nn.LSTM个人记录
发布时间:2023年12月23日
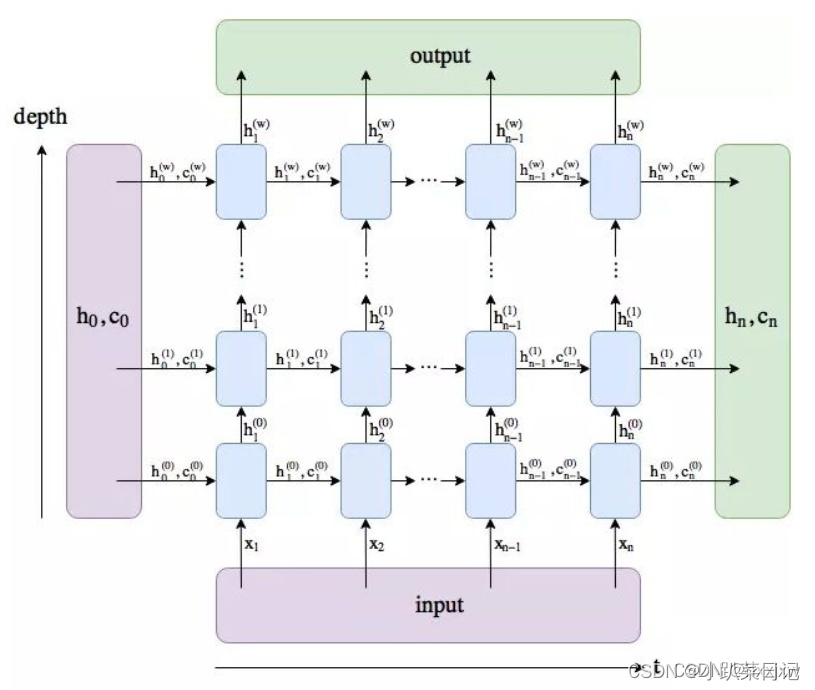
简介
 ?
?
nn.LSTM参数
torch.nn.lstm(input_size, "输入的嵌入向量维度,例如每个单词用50维向量表示,input_size就是50"
hidden_size, "隐藏层节点数量,也是输出的嵌入向量维度"
num_layers, "lstm 隐层的层数,默认为1"
bias, "隐层是否带 bias,默认为 true"
batch_first, "True 或者 False,如果是 True,则 input 为(batchsize, len, input_size),默认值为:False(len, batchsize, input_size)"
dropout, "除最后一层,每一层的输出都进行dropout,默认值0"
bidirectional "如果设置为 True, 则表示双向 LSTM,默认为 False"
)
维度
batch_first=True,输入维度(batchsize,len,input_size)
batch_first=False,输入维度(len,batchsize, input_size)
batch_first=False,输出维度(len,batchsize,hidden_size)
举例嵌入向量维度为1
?假如输入x为(batchsize,len)的序列,即嵌入向量维度为1,进行一个回归预测。
如果将嵌入向量维度维度设为1就不太合理,因为如果len非常长例如几w,那么经过几w的时间步得到的得到的h维度为(batchsize,1),序列太长丢失很多信息,再输入全连接层预测效果不好。并且lstm实际上将嵌入向量维度从input_size规约到hidden_size。
所以在这里我们将len作为input_size,嵌入向量维度1作为len(即对调了一下)
添加一个维度:
x = x.unsqueeze(0)x维度变为(1,batchsize,len),相当于设置数据的长度为1,嵌入向量维度为len,通过nn.LSTM输入到网络中。
#lstm为定义的网络
#h[-1]为最后输入到全连接层的嵌入矩阵 但是由于此问题中len为1,所以x等于h[-1]
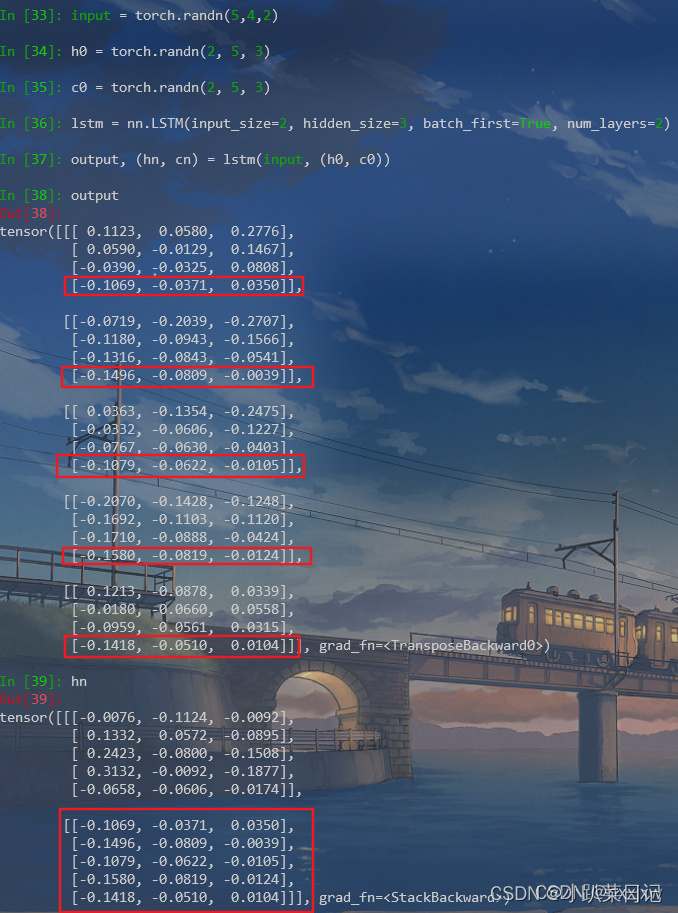
x, (h, c) = lstm(x)x维度变为(1,batchsize,hidden_size)
h为每层lstm最后一个时间步的输出(一般可以输入到后续的全连接层),维度为(num_layers,batchsize,hidden_size)
c为最后一个时间步 LSTM cell 的状态(记忆单元,一般用不到),维度为(num_layers,batchsize,hidden_size)
移除张量中所有尺寸为 1 的维度,即将第一个维度移除掉:
lstm_out = x.squeeze(0)x维度变为(batchsize,hidden_size) ,输入到全连接层(线性层,维度(hidden_size,num_class))中,最终输出维度(batchsize,num_class)
参考:
文章来源:https://blog.csdn.net/qq_55736201/article/details/135163249
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- kafka-python简单生产消费数据
- RabbitMQ(十一)队列的扩展属性(Arguments)
- 2014年第三届数学建模国际赛小美赛B题全地形伪装解题全过程文档及程序
- vue制作简易日历
- 2024Navicat最新下载安装教程
- 【Python基础】循环语句
- Jmeter 性能压测-TPS实例解析
- AI芯片、GPU、算力、大模型
- vite-admin框架搭建,ESLint + Prettier 语法检测和代码格式化
- JavaScript基础03