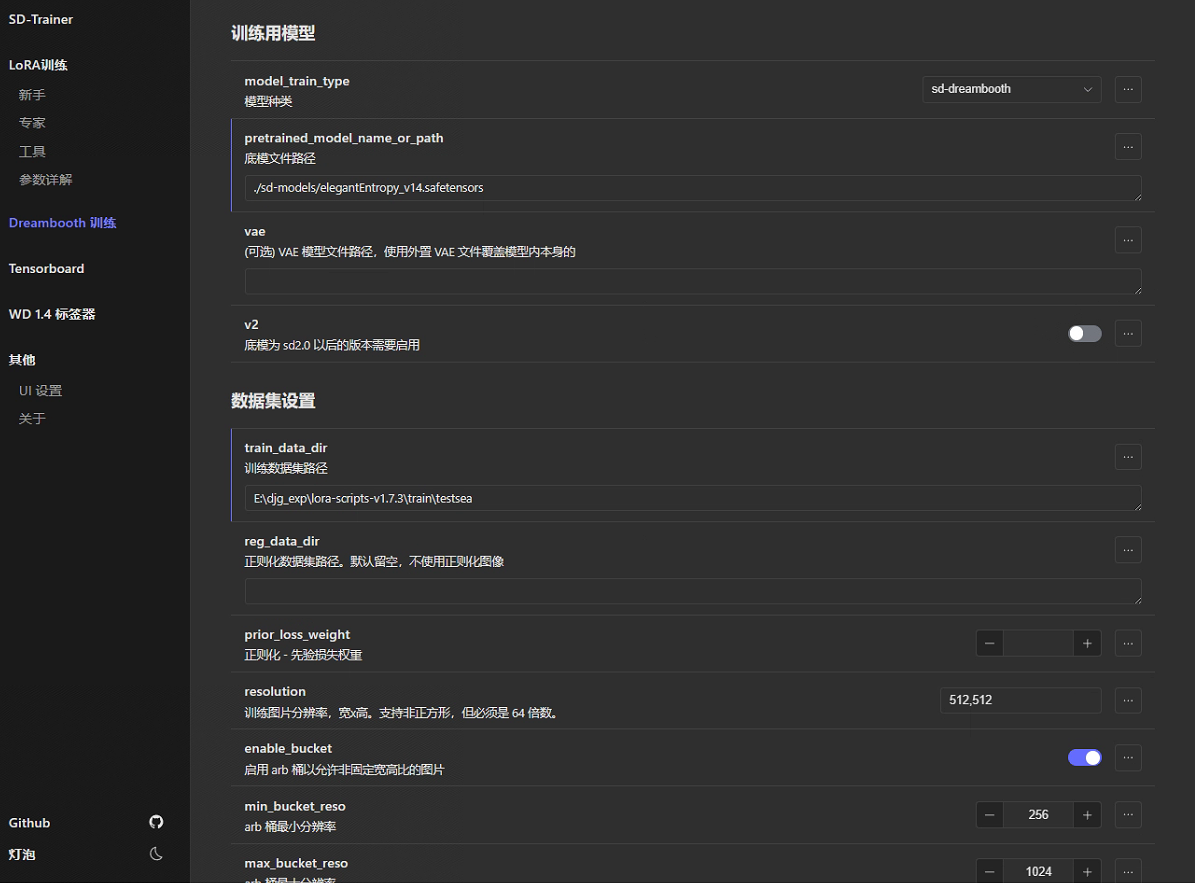
模型种类选择:sd-dreambooth
底模路径:选择自己喜欢的底模
VAE:也是根据自己的选择
训练集路径:参考《Stable Diffusion 系列教程 - 3》,需要在填写的路径下面再建立一个子文件夹,命名格式为重复次数_文件名。这里的重复次数乘以下面的最大训练轮数相当于插件版的epochs。
reg_data_dir正则化数据集路径:用不到,留空。
reg_data_dir正则化先验损失权重:用不到,留空。
resolution分辨率:不用管,只要保证下面的enable_bucket分桶训练使能就行,dreambooth的训练不会固定分辨率。所谓的分桶即训练时脚本会根据不同的长宽比例的图像数据自动分组训练。
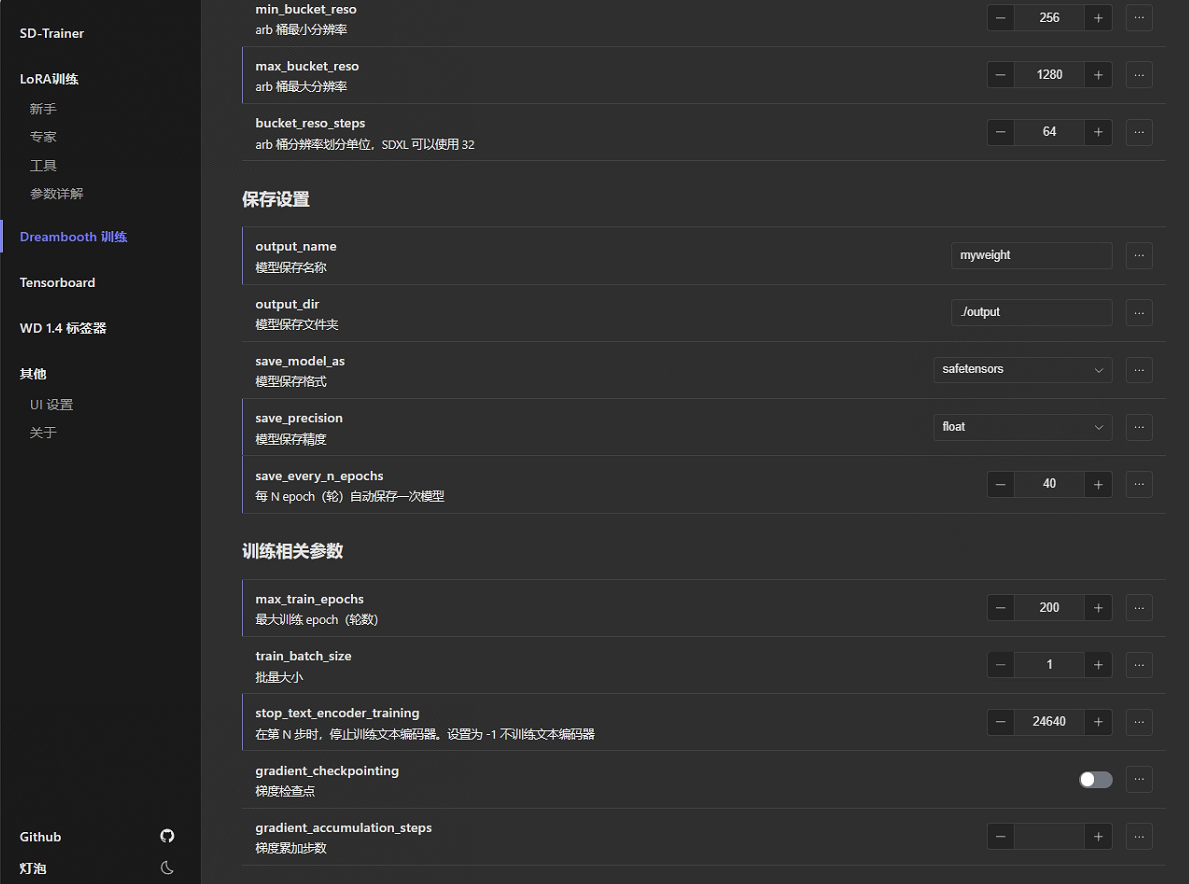
min_bucket_reso,max_bucket_reso,bucket_reso_steps:max_bucket_reso可以设为1280,其他的可以默认,也可以根据个人喜好。如果你的显存低于12g,那就建议不要使用DB来训练了,或者去租个在线训练。如果你的显存只有12g,那么训练时就老老实实选择768以下的分辨率吧。?
