Spark原理——Shuffle 过程
Shuffle 过程
-
Shuffle过程的组件结构
从整体视角上来看, Shuffle 发生在两个 Stage 之间, 一个 Stage 把数据计算好, 整理好, 等待另外一个 Stage 来拉取
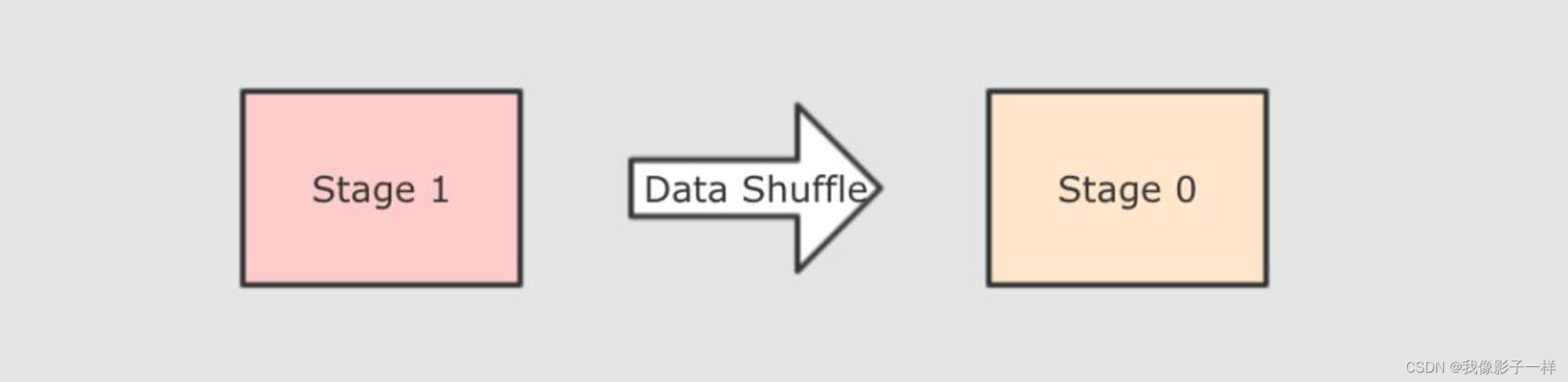
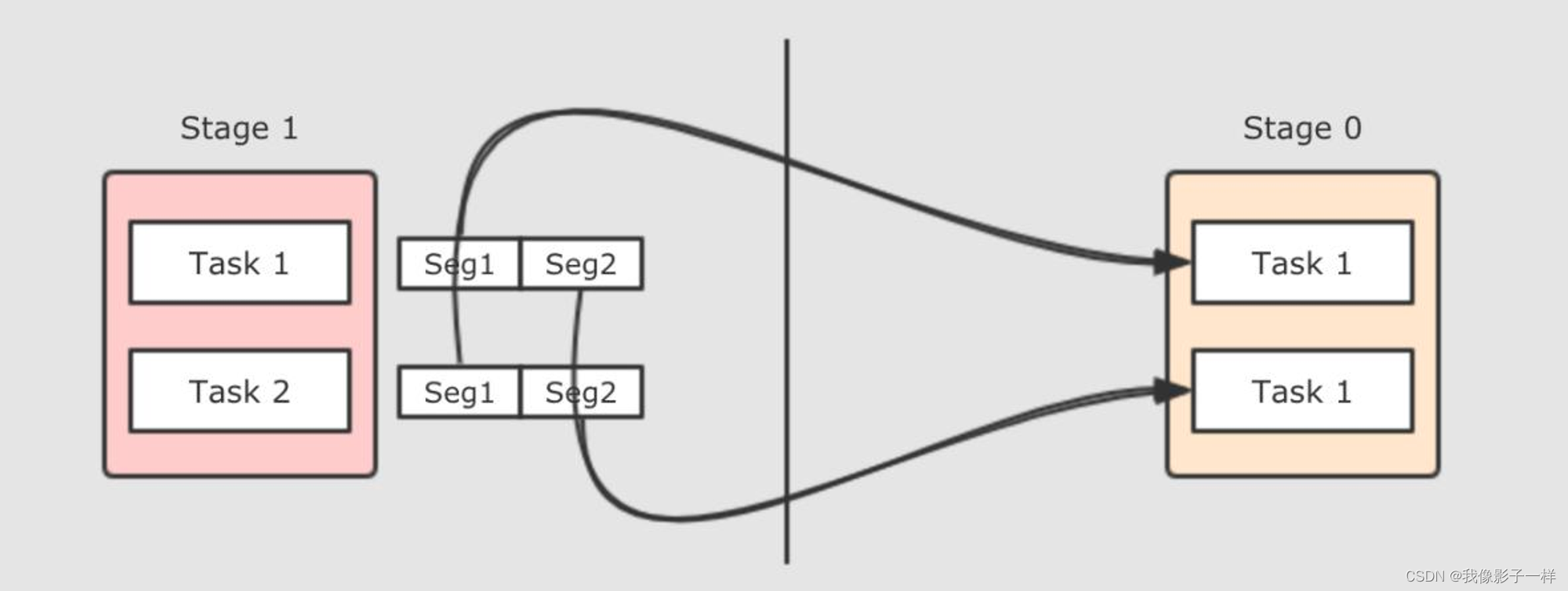
放大视角, 会发现, 其实 Shuffle 发生在 Task 之间, 一个 Task 把数据整理好, 等待 Reducer 端的 Task 来拉取
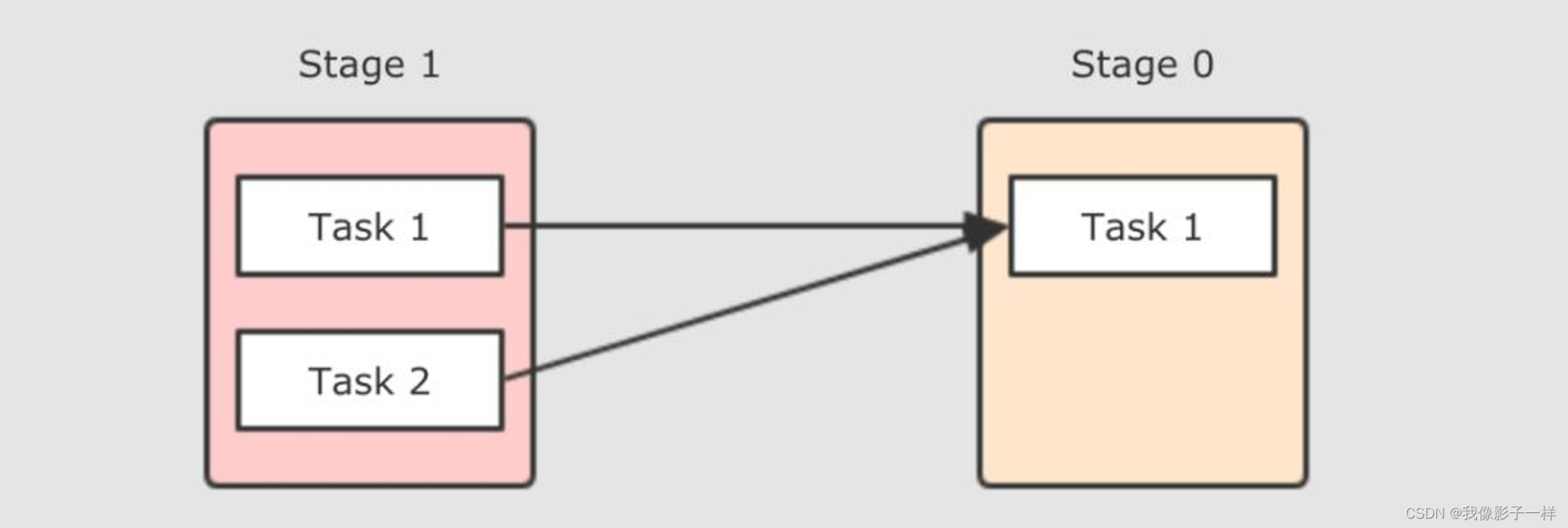
如果更细化一下, Task 之间如何进行数据拷贝的呢? 其实就是一方 Task 把文件生成好, 然后另一方 Task 来拉取
