pulsar的架构与特性记录
一、什么是云原生
????????云原生的概念是2013年Matt Stine提出的,到目前为止,云原生的概念发生了多次变更,目前最新对云原生定义为: Devps+持续交付+微服务+容器
????????而符合云原生架构的应用程序是: 采用开源堆栈(K8S+Docker)进行容器化,基于微服务架构提高灵活性和可维护性,借助敏捷方法、DevOps支持持续迭代和运维自动化,利用云平台设施实现弹性伸缩、动态调度、优化资源利用率。

二、Apache Pulsar基本介绍
????????Apache Pulsar 是一个云原生企业级的发布订阅(pub-sub) 消息系统,最初由Yahoo开发,并于2016年底开源,现在是Apache软件基金会顶级开源项目。Pulsar在Yahoo的生产环境运行了三年多,助力Yahoo的主要应用,如Yahoo MailYahoo Finance、Yahoo Sports、Flickr、Gemini广告平台和Yahoo分布式键值存储系统Sherpa。
?Apache Pulsar的功能与特性:
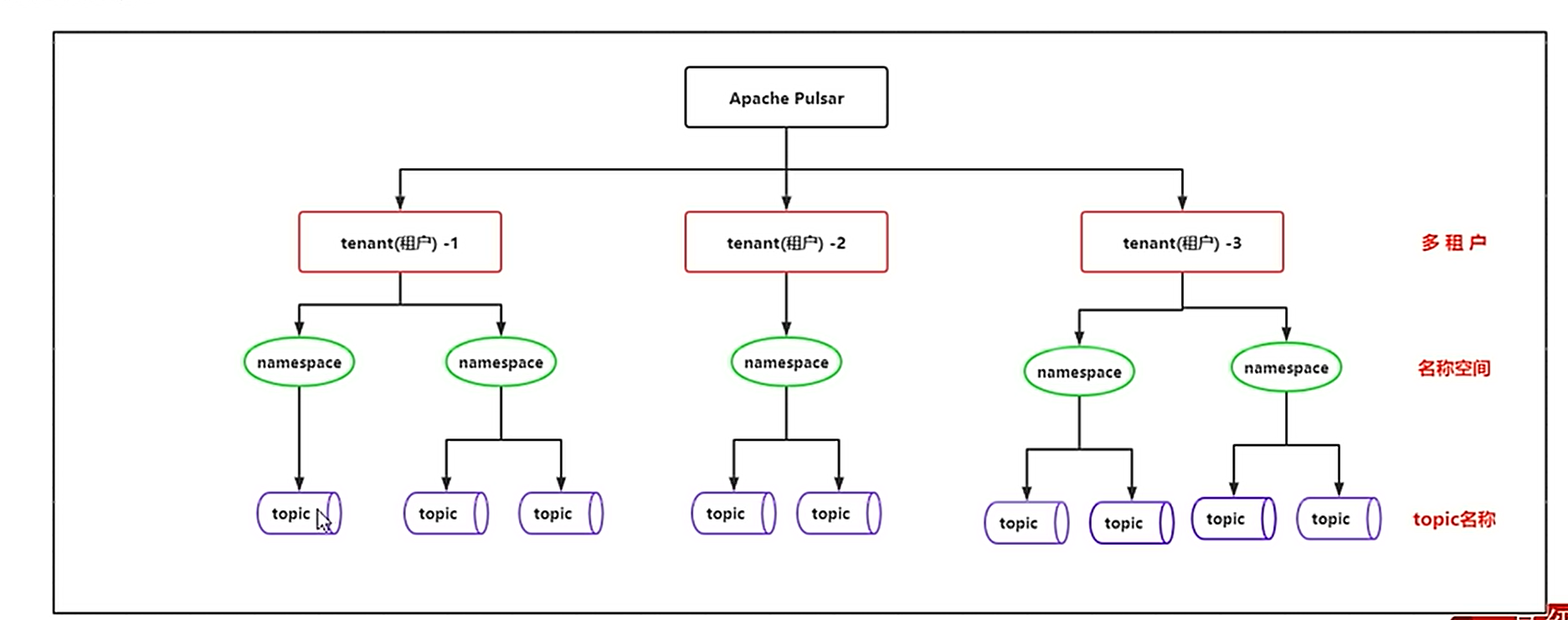
2.1 多租户模式
??????租户和命名空间(namespace)是 Pulsar 支持多租户的两个核心概念
? ? ??在租户级别:Pulsar 为特定的租户预留合适的存储空间、应用授权与认证机制
? ? ??在命名空间级别:Pulsar 有一系列的配置策略(policy),包括存储配额、流控、消息过期策略和命名空间之 间的隔离策略。
 2.2 灵活的消息系统
2.2 灵活的消息系统
????????Pulsar 做了队列模型和流模型的统一,在 Topic 级别只需保存一份数据,同一份数据可多次消费。以流式队列等方式计算不同的订阅模型大大提升了灵活度。
