C++面向对象(OOP)编程-多线程详解
几乎所有的编程语言都会支持多线程、多线程是现代操作系统提高系统运行效率的一个重要的手段,在算力有限的情况下,多线程在编程方面有着重要的地位。在一般的编程语言面试中少不了对多线程的考察。本文希望能够全面的介绍并实现C++中的多线程,为C++多线程提供指导。
🎬个人简介:一个全栈工程师的升级之路!
📋个人专栏:C/C++精进之路
🎀CSDN主页?发狂的小花
🌄人生秘诀:学习的本质就是极致重复!
目录
1.4.4 std::mutex和lock、unlock的使用
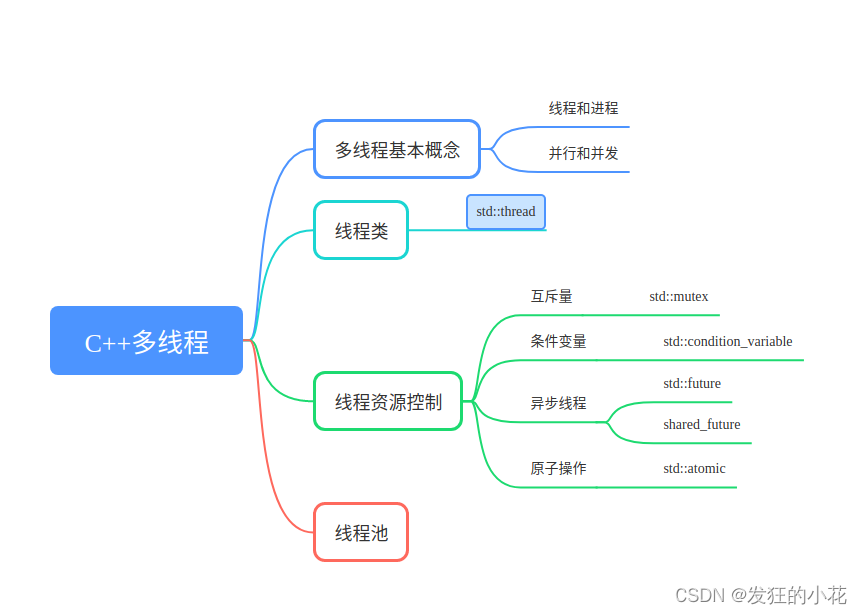
1 多线程介绍
? ? ? ? 要理解多线程需要理解线程和进程的区别。应用由程序和数据组成,程序中包括多个或者一个进程,进程中包括多个或者一个线程。进程的范围大于线程。
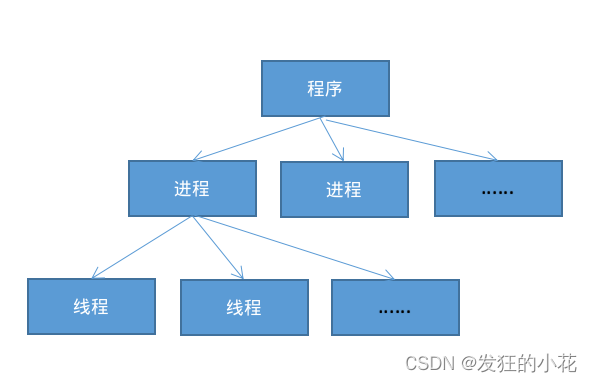
1.1 线程与进程的区别
????????进程是资源分配的最小单位,而线程是程序执行的最小单位。
????????也就是说,进程是系统中独立存在的程序关于某段时间内的动态变化过程,它拥有自己独立的地址空间,每启动一个进程,系统就会为它分配地址空间,建立数据表来维护代码段、堆栈段和数据段。
????????而线程则是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点在运行中必不可少的资源。
????????进程和线程的生命周期也不同。进程的生命周期通常比线程长,因为线程是隶属于进程的,当进程被销毁时,线程也会随之被销毁。相反,线程可以被创建和销毁多次,只要进程还存在。
????????进程和线程分别属于不同的执行单元,所以他们之间的通信也有所差异。同一进程内的线程之间通信更加容易和高效,因为共享相同的地址空间和全局变量等资源。而不同进程之间的通信则通常需要借助特定的机制,如管道、信号量等。
1.2 并行和并发的区别
????????并发是指两个或更多的事件在同一时间段内发生,这些事件可能涉及到同一个实体,比如一个处理器。这意味着处理器在某一时刻会处理多个任务,但这些任务并不是真正同时运行的,而是通过快速切换来实现“同时执行”的效果。
????????并行则是指两个或者多个事件在同一时刻发生,这通常涉及到不同的实体,如多个处理器或多核的处理器。这意味着每个处理器或核心都在独立地执行不同的任务,而这些任务是真正同时运行的。
????????简单来说,并发关注的是任务的抽象调度,即多个任务如何分配到处理器并快速切换以实现“同时执行”的效果;而并行关注的是任务的实际执行,即多个任务如何在多个处理器上真正同时运行。
1.3 多线程实例
? ? ? ? 多线程是实现并发的手段,将一个任务拆分为多个子任务使用多线程实现,以提高系统的运行效率,多线程实现的基础是指令流水线,通过指令并行完成并发。
? ? ? ? std::thread类主要的成员函数如下:
- std::thread():默认构造函数,创建一个新线程对象。
- std::thread(const std::thread&):拷贝构造函数,用另一个std::thread对象初始化新线程对象。
- std::thread& operator=(const std::thread&):赋值运算符,将一个std::thread对象的内容赋值给另一个std::thread对象。
- ~std::thread():析构函数,释放由std::thread对象管理的资源。
- void join():等待线程执行完成。如果线程已经结束,则该函数立即返回。否则,它会阻塞当前线程,直到目标线程执行完毕。
- void detach():将线程与当前对象分离。分离后的线程独立运行,不再与当前对象关联。detach()函数不会阻塞当前线程,也不会等待目标线程执行完毕。
- std::thread::id get_id():获取线程的唯一标识符。这个标识符可以用于识别和跟踪线程。
- bool joinable():检查线程是否可以被join()函数阻塞。如果线程已经被分离,或者已经执行完毕,那么此函数返回false;否则返回true。
- bool detached():检查线程是否已经被分离。如果线程已经被分离,那么此函数返回true;否则返回false。