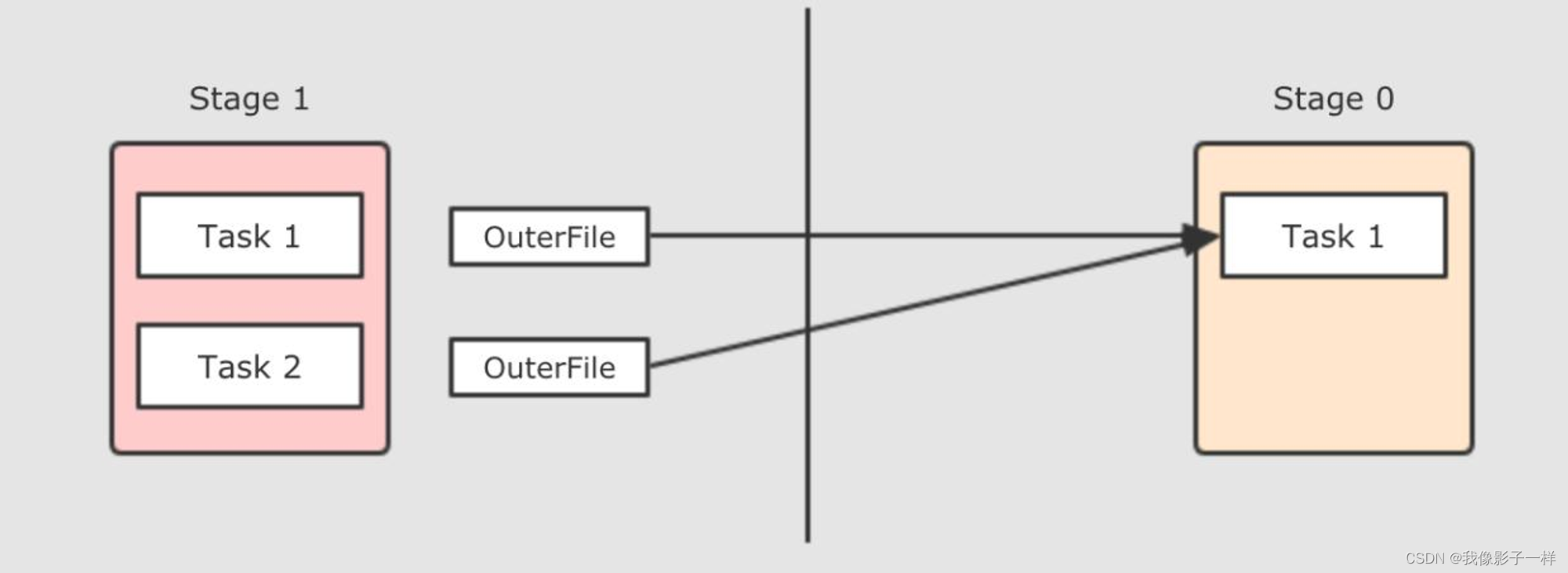
现在是一个 Reducer 的情况, 如果有多个 Reducer 呢? 如果有多个 Reducer 的话, 就可以在每个 Mapper 为所有的 Reducer 生成各一个文件, 这种叫做 Hash base shuffle, 这种 Shuffle 的方式问题大家也知道, 就是生成中间文件过多, 而且生成文件的话需要缓冲区, 占用内存过大
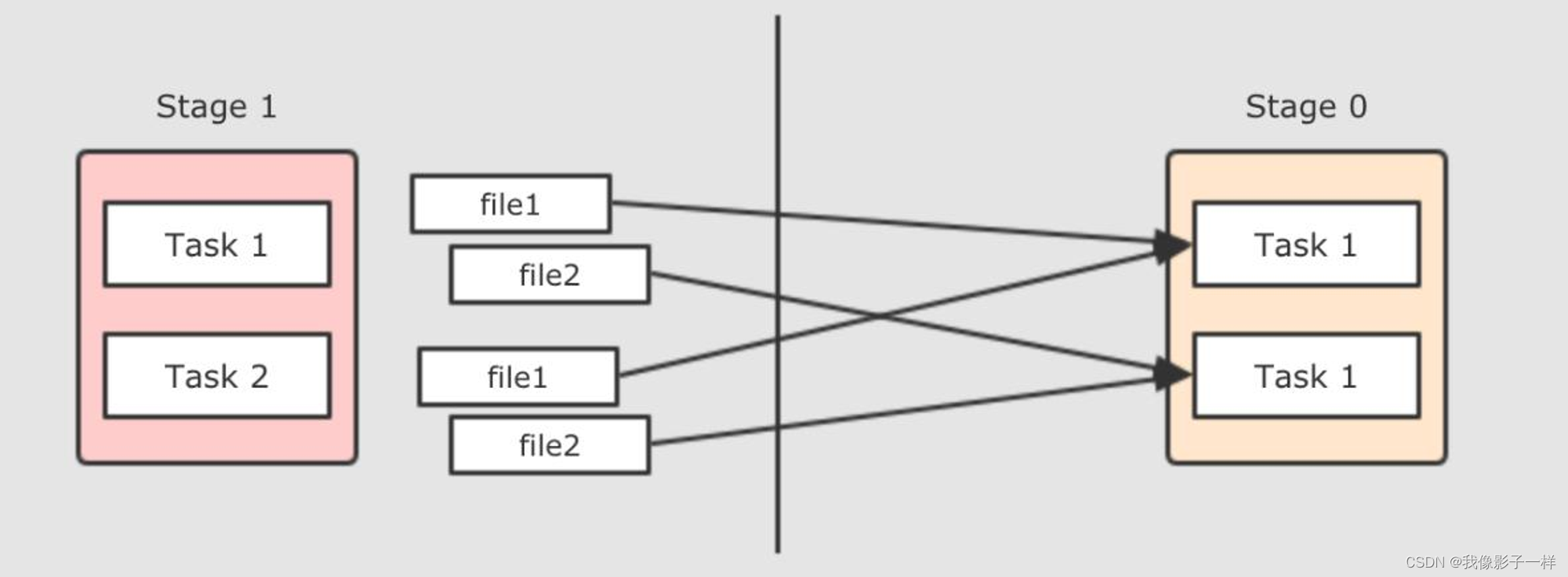
那么可以把这些文件合并起来, 生成一个文件返回, 这种 Shuffle 方式叫做 Sort base shuffle, 每个 Reducer 去文件的不同位置拿取数据
如果再细化一下, 把参与这件事的组件也放置进去, 就会是如下这样
