JAVA-集合
JAVA-集合
整体结构:


Collection
collection (以实现子类ArrayList为例:)
- 存放类型为 Object,
- 根据实现类的不同;其存放的元素可重复可 不重复; 有序或无序

迭代器
Iterator对象即为迭代器: 遍历Collection集合的元素
凡是实现 Iterator接口,都会有方法:iterator()
Iterator接口未实现Collection接口!!!
使用:
-
Collection arrayList = new ArrayList(); arrayList.add("a"); Iterator iterator = arrayList.iterator(); // 得到迭代器 while (iterator.hasNext()) { // 如果下一个有值 Object next = iterator.next(); // 获取下一个元素 System.out.println(next); }
增强for循环 : 简化版的迭代器
- 底层仍是迭代器
List
- List 子接口:该集合中元素有序,可重复
- 支持根据索引(序号)查询 ,索引是从 0 开始的
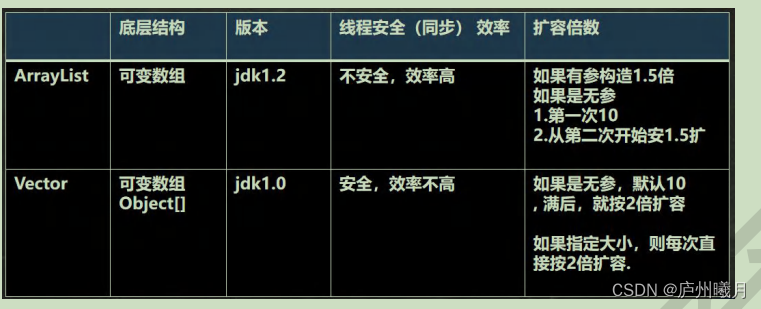
ArrayList
- 本质上为一Object 类型的数组
elementData,来存储数据 - 可加入null元素
- add 时 没有
synchronized,线程不安全 效率较高; 多线程不推荐用
transient Object[] elementData; // 不会被序列化
transient:被修饰的属性不会被序列化
-
ArrayList 有两个构造方法:
-
无参: 初始容量=0, 第一次添加扩容到10,若满了则扩容至1.5倍。
- 以无参创建的list 实际为空数组(设置容量为10),直到向数组add元素时,才
new Object[10]
- 以无参创建的list 实际为空数组(设置容量为10),直到向数组add元素时,才
-
有参: 指定初始大小,之后扩容为 原来的1.5倍
-
new ArrayList( int num); -
该有参构造方法并不是将ArrayList()初始化为指定长度(容量),而是指定了其内部的Object数组的长度,指定了容量。当我们调用size()时,返回的是其实际长度,而非容量大小。
-
对于ArrayList,想初始化设定长度,还是一个for循环插入吧。初始化不可靠。
-
-
Arrays.copyOf
Integer[] newArr = Arrays.copyOf(arr, x);
-
从 arr 数组中,拷贝x个元素到 newArr 数组中
-
如果拷贝的长度 > arr.length 就在新数组的后面 增加 null
-
如果拷贝长度 < 0 就抛出异常 NegativeArraySizeException
Vector
Vector底层亦是一个对象数组:
protected Object[] elementData;
- 线程同步(线程安全) 该类的操作方法带有:
synchronized\ - 适用于线程同步的场景;效率不高
LinkedList
-
linkedList 底层:双向链表
-
first:首节点 ; last:尾结点
-
Node节点对象, prev属性指向前一节点、next属性指向后一节点
-
删除、添加效率高; 链表嘛
(5条消息) LinkedList常用方法_一个浪子-CSDN博客_linkedlist方法
LinkedList 与ArrayList
- LinkedList 善于增删
- ArrayList 善于改查
Set
- 无序,不可重复,可存一个null元素,无索引样,
就算插入多个重复元素,也只存一个
- Set 接口也是 Collection 的子接口,因此,常用方法和 Collection 接口一样
没有 get(),不能取出元素
HashSet set = new HashSet();
set.add("lucy");//添加成功
set.add("lucy");//加入不了
set.add(new Dog("tom"));//OK
set.add(new Dog("tom"));//Ok
set.add(new String("hsp"));//ok
set.add(new String("hsp"));//加入不了
Dog不是同一对象
String重写了 equals方法,值一样;故加不了
HashSet
数组+链表是散列表
实现Set接口,其底层为 HashMap;
public HashSet() {
map = new HashMap<>();
}
HashMap底层为 数组+链表+红黑树