????????同时pulsar通过事务采用Exactly-0nce(精准一次)在进行消息传输过程中,可以确保数据不丢不重
 2.3 云原生架构
2.3 云原生架构
????????Pulsar 使用计算与存储分离的云原生架构,数据从 Broker 搬离,存在共享存储内部。上层是无状态 Broker,复制消息分发和服务;下层是持久化的存储层 Bookie 集群。Pulsar 存储是分片的,这种构架可以避免扩容时受限制,实现数据的独立扩展和快速恢复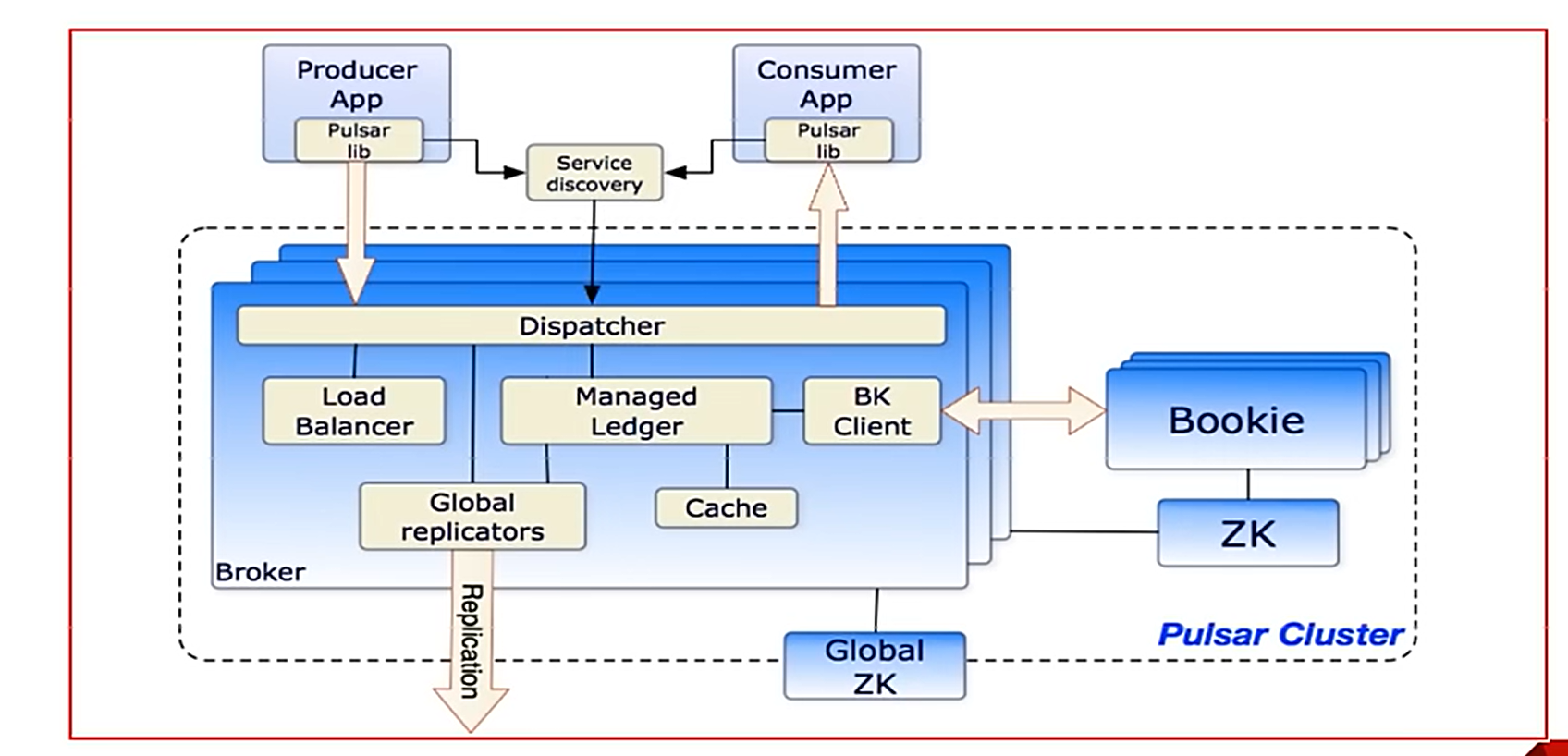
2.4 Segmented Streams(分片流)
????????Pulsar 将无界的数据看作是分片的流,分片分散存储在分层存储 (tiered storage)、BookKeeper 集群和Broker 节点上,而对外提供一个统一的、无界数据的视图。其次,不需要用户显式迁移数据,减少存储成本并保持近似无限的存储。
2.5 支持跨地域复制
? ? ? ?Pulsar 中的跨地域复制是将 Pulsar 中持化的消息在多个集群间备份。在 Pulsar 2.4.0 中新增了复制订阅模式(Replicated-subscriptions),在某个集群失效情况下,该功能可以在其他集群恢复消费者的消费状态,从而达到热备模式下消息服务的高可用。

三、pulsar组件介绍
3.1 层级存储
? ? ? ? Infinite Stream:以流的方式永久保存原始数据
????????分区的容量不再受限制
????????充分利用云存储或现有的廉价存储 ( 例如 HDFS)
????????数据统一表征:客户端无需关心数据究竟存储在哪里

3.2 Pulsar I0(Connector)连接器