保存设置:保存精度FP16和BF16是半精度保存(2G左右),float是全精度保存(4G左右)。我喜欢选择float。其他可根据自己喜好设置。
训练相关参数:最大epoch一般设置为200,对应的保存频率为40。批次大小设1(DB训练本身很慢,动不动十几个小时,从这里抠速度意义不大,设大了反而容易波动)。stop_next_encoder_training:控制AI对我们对数据集中打的标的认识程度,低了AI会对打的标不敏感,高了容易过拟合。这个值的计算公式:敏感程度×图像数量×max_train_epoch,比如308张图,40%的敏感度,则stop_next_encoder_training=308×0.4×200=24640。最后两项梯度检查不管,空着就行。
随后的这些除了红框基本保持默认:
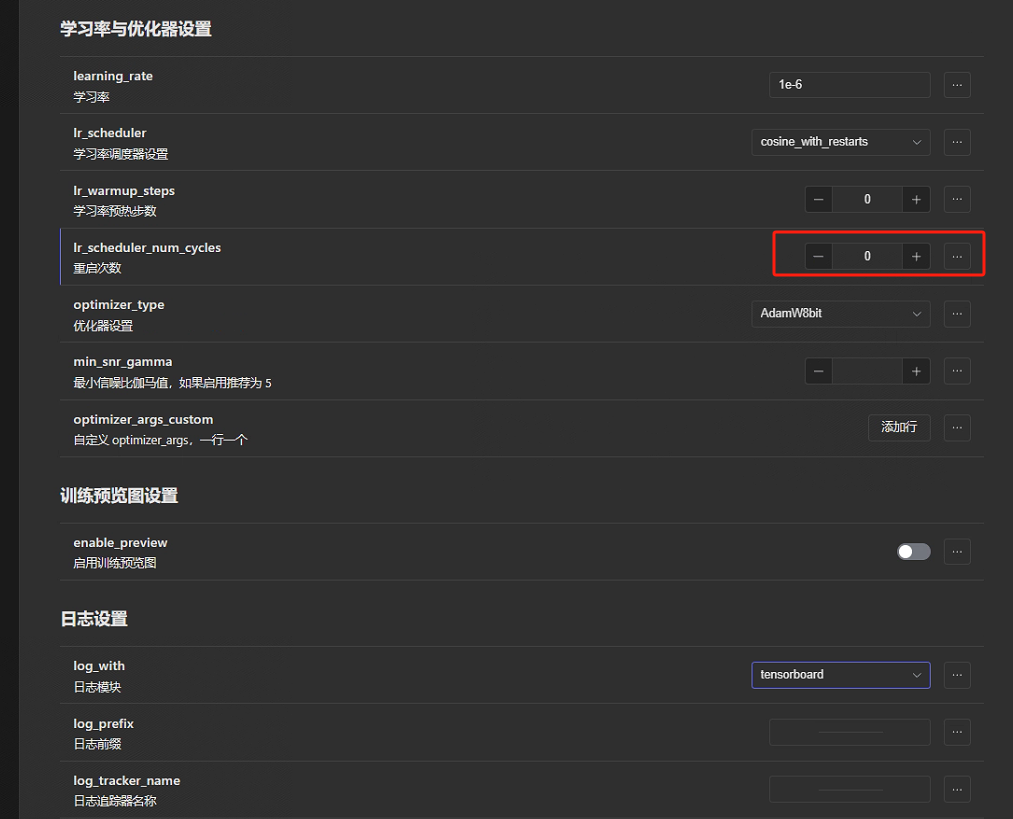
此外,还有一项keep_tokens:打标后有一大堆tag,tag越靠前ai对其的学习权重越高。打乱tag机制有助于更好的进行训练。但有些tag我们不希望AI降低对它的学习权重,那这里就可以通过这个参数来保证前几个参数不会被打乱。