- 当数组存不下时,在每个数组后面拓展链表
- 链表满了;将链表变成红黑树;便于查找
为什么HashSet 底层 HashMap 的 value为何是PRESENT而不写成null?
(12条消息) HashSet底层HashMap的value为何是PRESENT?_missbearC的博客-CSDN博客_hashset present
先看一下HashMap 的put方法: HashMap 的put()方法
HashSet add() 底层
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
- 如果
map.put(e, PRESENT)时,value 写的是null,则不论put成功或失败都会返回null,那么add()方法每次返回都是true,也就不能够确认add成功还是失败了。
HashSet的remove方法
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
(12条消息) HashMap的remove()方法详解_瓦坎达forever的博客-CSDN博客_hashmap.remove
HashMap的remove方法: 会返回该key对应的value值
- 如果HashMap底层的value保存的都是null的话,那么remove成功或者是失败都会返回null ,同样无法分辨。
HashSet添加元素
(29条消息) HashMap底层实现原理_fengxi_tan的博客-CSDN博客_hashmap底层实现原理
add()
HashSet中元素是否有序,取决于hash值得到的 索引
-
添加元素: 先得到
hash值(= key.hashCode()) ^ (h >>> 16)不只是hashCode() 方法),hash值的目的:table表的索引值
-
找到存储数据表(数组)table
该所与位置是否已有元素
- 没有:直接存入
- 已有:判断条件:
(判断是否为同一对象(hash值+对象地址)|| 该类的equals)- 调用
equals方法(可自定义,注意不同类是否重写:没重写就是比较地址)比较- 相同:放弃添加 (HashMap为覆盖value)
- 不同:一直for循环比较;直到都不同添加到末尾(链表)
- 循环期间存在不同的也放弃添加
- 调用
-
若一链表元素个数>= 8 且 table的长度>=64,将进行 树化(红黑树)
- 若 某一链表长度>=8, 但 table表的长度<64,优先扩容表数组
扩容数组机制
第一次添加,table数组==初始化==扩容至16,临界值为12
临界值:当前容量 * 0.75(加载因子);即 当数组已存个数size>此值后就开始扩容
扩容: 扩成原来的二倍 (<< 1)
扩容有两种情况
- 一种是链表到8、table表的长度<64
- 另一种是数组存储到了临界值
扩容后新元素存放位置
- java 在扩容的时候会新建一个新的 Node<K,V>[] 来存放扩容之后的值,并将旧有的Node数组置空;
至于旧有值移动到新的节点的时候存放于哪个节点,Java 是根据 (e.hash & oldCap) == 0 来判断的:
(e.hash & oldCap)就是:当前元素的hash 与 旧容器容量做 &(与)运算而
hash():static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
-
①若
e.hash & oldCap = 0的,在新表的位置=旧表中位置 ,记为低位区链表lo开头-low; -
② 若
e.hash & oldCap != 0的,位置为旧表位置+旧表容量,记为高位区链表hi开头high.新的位置=老的位置+老的数组长度。
原文链接:https://blog.csdn.net/qq_37155154/article/details/115161022
(12条消息) jdk8之HashMap resize方法详解(深入讲解为什么1.8中扩容后的元素新位置为原位置+原数组长度)_诺浅的博客-CSDN博客_hashmap扩容后的位置
LinkedHashSet
底层: 数组+双向链表
有序!无重复元素
在Node的基础上 另加俩属性:next、prev
add过程:
-
先求该元素的 hash值,求索引,定位到table表的位置
-
将元素加入
- 若此处无元素:加入
- 与已有的元素比较(与hashSet一致):
- 相同:不添加
- 反之,加在其后面
- 记录之前最新添加的元素(tail,双向链表末尾),使得:
tail.next = newElement; newElement.pre = tail; tail = newElement; // 最新添加的元素为 双向链表的末尾