? ? ? ? Pulsar I0 分为输入(Input)和输出(Output)两个模块,输入代表数据从哪里来,通过 Source 实现数据输0入。输出代表数据要往哪里去,通过 Sink 实现数据输出。
????????Pulsar 提出了 Connector (也称为 Pulsar I),用于解决 Pulsar 与周边系统的集成问题,帮助用户高效完成工作。
????????目前 pulsar I0 支持非常多的连接集成操作:例如HDFS 、Spark、Flink 、Flume 、ES 、HBase等

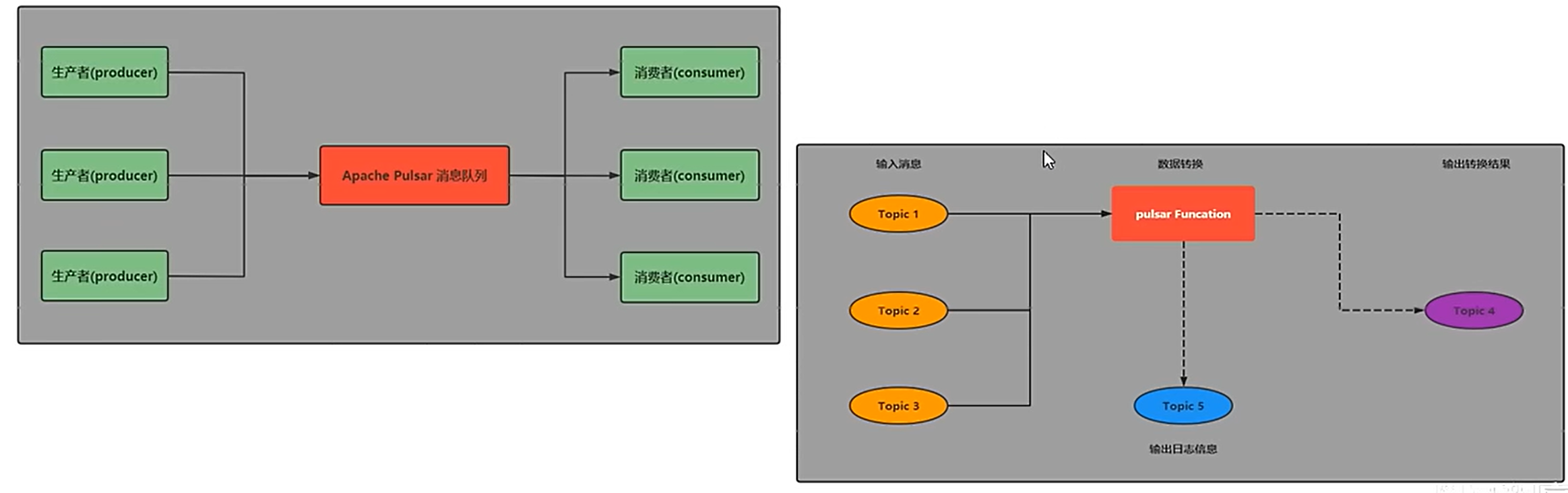
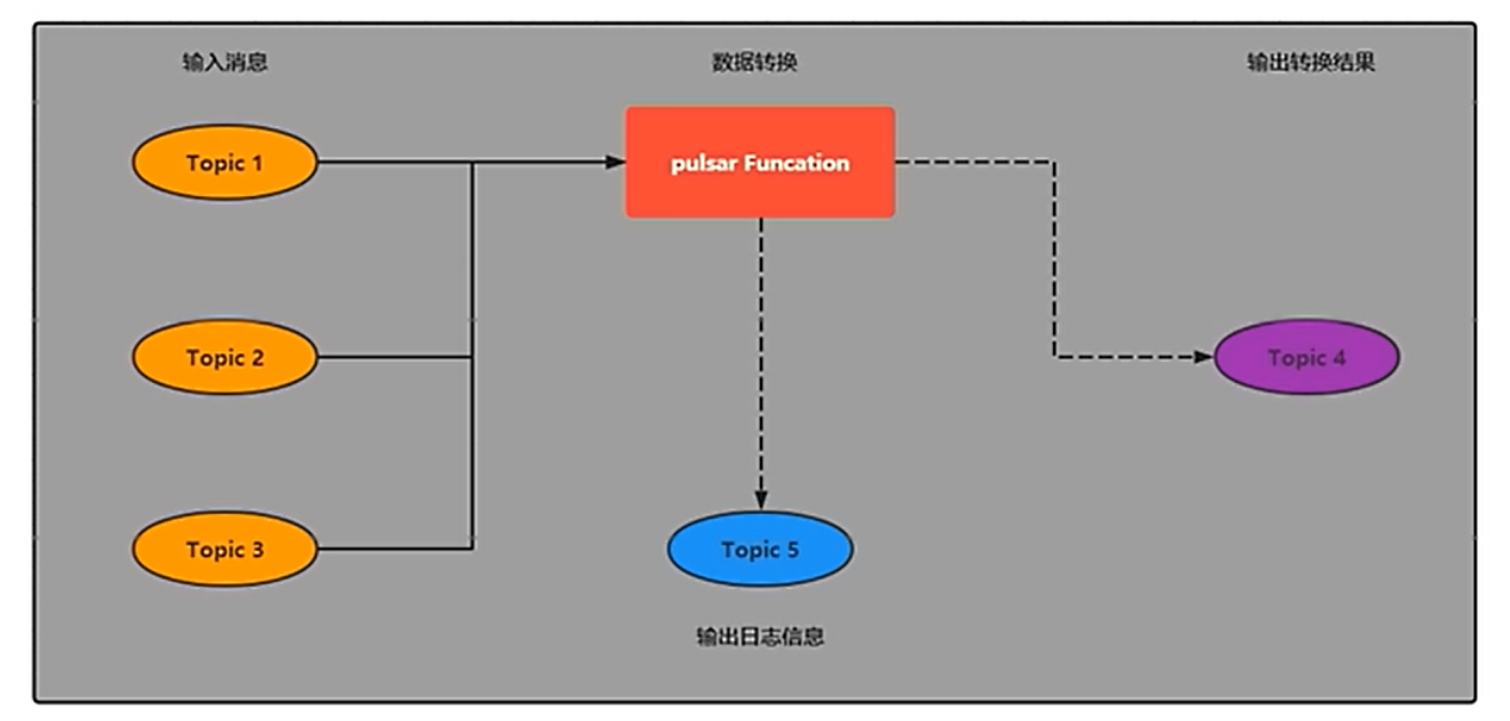
3.3 Pulsar Funcations(轻量级计算框架)
? ? ? ? Pulsar Functions 是一个轻量级的计算框架,可以给户提供一个部署简单、运维简单、API 简单的 FASS(Function as a service)平台。Pulsar Functions 提供基于事件的服务,支持有状态与无状态的多语言计算,是对复杂的大数据处理框架的有力补充
????????Pulsar Functions 的设计灵感来自于 Heron 这样的流处理引,Pusar Functions 将会拓展 Pulsar 和整个消息领域的未来。使用 Pulsar Functions,用户可以轻松地部署和管理 function,通过 function 从 Pulsatopic 读取数据或者生产新数据到 Pulsar topic。
四、pulsar 与kafka对比:
4.1?Pulsar和Kafka的对比介绍说明

? ? ? ?详细对比可以参考:kafka和pulsar的区别_pulsar kafka区别-CSDN博客