?对于噪声设置:噪声会影响原始画风的还原度,留空不填。
高级选项:种子是玄学,默认就行。Clip skip根据自己喜好。
速度优化选项:mixed_precision选择fp16即可。bf16不够稳定。其他参数默认即可。
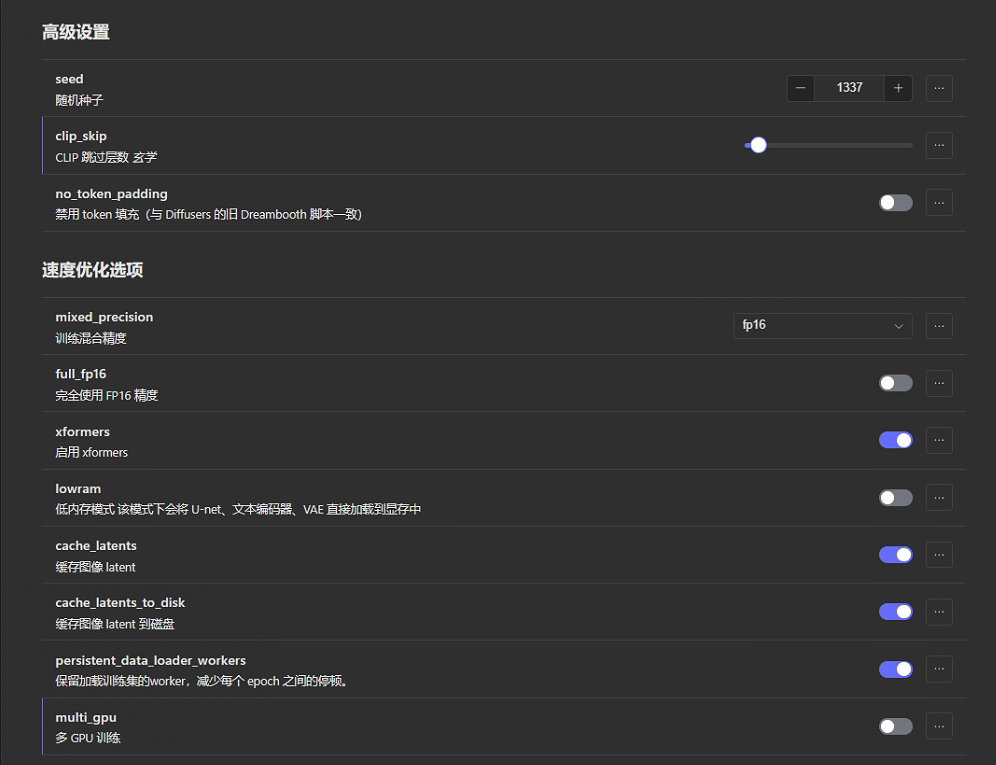
点击训练,就可以跑起来啦:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【JavaWeb】Session & JSP(学习笔记)
- 完成实验十的ko-ngxugan
- Java IO流(六)-字符流缓冲流
- Oracle中decode函数详解
- 服务器运维小技巧(一)——如何进行远程协助
- 搞懂SkyWalking(40张图)
- ChatGPT4助力Python数据分析与可视化、人工智能建模及论文高效撰写
- ArkUI 页面路由
- 扁平化嵌套列表迭代器
- SpringBoot 基础概念:SpringApplication#getSpringFactoriesInstances