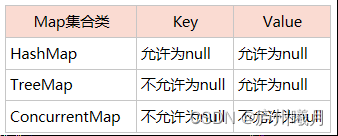
Map
整体结构:

常用API:

Map 结构:
- key-value 键值对,两者一 一对应
- key不可重复–Set;value可以重复–Collection
-
当有相同的 k , 就替换原先的Value
-

Node<k,v>即为HashMap的元素类型。
为了便于遍历map的key-value,
-
创建集合
EntrySet;每个元素的 定义类型是Entry,使用类型是Node- (实质上就是
Node因为Node实现了Entry接口): static class Node<K,V> implements Map.Entry<K,V>
- (实质上就是
-
Map map = new HashMap(); Set set = map.entrySet(); for (Object o : set) { Map.Entry entry = (Map.Entry) o; // set 中元素为Entry类型,Entry存放的就是<k,v>, 即: EntrySet< Entry<k,v> > // 向下转型 entry.getKey(); entry.getValue(); }
Map遍历:
HashMap 的 7 种遍历方式与性能分析!「修正篇」 (qq.com)
由Key遍历
System.out.println("第一种《根据key集合》");
Set keySet = map.keySet(); // 获取到 key集合
for (Object o :keySet){
Object o1 = map.get(o);
System.out.println(o+"--"+o1);
}
System.out.println("第一种1迭代器《》");
Iterator iterator = keySet.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println(next+"---"+map.get(next));
}
获取value集合
Map map = new HashMap();
Collection values = map.values();
for (Object o : values){
System.out.println(o);
}
EntrySet获取 k-v
Map map = new HashMap();
Set set = map.entrySet();
for (Object o : set) {
Map.Entry entry = (Map.Entry) o;
System.out.println( entry.getKey()+"--"+ entry.getValue());
}
HashMap
与HashSet源码一样,无序(因为是Hash表存储)
HashMap:线程不安全:因为方法没有 synchronized关键字
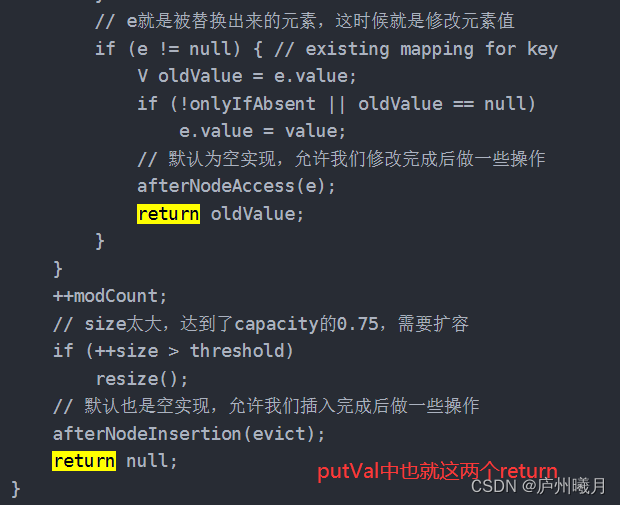
put()方法
(29条消息) HashMap底层实现原理_fengxi_tan的博客-CSDN博客_hashmap底层实现原理
-
如果不存在则执行插入,返回 null 。
-
(第一次插入该元素,则返回null(表示之前没加入过。))
-
-
如果插入的 key 对应的 value 已经存在,则执行 value 替换操作,返回旧的 value 值,
-
但如果put失败也是返回
null:
为什么HashMap的长度一定是2的次幂?
(8条消息) HashMap初始容量为什么是2的n次幂及扩容为什么是2倍的形式_猿人小郑的博客-CSDN博客_hashmap扩容为什么是2倍
向集合中添加元素时,会使用(n - 1) & hash的计算方法来得出该元素在集合中的位置。
- 当HashMap的容量是2的n次幂时,(n-1)的2进制也就是
1111111***111这样形式的,这样与添加元素的hash值进行位运算时,能够充分的散列,使得添加的元素均匀分布在HashMap的每个位置上,以减少hash值碰撞,避免形成链表的结构,使得查询效率降低!
不能让参与&运算的二进制数有0的存在 ,不然0对应的那一位参与&运算永远是0,也就意味着数组的某一个位置会&不出来,hash值不能被充分散列。如果长度是2的幂,参与&运算的二进制数的每一位都会是1,就会避免这种情况。
Java集合常见面试题总结(下)–hashmap-的长度为什么是-2-的幂次方 | JavaGuide
- 因为 hash值的取值范围是:-2147483648 到 2147483647 大概40亿的映射空间,(目的是这样的hash比较均匀,不易出现碰撞),而数组放不下这么大的下标,需要对其取余。
- 而 取余操作
hash%length若除数为2的幂次的话,等价于length-1 & hash;大大提高了运算效率。
另一种解释:
这是因为当table.length为2的幂次时,(table.length-1) 的二进制形式的特点是除最高位外全部是1,配合这种索引计算方式可以实现key在table中的均匀分布 ,减少hash冲突——出现hash冲突时,结点就需要以链表或红黑树的形式链接到table[i],这样无论是插入还是查找都需要额外的时间。
原文链接:(31条消息) 大厂之路一由浅入深、并行基础、源码分析一 “J.U.C”之collections框架:ConcurrentHashMap扩容迁移等方法的源码分析_slow is fast.的博客-CSDN博客
rehash:
背景-- 当前hash表容量装不下了,需要新建更大的hash表,将数据从老的hash表 迁移到 新的hash表
疫苗:Java HashMap的死循环 | 酷 壳 - CoolShell
HashMap的ReHash图解 - 简书 (jianshu.com)
Transfer():
void transfer(Entry[] newTable)
{
Entry[] src = table;
int newCapacity = newTable.length;
//下面这段代码的意思是:
// 从OldTable里摘一个元素出来,然后放到NewTable中
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);// 求出放到新表的位置
e.next = newTable[i];
// newTable[i];一开始是null
newTable[i] = e;
e = next;
} while (e != null);
}
}
}