????????Apache Kafka和Apache Pulsar都有类似的消息概念。 客户端通过主题与消息系统进行交。 每个主题都可以分为多个分区。 然而,Apache Pulsar和Apache Kafka之间的根本区别在于Apache Kafka是以分区为存储中心,而ApachePulsar是以Segment为存储中心。
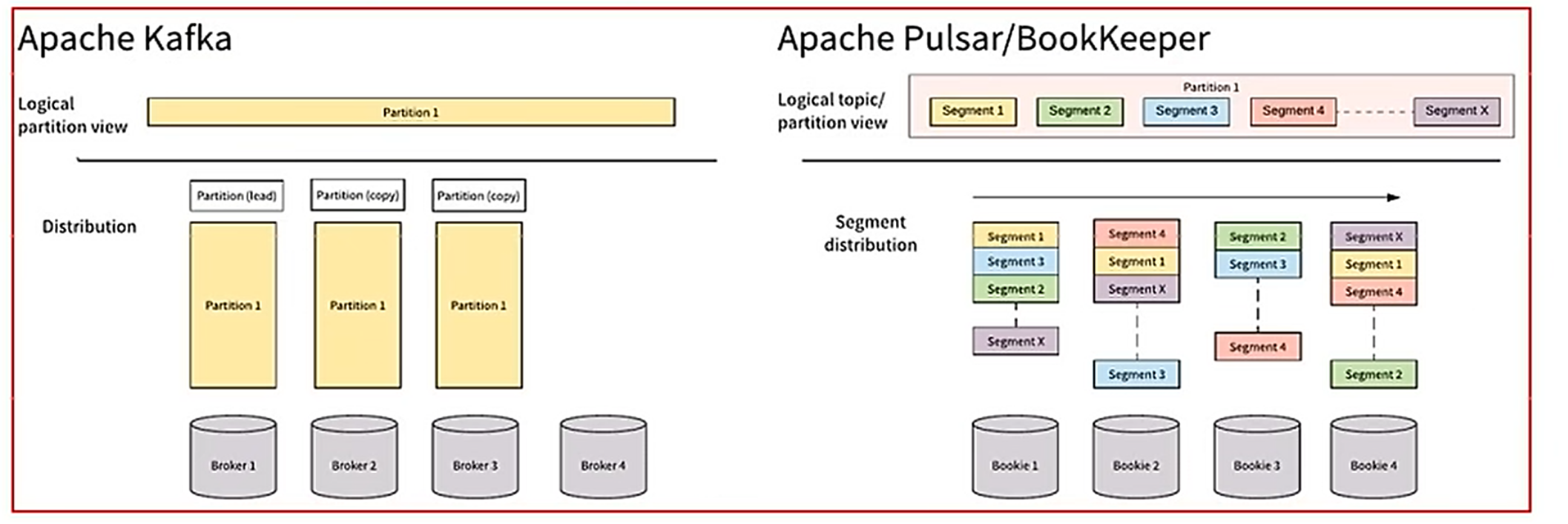
????????对比总结:
????????Apache Pulsar将高性能的流(Apache Kafka所追求的)和灵活的传统队列(RabbitMQ所追求的)结合到一个统一的消息模型和API中。 Pulsar使用统一的API为用户提供一个支持流和队列的系统,且具有同样的高性能。
4.2 性能对比:
? ? ? ? Pulsar 表现最出色的就是性能,Pulsar 的速度比 Kafka 快得多,美国德克萨斯州一家名为 Gigam(https://gigaom.com/) 的技术研究和分析公司对 Kafka 和 Pulsar 的性能做了比较,并证实了这一点
 4.3 扩展说明: kafka目前存在的痛点
4.3 扩展说明: kafka目前存在的痛点
? ? ? ? 1)Kafka很难进行扩展,因为 kafka 把消息持久化在 broker 中,迁移主题分区时,需要把分区的数据完全复制到其他 broker 中,这个操作非常耗时。
????????2)当需要通过更改分区大小以获得更多的存储空间时,会与消息索引产生冲突,打乱消息顺序。因此,如果用户需要保证消息的顺序,Kafka 就变得非常就0手了。
????????3)如果分区副本不处于 ISR(同步状态,那么 leader 选取可能会素乱。一般地,当原始主分区出现故障时,应该有一个 S 副本被征用,但是这点并不能完全保证。若在设置中并未规定只有 S 副本可被选为 leader 时,选出一个处于非同步状态的副本做 eader,这比没有 broker 服务该 partitior的情况更糟糕。
