Redis(五)
1、布隆过滤
1.1、简介
????????由一个初值都为零的bit数组和多个哈希函数构成,可以用来快速判断集合中是否存在某个元素,减少占用内存,不保存数据信息,只是在内存中做出一个标记。
????????它实际上是一个很长的二进制数组(00000000)+一系列随机hash算法映射函数,主要用于判断一个元素是否在集合中。通常我们会遇到很多要判断一个元素是否在某个集合中的业务场景,一般想到的是将集合中所有元素保存起来,然后通过比较确定。
????????使用布隆过滤的话一个元素如果判断结果:存在时,元素不一定存在,但是判断结果为不存在时,则一定不存在。布隆过滤器可以添加元素,但是不能删除元素,由于涉及hashcode判断依据,删掉元素会导致误判率增加。
????????布隆过滤器(Bloom Filter) 是一种专门用来解决去重问题的高级数据结构。实质就是一个大型*位数组*和几个不同的无偏hash函数(无偏表示分布均匀)。由一个初值都为零的bit数组和多个个哈希函数构成,用来快速判断某个数据是否存在。但是跟 HyperLogLog 一样,它也一样有那么一点点不精确,也存在一定的误判概率

1.2、使用特点
????????添加key时使用多个hash函数对key进行hash运算得到一个整数索引值,对位数组长度进行取模运算得到一个位置,每个hash函数都会得到一个不同的位置,将这几个位置都置1就完成了add操作。
????????当有变量被加入集合时,通过N个映射函数将这个变量映射成位图中的N个点,把它们置为 1(假定有两个变量都通过 3 个映射函数)。
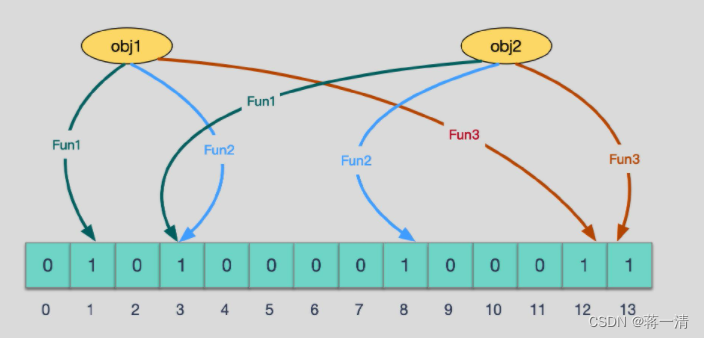
????????查询key时只要有其中一位是零就表示这个key不存在,但如果都是1,则不一定存在对应的key。如果这些点,有任何一个为零则被查询变量一定不在,如果都是 1,则被查询变量很可能存在,为什么说是可能存在,而不是一定存在呢?那是因为映射函数本身就是散列函数,散列函数是会有碰撞的。(见上图3号坑两个对象都1)
????????此外还有可能出现的误差是因为,哈希函数的概念是:将任意大小的输入数据转换成特定大小的输出数据的函数,转换后的数据称为哈希值或哈希编码,也叫散列值。

????????如果两个散列值是不相同的(根据同一函数)那么这两个散列值的原始输入也是不相同的。
这个特性是散列函数具有确定性的结果,具有这种性质的散列函数称为单向散列函数。
????????散列函数的输入和输出不是唯一对应关系的,如果两个散列值相同,两个输入值很可能是相同的,但也可能不同,这种情况称为“散列碰撞(collision)”。用 hash表存储大数据量时,空间效率还是很低,当只有一个 hash 函数时,还很容易发生哈希碰撞。
1.3、使用步骤
1.3.1、初始化bitmap
????????布隆过滤器 本质上 是由长度为 m 的位向量或位列表(仅包含 0 或 1 位值的列表)组成,最初所有的值均设置为 0。

1.3.2、添加占坑位
当我们向布隆过滤器中添加数据时,为了尽量地址不冲突,会使用多个 hash 函数对 key 进行运算,算得一个下标索引值,然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就完成了 add 操作。
例如,我们添加一个字符串wmyskxz,对字符串进行多次hash(key) → 取模运行→ 得到坑位