困惑的点:
- 先是for循环遍历旧表的数组,之后开始
do-while遍历每个数组元素后面的链表。- e这个链表节点一直是在旧表中。
- newTable[i] 是 要放到新表的数组元素(从这里开始放链表节点)
- 旧数据放到新的hash表的位置:
key % 新表大小 - 链表插入的方式是头插法
newTable[]是在每个线程里new出来的,属于线程私有的;所以,第一次,里面并没有值(或者是随机的值);
(29条消息) 记java7 HashMap的transfer()方法中的疑惑_山鬼谣me的博客-CSDN博客_hashmap transfer

HashTable
HashTable和HashMap的区别详解 - 割肉机 - 博客园 (cnblogs.com)
Hashtable继承Dictionary类,
-
存放的元素是键值对,存入对象
Entry中 -
键和值 都不能为空;否则抛 空指针异常
-
线程安全的(
synchronized)而HashMap线程不安全 -
初始化:数组大小:11;
- 加载因子:0.75
临界值:11 * 0.75 = 8(8.25)
-
扩容机制
- 当前个数 >= 数组长度时扩容;
- 按照;
2X+1扩容
int newCapacity = (oldCapacity << 1) + 1;
Hashtable采用取模的方式来计算数组下标,同时数组的长度尽量为素数或者奇数,这样的目的是为了减少Hash碰撞,计算出来的数组下标更加分散,让元素均匀的分布在数组各个位置。
- Hashtable计算hash值,直接用key的hashCode(),
Hashtable在求hash值对应的位置索引时,用取模运算,- 而HashMap重新计算了key的hash值,而
HashMap在求位置索引时,则用与运算,

