pyfolio工具结合backtrader分析量化策略组合,附源码+问题分析
pyfolio可以分析backtrader的策略,并生成一系列好看的图表,但是由于pyfolio直接install的稳定版有缺陷,开发版也存在诸多问题,使用的依赖版本都偏低,试用了一下之后还是更推荐quantstats。
1、安装依赖
pip install pyfolio
# 直接install是稳定版会报各式各样的错误,要用git拉开发版
pip install git+https://github.com/quantopian/pyfolio
但是git拉也可能报各种http代理等问题,可以使用如下方法解决:
-
克隆 GitHub 仓库: 打开命令行或终端,然后使用以下命令将 pyfolio 仓库克隆到本地:
bashCopy code
如果
git clone https://github.com/quantopian/pyfolio.git报错,可以用下面格式
git clone git@github.com:quantopian/pyfolio.git这将在当前目录下创建一个名为 “pyfolio” 的文件夹,并将仓库的所有代码下载到其中。
-
切换到仓库目录: 使用以下命令进入 pyfolio 文件夹:
bashCopy code
cd pyfolio -
安装: 在 pyfolio 文件夹中执行以下命令,安装开发版本的代码:
bashCopy code
pip install -e .-e选项表示以 “editable” 模式安装,这意味着你对代码的修改会立即反映在安装的库中。这对于开发和测试非常有用。
pyfolio策略源码
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
'''
@Author:Airyv
@Project:test
@File:quantstats_demo.py
@Date:2024/1/1 21:45
@desc:
'''
from datetime import datetime
import backtrader as bt # 升级到最新版
import matplotlib.pyplot as plt # 由于 Backtrader 的问题,此处要求 pip install matplotlib==3.2.2
import akshare as ak # 升级到最新版
import pandas as pd
import quantstats as qs
import pyfolio as pf
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
# 利用 AKShare 获取股票的后复权数据,这里只获取前 6 列
stock_hfq_df = ak.stock_zh_a_hist(symbol="600028", adjust="hfq").iloc[:, :6]
# 处理字段命名,以符合 Backtrader 的要求
stock_hfq_df.columns = [
'date',
'open',
'close',
'high',
'low',
'volume',
]
# 把 date 作为日期索引,以符合 Backtrader 的要求
stock_hfq_df.index = pd.to_datetime(stock_hfq_df['date'])
class MyStrategy(bt.Strategy):
"""
主策略程序
"""
params = (("maperiod", 5),) # 全局设定交易策略的参数
def __init__(self):
"""
初始化函数
"""
self.data_close = self.datas[0].close # 指定价格序列
# 初始化交易指令、买卖价格和手续费
self.order = None
self.buy_price = None
self.buy_comm = None
# 添加移动均线指标
self.sma = bt.indicators.SimpleMovingAverage(
self.datas[0], period=self.params.maperiod
)
def next(self):
"""
执行逻辑
"""
if self.order: # 检查是否有指令等待执行,
return
# 检查是否持仓
if not self.position: # 没有持仓
if self.data_close[0] > self.sma[0]: # 执行买入条件判断:收盘价格上涨突破20日均线
self.order = self.buy(size=100) # 执行买入
else:
if self.data_close[0] < self.sma[0]: # 执行卖出条件判断:收盘价格跌破20日均线
self.order = self.sell(size=100) # 执行卖出