- void swap(std::thread& other):交换两个std::thread对象的资源。这个函数通常用于在多线程环境中安全地交换两个std::thread对象的状态。
1.3.1 无参线程的创建
#include <iostream>
#include <thread>
using namespace std;
int value = 0;
void handler_1()
{
cout << "Thread is created!" << endl;
for(int i = 0;i < 10000;i++)
{
value++;
}
}
int main (int argc, char *argv[])
{
thread thd1 = thread(handler_1);
cout << "thd1 ID is: " << thd1.get_id() << endl;
thread thd2 = thread(handler_1);
cout << "thd2 ID is: " << thd2.get_id() << endl;
thd1.join();
thd2.join();
cout << "value: " << value << endl;
return 0;
}? ? ? ? 运行结果:
thd1 ID is: 140515887200000
Thread is created!
thd2 ID is: 140515878807296
Thread is created!
value: 19085? ? ? ? 上述代码中,没有自定义线程ID,因此线程ID使用默认的,可以通过thd1.get_id()来获取,分析结果,代码实际输出的value的值为19085,低于预期的20000,这是由于线程竞争导致的,此处应该加互斥量保护资源,下面会讲到。
? ? ? ? 为什么结果低于预期呢?因为两个线程在某一时刻可能获取到的值是一样的,这样,各自计算后得到的结果就一样,没有进行累加,所以会出现低于预期的结果。
1.3.2 有参线程的创建
? ? ? ? 线程参数的传递有值传递、引用传递(std::ref)、移动语义(右值引用)传递。
#include <iostream>
#include <thread>
using namespace std;
int value = 0;
void handler_1(int i)
{
cout << "Thread " << i << " is created!" << endl;
for(int i = 0;i < 10000;i++)
{
value++;
}
}
void handler_2(int & i)
{
cout << "Thread " << i << " is created!" << endl;
for(int i = 0;i < 10000;i++)
{
value++;
}
}
void handler_3(int && i)
{
cout << "Thread " << i << " is created!" << endl;
for(int i = 0;i < 10000;i++)
{
value++;
}
}
int main (int argc, char *argv[])
{
// 值传递
int thID1 = 1;
thread thd1 = thread(handler_1,thID1);
cout << "thd1 ID is: " << thd1.get_id() << endl;
// 引用传递
int thID2 = 2;
thread thd2 = thread(handler_2,std::ref(thID2));
cout << "thd2 ID is: " << thd2.get_id() << endl;
// 移动语义
int thID3 = 3;
thread thd3 = thread(handler_3,std::move(thID3));
cout << "thd3 ID is: " << thd3.get_id() << endl;
thd1.join();
thd2.join();
thd3.join();
cout << "value: " << value << endl;
return 0;
}? ? ? ? 运行结果:
thd1 ID is: 139773455705856
Thread 1 is created!