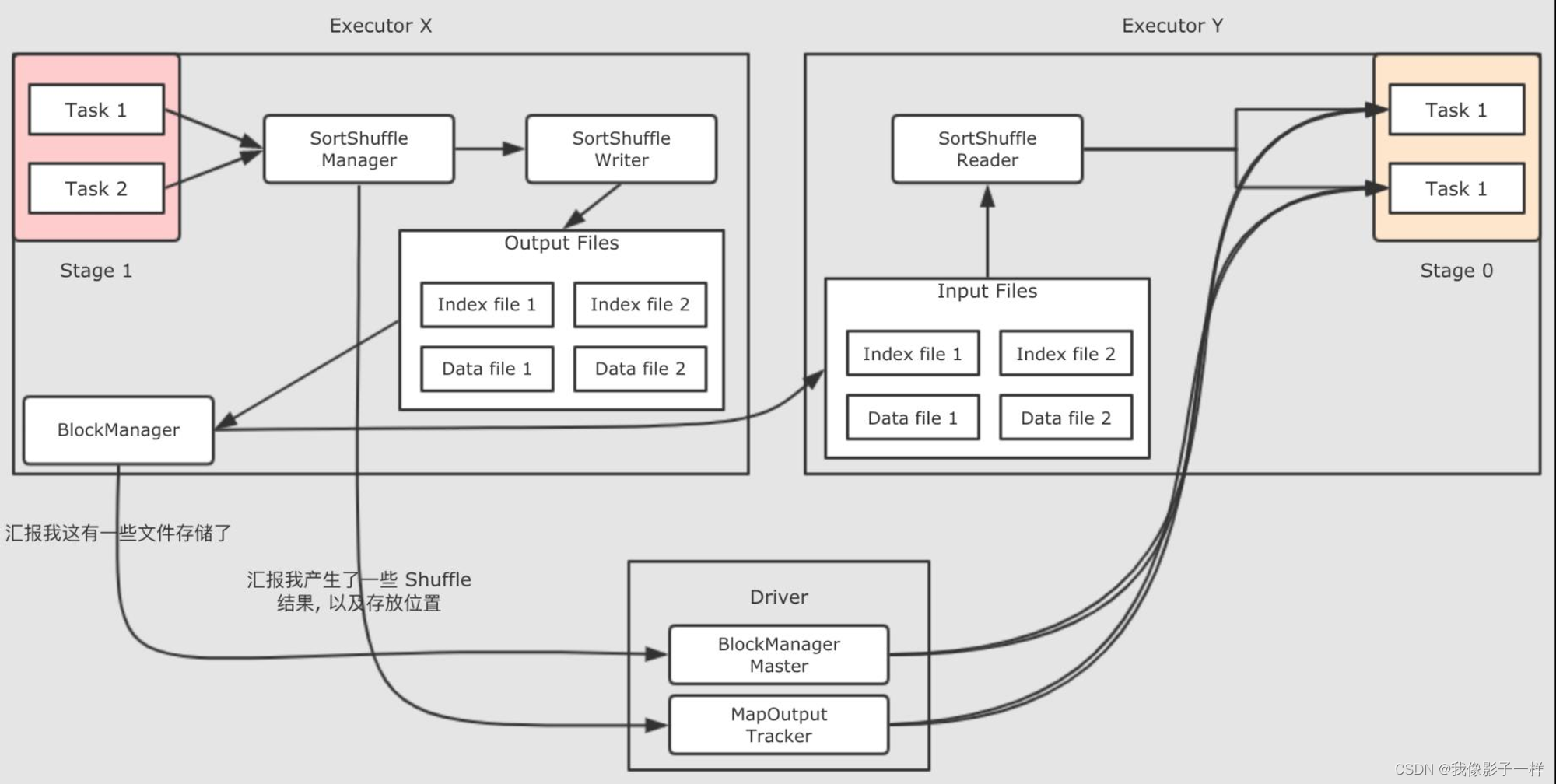
-
有哪些 ShuffleWriter ?
大致上有三个 ShufflWriter, Spark 会按照一定的规则去使用这三种不同的 Writer
-
BypassMergeSortShuffleWriter
这种 Shuffle Writer 也依然有 Hash base shuffle 的问题, 它会在每一个 Mapper 端对所有的 Reducer 生成一个文件, 然后再合并这个文件生成一个统一的输出文件, 这个过程中依然是有很多文件产生的, 所以只适合在小量数据的场景下使用
Spark 有考虑去掉这种 Writer, 但是因为结构中有一些依赖, 所以一直没去掉
当 Reducer 个数小于 spark.shuffle.sort.bypassMergeThreshold, 并且没有 Mapper 端聚合的时候启用这种方式