# 更新指令状态
if self.order:
self.buy_price = self.data_close[0]
self.buy_comm = self.broker.getcommissioninfo(self.data).getcommission(self.buy_price, 100)
self.order = None # 在这里将订单设置为None,表示没有正在执行的订单
else:
self.buy_price = None
self.buy_comm = None
cerebro = bt.Cerebro() # 初始化回测系统
start_date = datetime(2010, 1, 3) # 回测开始时间
end_date = datetime(2023, 6, 16) # 回测结束时间
data = bt.feeds.PandasData(dataname=stock_hfq_df, fromdate=start_date, todate=end_date) # 加载数据
# data=bt.feeds.PandasData(dataname=df,fromdate=start_date,todate=end_date)#加银数据
cerebro.adddata(data) # 将数据传入回测系统
cerebro.addstrategy(MyStrategy) # 将交易策略加载到回测系统中
# 加入pyfolio分析者
cerebro.addanalyzer(bt.analyzers.PyFolio, _name='pyfolio')
start_cash = 1000000
cerebro.broker.setcash(start_cash) # 设置初始资本为 100000
cerebro.broker.setcommission(commission=0.002) # 设置交易手续费为 0.2%
result = cerebro.run() # 运行回测系统
port_value = cerebro.broker.getvalue() # 获取回测结束后的总资金
pnl = port_value - start_cash # 盈亏统计
print(f"初始资金: {start_cash}\n回测期间:{start_date.strftime('%Y%m%d')}:{end_date.strftime('%Y%m%d')}")
print(f"总资金: {round(port_value, 2)}")
print(f"净收益: {round(pnl, 2)}")
# cerebro.plot(style='candlestick') # 画图
cerebro.broker.getvalue()
strat = result[0]
pyfoliozer = strat.analyzers.getbyname('pyfolio')
returns, positions, transactions, gross_lev = pyfoliozer.get_pf_items()
%matplotlib inline
pf.create_full_tear_sheet(
returns,
positions=positions,
transactions=transactions,
live_start_date='2023-01-03')
# returns, positions, transactions, gross_lev = pyfoliozer.get_pf_items()
# returns
# positions
# transactions
# gross_lev
# pf.create_full_tear_sheet(returns)
# pf.create_full_tear_sheet(
# returns,
# positions=positions,
# transactions=transactions,
# live_start_date='2010-01-03',
# round_trips=True)
# pf.create_full_tear_sheet(returns,live_start_date='2010-01-03')
# cerebro.plot()
错误解决
解决后可能报错:
-
AttributeError: 'Series' object has no attribute 'iteritems'
solution:For anyone else who has the same error pls edit the plotting.py file in ur site packages folder from iteritems() to items()
意思是进入plotting.py文件(可以用everything搜索)中全局搜索iteritems(),替换为items()即可
-