????????4)使用 kfaka 时,你需要根据现有的情况并充分考虑未来的增量计划,规划 broker、主题、分区和副本的数量,才能避免 aka 扩展导致的问题。这是理想状况,实际情况很难规划,不可避免会出现扩展需求。
????????5) Kafka 集群的分区再均衡会影响相关生产者和消费者的性能。
????????6)发生故障时,Kafka 主题无法保证消息的完整性(特别是遇到第 3 点中的情况,需要扩展时极有可能丢失消息)。
????????7)使用 Kafka 需要和 offset 打交道,这点让人很头痛,因为 broker 并不维护 consumer 的消费状态
????????8) 如果使用率很高,则必须尽快删除旧消息,否则就会出现磁盘空间不够用的问题。
????????9)众所周知,kafka 原生的跨地域复制机制 (Wiroraker)有问题,即使只在两个数据中心也无法正常使用跨地域复制。因此,甚至 Uber 都不得不创球另一套解决方案来解决这个问题,并将其称为 uReplicator (https://eng.uber.com/ureplicator/)。
????????10)要想进行实时数据分析,就不得不选用第三方工具,如 Apche Strm、Apache Heron 或 Apache Spark。同时,你需要确保这些第三方工具足以支撑传入的流量。
????????11)Kafka 没有原的多租户功能来实现租户的完全隔离,它是通过使用主题授权等安全功能来完成的。
五、pulsar架构:
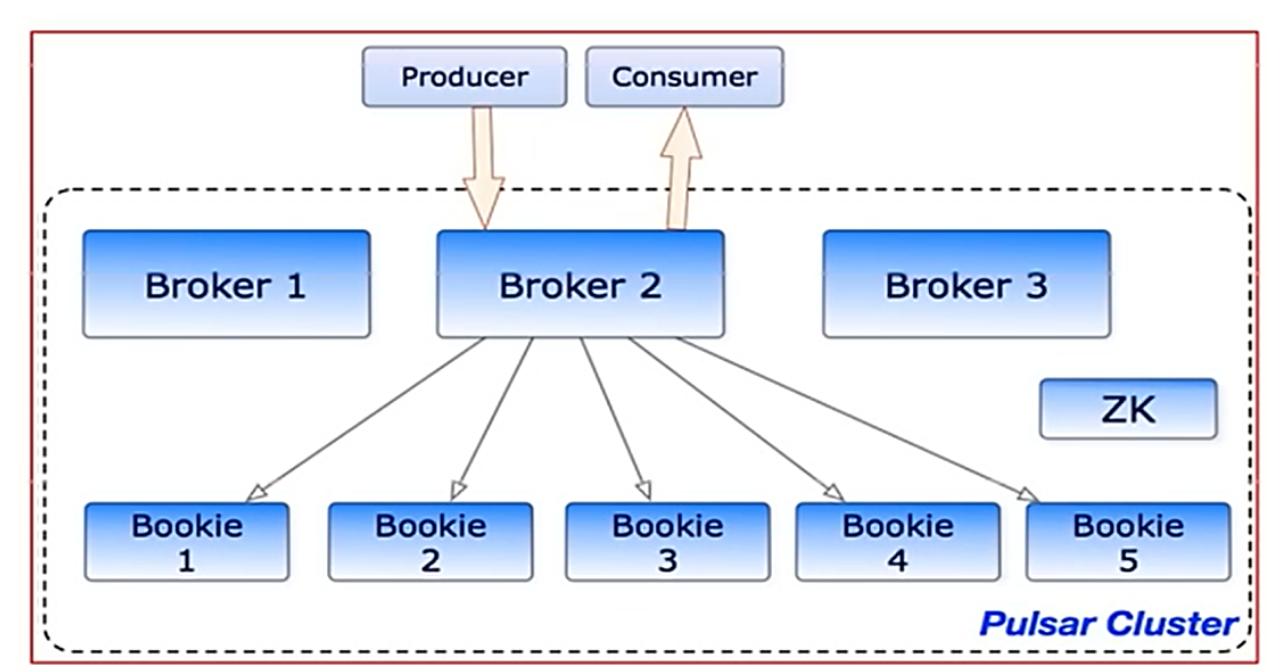
5.1单个 Pulsar 集群由以下三部分组成:
? ? ? ? 多个 broker负责处理和负载均衡 producer 发出的消息,并将这些消息分派给 consumer; Broker 与 Pulsar 配置存储交互来处理相应的任务,并将消息存储在 BokKeeper 实例中(又称 bookies); Broker 依赖 ZooKeeper集群处理特定的任务,等等。
????????多个 bookie的 BookKeeper 集群负责消息的持久化存储
????????一个zookeeper集群,用来处理多个Pulsar集群之间的协调任务
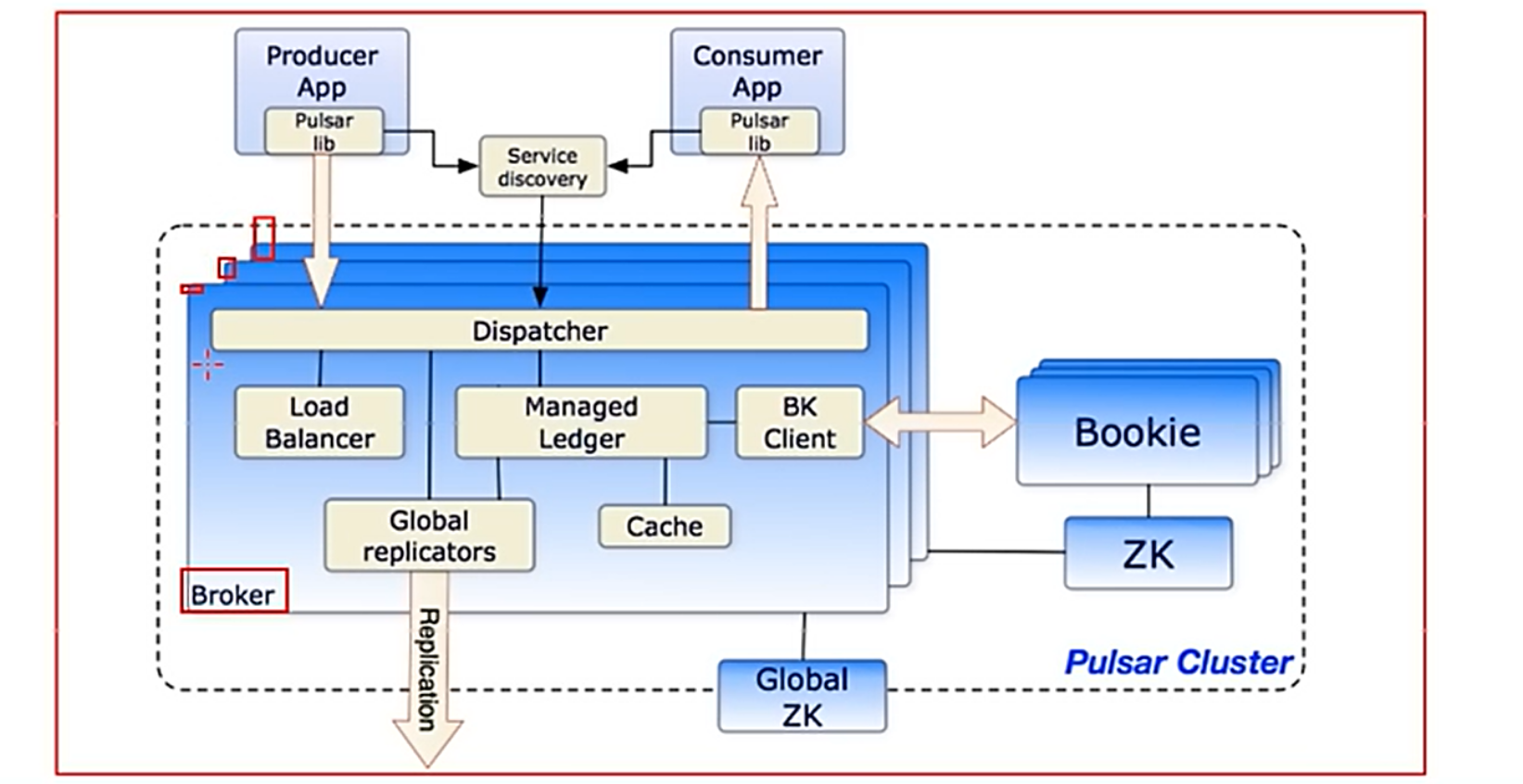
5.2 Brokers介绍
? ? ? ? Pulsar的broker是一个无状态组件,主要负责运行另外的两个组件:
????????一个 HTTP 服务器,它暴露了 REST 系统管理接口以及在生产者和消费者之间进行 Topic查找的API
????????一个调度分发器,它是异步的TCP服务器,通过自定义 二进制协议应用于所有相关的数据传输。
????????出于性能考虑,消息通常从Managed Ledger缓存中分派出去,除非积压超过缓存大小。如果积压的消息对于缓存来说太大了,则Broker将开始从BookKeeper那里读取Entries (Entry同样是BookKeeper中的概念,相当于一条记录)。
????????最后,为了支持全局Topic异地复制,Broker会控制Replicators追踪本地发布的条目,并把这些条目用Java 客户端重新发布到其他区域
5.3 Zookeeper的元数据存储
? ? ? ? Pulsar使用Apache Zookeeper进行元数据存储集群配置和协调
????????配置存储:存储租户,命名域和其他需要全局一致的配置项