-
SortShuffleWriter
这种 ShuffleWriter 写文件的方式非常像 MapReduce 了, 后面详说
当其它两种 Shuffle 不符合开启条件时, 这种 Shuffle 方式是默认的
-
UnsafeShuffleWriter
这种 ShuffWriter 会将数据序列化, 然后放入缓冲区进行排序, 排序结束后 Spill 到磁盘, 最终合并 Spill 文件为一个大文件, 同时在进行内存存储的时候使用了 Java 得 Unsafe API, 也就是使用堆外内存, 是钨丝计划的一部分
也不是很常用, 只有在满足如下三个条件时候才会启用
- 序列化器序列化后的数据, 必须支持排序
- 没有 Mapper 端的聚合
- Reducer 的个数不能超过支持的上限 (2 ^ 24)
SortShuffleWriter的执行过程
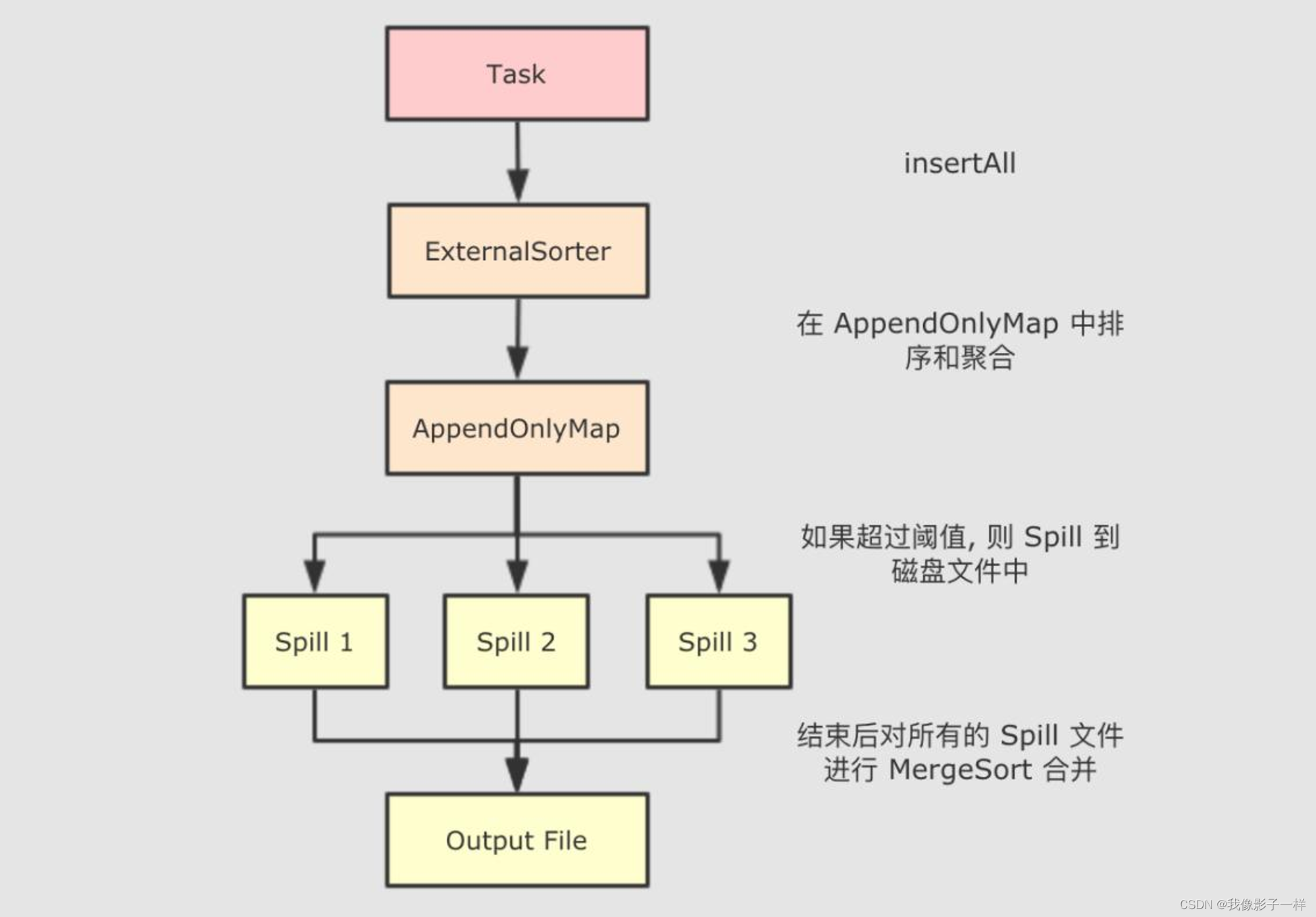
整个 SortShuffleWriter 如上述所说, 大致有如下几步
- 首先 SortShuffleWriter 在 write 方法中回去写文件, 这个方法中创建了 ExternalSorter
- write 中将数据 insertAll 到 ExternalSorter 中
- 在 ExternalSorter 中排序如果要聚合, 放入 AppendOnlyMap 中, 如果不聚合, 放入 PartitionedPairBuffer 中在数据结构中进行排序, 排序过程中如果内存数据大于阈值则溢写到磁盘
- 使用 ExternalSorter 的 writePartitionedFile 写入输入文件将所有的溢写文件通过类似 MergeSort 的算法合并将数据写入最终的目标文件中
-
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 贯穿设计模式-享元模式思考
- 文本批量处理大师:高效便捷的管理利器,释放您的生产力!
- 【软件测试】如何用python连接Linux服务器
- python中,设置环境变量的值:os.putenv()方法 和os.environ字典
- 基于springboot的宠物健康咨询系统【数据库设计、论文、毕设源码、开题报告】
- 探索鸿蒙:了解华为鸿蒙操作系统的基础课程
- 3D Guassians Splatting相关解读
- 【OS】操作系统总复习笔记
- 【ARM 嵌入式 编译系列 3.4 -- 查看所依赖库文件的路径 详细介绍】
- 基于ssm运动会管理系统的设计与实现 【附源码】