Properties
Map接口的实现类。
继承HashTable,所以 key&value 都不能为空

TreeSet
底层:TreeMap;二叉树
本质上靠的是二叉树的中序遍历。(左中右)
public TreeSet() {
this(new TreeMap<>());
}
-
无参构造:调用集合元素的compareTo(Object obj),排序按照添加元素类所实现的方法比较
- Integer和String对象都可以进行默认的TreeSet排序
- 默认以ASCll码排序元素,升序【按照key的字典顺序来排序(升序) 】
- 如果对应的类没有实现Comparable接口,则会引发ClassCastException异常
- 自己定义的类必须实现Comparable接口,并且覆写相应的compareTo()函数,才可以正常使用。
public boolean add(E e) { return m.put(e, PRESENT)==null; } - Integer和String对象都可以进行默认的TreeSet排序
-
重写匿名内部类
new Comparator<Object>()的compare()方法-
则比较时,按照重写的方法进行比较排序
-
if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value);- 结果<0;将新元素放其左边
- 结果>0;将新元素放其右边
- 结果=0;则重新设置其
value值,key值不变,认为元素相同- key不变 value会重新set ,因为是treeset单列的 所以value值都一样替换啥啊 值一直都是
PRESENT这是键
- key不变 value会重新set ,因为是treeset单列的 所以value值都一样替换啥啊 值一直都是
-
comparable 和 Comparator 的区别
面试官:元素排序Comparable和Comparator有什么区别? - 腾讯云开发者社区-腾讯云 (tencent.com)
-
字面含义不同
- Comparable 翻译为中文是“比较”的意思,而 Comparator 是“比较器”的意思。Comparable 是以 -able 结尾的,表示它自身具备着某种能力,
- 而 Comparator 是以 -or 结尾,表示自身是比较的参与者,这是从字面含义先来理解二者的不同。
-
应用场景:
- comparable 需要 原有的类实现
Comparable的compareTo方法,否则无法使用Collection.sort()排序Comparator不需更改原有的类,需创建个比较器或匿名构造器使用Collections.sort()排序;Collection可以用各自的sort方法排序 (list.sort)
- comparable 需要 原有的类实现
TreeMap
又称有序表,把key按照顺序排序,
线程不安全
重写匿名内部类new Comparator<Object>() 的compare()方法“
- 结果=0;则重新设置其
value值,key值不变- key不变 value会重新set ,TreeMap
- TreeMap通过红黑树实现Map接口的类,key不可以为null,会报NullPointerException异常,value可以为null。
TreeMap常用方法:
get(Object key) // 查
put(K key, V value) // 增
remove(Object key) // 删
firstKey() // 返回map中最小的key
lastKey() // 返回map中最大的key
ceilingKey(K key) // 返回大于等于key的最小key
floorKey(K key) // 返回小于等于key的最大key
higherKey() // 返回严格大于key的最小key
lowerKey() // 返回严格小于key的最大key
containsKey(Object Key)
containsValue(Object Value)
clear()
clone()
entrySet()
firstEntry()
lastEntry()
floorEntry(K key)
ceilingEntry(K key)
higherEntry()
lowerEntry()
size()
总结
单列:(Collection)
-
允许重复
- List
- 增删多: LinkedList (底层:双向链表)
- 查改多:ArrayList (底层:动态数组Object类型)
- List
-
不允许重复:
-
Set
-
无序:HashSet 【底层:HashMap,即:数组+链表+红黑树】
-
有序:TreeSet 【底层:TreeMap】
-
有序: LinkedHashSet【底层:LinkedHashMap】
-
-
双列:键值对 Map
- HashMap 【底层:数组+链表+红黑树】线程不安全
- HashTable 【底层与HashMap一致】,线程安全,继承自Dictionary类
- LinkedHashMap 键值对插入、输出顺序一致
- 读取文件:properties
- TreeMap
Collection工具类
操作Set、List、Map等的集合的工具类,包含对集合元素进行排序,查询,修改等操作
- 排序(都是静态方法)
reverse(List)翻转List中的顺序shuffle(List)对List中的元素进行随机排序
理解Comparator接口中的返回值 1,-1,0
-
sort(List,comparator)对List中的元素进行自然排序(升序)-
按照comparator重写的规则进行排序
-
保持这个顺序就返回-1,表示不想调整顺序
-
交换顺序就返回1,表示我想调整顺序
-
什么都不做就返回0;所以 升序的话 如果1<2,返回-1,保持顺序[1,2],如果3>2,返回-1,交换顺序[2,3]
-
-
swap(List,int,int)将List的i处元素与j处进行交换