AttributeError: module 'pandas' has no attribute 'Float64Index'原因是pandas版本太高了(2.0.1),安装低版本:
pip uninstall pandas
pip install pandas==1.5.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
-
File "...\pyfolio\timeseries.py", line 896, in get_max_drawdown_underwater将timeseries.py893行改为:
# valley = np.argmin(underwater) # end of the period
valley = underwater.idxmin()
-
File "\pyfolio\round_trips.py", line 133, in _groupby_consecutive grouped_price = (t.groupby(('block_dir',KeyError: ('block_dir', 'block_time')修改round_trips.py第133行
# grouped_price = (t.groupby(('block_dir',
# 'block_time'))
# .apply(vwap))
grouped_price = (t.groupby(['block_dir','block_time'])
.apply(vwap))
grouped_price.name = 'price'
grouped_rest = t.groupby(['block_dir', 'block_time']).agg({
'amount': 'sum',
'symbol': 'first',
'dt': 'first'})
-
File "...\pyfolio\round_trips.py", line 77, in agg_all_long_short stats_all = (round_trips pandas.errors.SpecificationError: nested renamer is not supported改round_trips.py第77行
stats_all = (round_trips
.assign(ones=1)
.groupby('ones')[col]
.agg(list(stats_dict.items()))
.T
.rename(columns={1.0: 'All trades'}))
stats_long_short = (round_trips
.groupby('long')[col]
.agg(list(stats_dict.items()))
.T
.rename(columns={False: 'Short trades',
True: 'Long trades'}))
-
File "...\pyfolio\round_trips.py", line 393, in gen_round_trip_stats round_trips.groupby('symbol')['returns'].agg(RETURN_STATS).T pandas.errors.SpecificationError: nested renamer is not supported393行修改:
stats['symbols'] = \
round_trips.groupby('symbol')['returns'].agg(list(RETURN_STATS.items())).T
-
ValueError: The number of FixedLocator locations (16), usually from a call to set_ticks, does not match the number of labels (3).注释掉tears.py文件的871行
画图运行
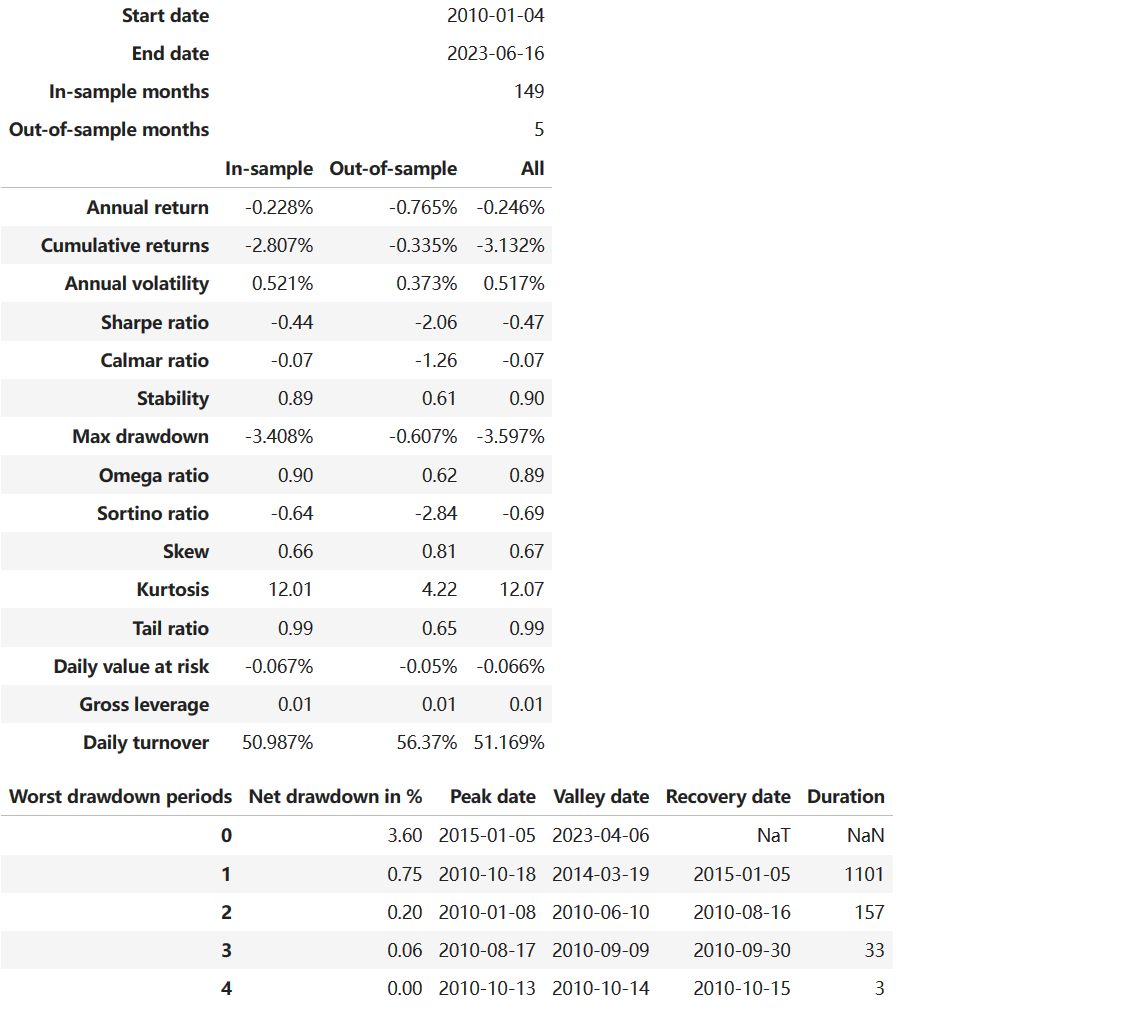
在Jupter notebook中运行,不建议直接console中运行,结果如图:


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- MCAL配置-PORT(EB23.0)
- WebAssembly002 emcc Emscripten js端传入数组给c++
- FastAdmin后台安装出现2054错误的解决办法
- 若依微服务中的上传文件的前后端实现
- pytest自动化测试执行环境切换的两种解决方案
- 【第33例】IPD体系进阶:市场细分
- 代码随想录算法训练营第六天|242 有效的字母异位词、349 两个数组的交集、202 快乐数、1 两数之和
- CentOs7.8安装原生Jenkins2.38教程
- SCA在 得物 DevSecOps 平台上应用
- 为什么使用双token实现无感刷新用户认证?