1.3.3、判断是否存在
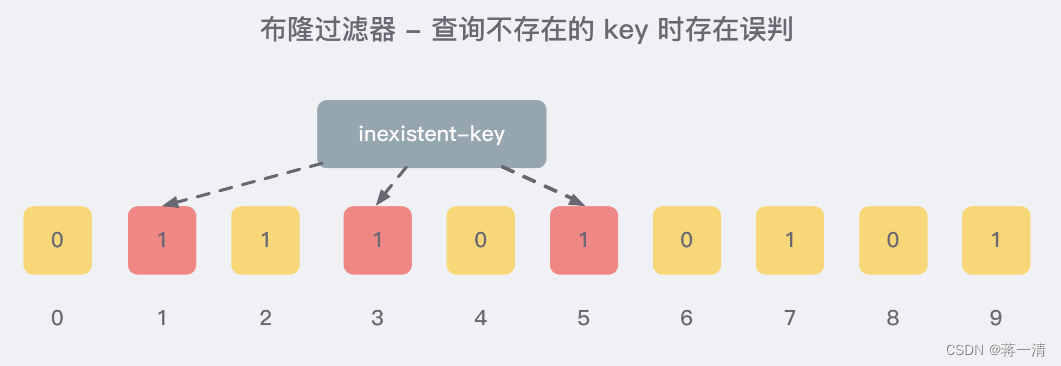
向布隆过滤器查询某个key是否存在时,先把这个 key 通过相同的多个 hash 函数进行运算,查看对应的位置是否都为 1,只要有一个位为零,那么说明布隆过滤器中这个 key 不存在;如果这几个位置全都是 1,那么说明极有可能存在;因为这些位置的 1 可能是因为其他的 key 存在导致的,也就是前面说过的hash冲突。。。。。
就比如我们在 add 了字符串wmyskxz数据之后,很明显下面1/3/5 这几个位置的 1 是因为第一次添加的 wmyskxz 而导致的;此时我们查询一个没添加过的不存在的字符串inexistent-key,它有可能计算后坑位也是1/3/5 ,这就是误判了

2、缓存问题
2.1、缓存穿透
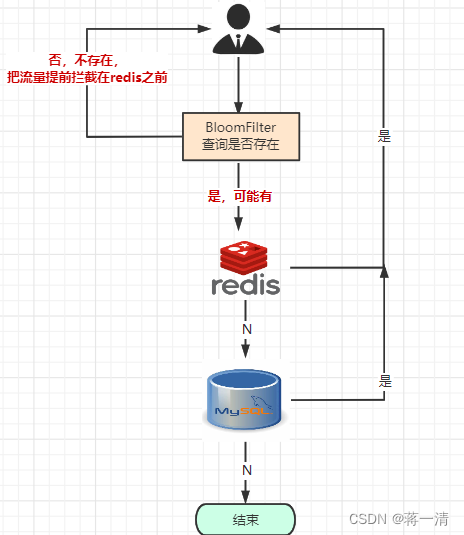
????????首先说一下缓存穿透,简单的讲就是请求的数据首先在Redis中查询没有找到,然后请求数据库去访问数据,但是在数据库中也没有找到,但是用户知道自己查询的数据不存在,所以此后的所有的请求的压力都会到数据库中, 但是事实上请求也没有预期的结果。
2.1.1、解决方法
2.1.1.1、 业务层校验
????????在缓存中没有命中的情况下,可以在业务层进行校验,如果校验不通过,直接返回错误信息,避免继续访问数据库。
????????还有一种做法就是,没有命中Redis和数据库这时候后就可以使用null来应对这种情况,大概的思路就是当第一次访问数据库时如果没有数据的话,然后将null存入Redis, 这样就可以解决下一次数据命中的是Redis而不是数据库,然后判断Redis命中如果是空值的话就要返回错误信息,但是对于这种的空值的设置的话,可以设置超时时间自动清除,不建议设置的时间过长, 这样会导致数据的不一致的时间过长,如果数据库中的数据更新但是Redis中的数据还是null,导致请求的参数无法获取正确值,这种方式的优点就是简单方便操作,但是这样会额外消耗内存以及数据不一致(所以要设置过期时间短一点) 。
????????还有对于一些访问数据的格式做出校验,不要让别人直接可以猜到数据然后直接大量的请求进行访问。此外是对于用户的权限验证。没有权限就直接拦截不让他访问。
2.1.1.2、 布隆过滤器
????????布隆过滤器是一种数据结构,可以用于判断一个元素是否在一个集合中。在缓存中没有命中的情况下,可以使用布隆过滤器判断该数据是否存在,如果不存在,直接返回错误信息。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2022年全国职业院校技能大赛(高职组)“云计算”赛项赛卷①第二场次:容器云
- MT6785|MTK6785安卓核心板功能规格介绍_Helio G95核心板
- 第九部分 使用函数 (五)
- 二、C#基础语法( 变量与数据类型)
- 操作无法完成,因为文件已在Windows资源管理器中打开,如何解决?以及如何将哔哩哔哩下载好的视频导出到电脑中播放?— 以vivo手机为例
- 前端八股文(js篇 )
- 基于Java的校车管理系统
- matlab基础
- MyBatis——MyBatis的ORM映射和MyBatis的配置文件升级
- Python测试框架:pytest与unittest的区别