? ? ? ? 每个集群有自己独立的ZooKeepr保存集群内部配置和协调信息,例如归属信息,broker负载报告,BooKeeper每个集群有自己独立的ZooKeeper保存集群的) 等等。
5.4 基于bookKeeper持久化存储
? ? ? ? 详细资料可以参考:BookKeeper 简介-腾讯云开发者社区-腾讯云
????????Apache Pulsar 为应用程序提供有保证的信息传递,如果消息成功到达broker,就认为其预期到达
????????为了提供这种保证,未确认送达的消息需要持久化存储直到它们被确认送达。这种消息传递模式通常称为持久消息传递,在Pulsar内部,所有消息都被保存并同步N份,例如,2个服务器保存四份,每个服务器上面都有镜像的RAID存储。Pulsar用 Apache bookkeeper作为持久化存储。 bookkeeper是一个分布式的预写日志 (WAL)系统,有如下几个特性特别适合Pulsar的应用场景:
????????1)使pulsar能够利用独立的日志,称为ledgers. 可以随着时间的推移为topic创建多个Ledgers
????????2) 它为处理顺序消息提供了非常有效的存储
????????3) 保证了多系统挂掉时Ledgers的读取一致性
????????4) 提供不同的Bookies之间均匀的I0分布的特性0
????????5)它在容量和吞吐量方面都具有水平伸缩性。能够通过增加bookies立即增加容量到集群中,并提升吞吐量
????????6)Bookies被设计成可以承载数千的并发读写的ledgers。 使用多个磁盘设备(一个用于日志,另一个用于一般存储),这样Bookies可以将读操作的影响和对于写操作的延迟分隔开。
????????Ledger是一个只追加的数据结构,并且只有一个写入器,这个写入器负责多个bookkeeper存储节点(就是Bookies)的写入Ledger的条目会被复制到多个bookies。 Ledgers本身有着非常简单的语义:
????????Pulsar Broker可以创建ledeger,添加内容到ledger和关闭ledger。
????????当一个ledger被关闭后,除非明确的要写数据或者是因为写入器挂掉导致ledger关闭,ledger只会以只读模式打开。
????????最后,当ledger中的条目不再有用的时候,整个ledger可以被删除 (ledger分布是跨Bookies的)。
5.5Pulsar 代理
? ? ? ? Pulsar客户端和Pulsar集群交互的一种方式就是直连Pulsar brokers。然而,在某些情况下,这种直连既不可行也不可运行Pulsar,直连取,因为客户端并不知道broker的地址。 例t在云环境或者Kubernetes以及其他类似的系统上面brokers就基本上不可能了。
? ? ? ? Pulsar proxy 为这个问题提供了一个解决方案,为所有的broker提供了一个网关,如果选择了Pulsar Proxy,所有的客户都会通过这个代理而不是直接与brokers通信
六、待续
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 在线短信变量批量编辑工具
- java freemarker 动态生成excel文件
- [nlp] 下载huggingface代码的预训练数据时会自动kill
- 海外 proxy代理Croxyproxy使用教程
- 【优质】「web开发网页制作」html+css关于动漫主题海贼王网页制作(7页面附源码)
- ARM架构简析
- STM32 AD5693R开发
- 【前端大创国奖】千帆聚明州——宋代宁波与海丝之路的不解之缘
- 算法第十三天-组合总和Ⅱ
- Windows系统如何使用VNC远程连接Deepin桌面【内网穿透】