测试题

- 试分析输出结果:
该 Cat类已重写了 HashCode和equals方法
HashSet set1 = new HashSet();//ok
Cat p1 = new Cat(1001,"AA");
Cat p2 = new Cat(1002,"BB");
set1.add(p1); set1.add(p2);
p1.Cname="CC";
set1.remove(p1);
System.out.println(set1);
set1.add(new Cat(1001,"CC"));
System.out.println(set1);
set1.add(new Cat(1001,"AA"));
System.out.println(set1);
当类重写了HashCode方法和equals方法,可知:
- 该类的hash值 由属性决定。当属性改变,其hash值也会改变
@Override
public int hashCode() {
return Objects.hash(Cname, id);
}
remove()方法根据hash删除。此时 p1对象hash是由 1001,“AA” 计算,而Cname变成“CC”,p1的hash值不变。此时remove根据1001,"CC"找 p1 ,肯定找不到,故没有删除p1.- remove底层是按照修改name之后的对象获取hash进行搜索删除的,然而得到的索引和实际存放的索引不一样了
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
? 此时的元素:
[Cat{id=1002, Cname='BB'}, Cat{id=1001, Cname='CC'}]
-
set1.add(new Cat(1001,"CC"));- 新对象p3 hash = 1001,“CC”. 另开辟了表空间
- 绕不出去的问题在于p1.name=CC之后其实此时占用的还是AA的哈希位置,所以添加进去的CC经过哈希之后不可能在原来AA的位置
[Cat{id=1002, Cname='BB'}, Cat{id=1001, Cname='CC'}, Cat{id=1001, Cname='CC'}] -
set1.add(new Cat(1001,"AA"));- ? 新对象p4 hash = 1001,“AA”. 与 p1 的hash一致。 但
equals两者不同,故在p1 后另加链表 p4
- ? 新对象p4 hash = 1001,“AA”. 与 p1 的hash一致。 但
[Cat{id=1002, Cname='BB'}, Cat{id=1001, Cname='CC'}, Cat{id=1001, Cname='CC'}, Cat{id=1001, Cname='AA'}]
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 百度 RT-DETR 算法原理解析 | 超越YOLO的目标检测新高度?
- 《PCI Express体系结构导读》随记 —— 第I篇 第2章 PCI总线的桥与配置(1)
- 骨传导耳机的优缺点是什么?一文读懂骨传导耳机的利与弊!
- 一问掌握SpringBoot常见注解,后无压力。
- 高压电缆光纤测温在线监测系统,实现温度动态监测|深圳鼎信
- Linux系统中查看路由表的命令(ip route)
- 【vtkWidgetRepresentation】第十六期 vtkContourRepresentation(一)
- C+关于用户界面设计
- gitlab项目迁移到gerrit--百分百不会出错的解决终极报错的最后版本
- zip加密