thd2 ID is: 139773447313152
Thread 2 is created!
thd3 ID is: 139773438920448
Thread 3 is created!
value: 29995? ? ? ? 注意C++中没有提供直接线程的返回值,可以通过传递共享指针方式、封装类、或者使用furture和promise来达到得到线程返回值的方式。这点与C语言不同,C语言的线程可以直接返回值,然后利用thd.join(&argv)中的 argv实现返回值类型的获取。可以参考我之前写的C语言多线程机制
1.3.3 线程的结束方式
? ? ? ? 线程的结束方式指的是线程的分离状态,分为分离线程(detach)和可汇合线程(join)。
????????分离线程(detach式):主动结束,启动的线程自主在后台运行,当前的代码继续往下执行,不等待新线程结束。主线程不会等待子线程结束。如果主线程运行结束,程序则结束。
????????可汇合线程(join式):等待启动的线程完成,才会继续往下执行。join后面的代码不会被执行,除非子线程结束。
????????如果 std::thread 对象销毁之前还没有做出决定,程序就会终止。一般可以使用joinable判断是join模式还是detach模式。? ? ? ?
join式:(父线程等待子线程结束后,才执行后面的语句)
#include <iostream>
#include <thread>
using namespace std;
int value = 0;
int handler_1(int i)
{
cout << "Thread " << i << " is created!" << endl;
for(int i = 0;i < 10000;i++)
{
value++;
}
return value;
}
int main (int argc, char *argv[])
{
// 值传递
int thID1 = 1;
thread thd1 = thread(handler_1,thID1);
cout << "thd1 ID is: " << thd1.get_id() << endl;
thd1.join();
cout << "value: " << value << endl;
return 0;
}? ? ? ? 运行结果:
?
Thread 1 is created!
thd1 ID is: 140115378468608
value: 10000detach式:(父线程不等待子线程结束就执行后面的语句)
#include <iostream>
#include <thread>
using namespace std;
int value = 0;
int handler_1(int i)
{
cout << "Thread " << i << " is created!" << endl;
for(int i = 0;i < 10000;i++)
{
value++;
}
return value;
}
int main (int argc, char *argv[])
{
// 值传递
int thID1 = 1;
thread thd1 = thread(handler_1,thID1);
cout << "thd1 ID is: " << thd1.get_id() << endl;
thd1.detach();
cout << "value: " << value << endl;
return 0;
}? ? ? ? 运行结果:
#include <iostream>
#include <thread>
using namespace std;
int value = 0;
int handler_1(int i)
{
cout << "Thread " << i << " is created!" << endl;
for(int i = 0;i < 10000;i++)
{
value++;
}
return value;
}
int main (int argc, char *argv[])
{
// 值传递
int thID1 = 1;
thread thd1 = thread(handler_1,thID1);
cout << "thd1 ID is: " << thd1.get_id() << endl;
thd1.detach();
cout << "value: " << value << endl;
return 0;
}? ? ? ? 运行结果:
Thread thd1 ID is: 1 is created!140537962235648
value: 2822????????1,线程是在thread对象被定义的时候开始执行的,而不是在调用join函数时才执行的,调用join函数只是阻塞等待线程结束并回收资源。
????????2,分离的线程(执行过detach的线程)会在调用它的线程结束或自己结束时释放资源。
????????3,没有执行join或detach的线程在程序结束时会引发异常
1.4 互斥量(mutex)
1.4.1 互斥量类型
? ? ? ? <mutex>中提供了多种互斥量的类,主要有4种,如下:
| 类型 | 说明 |
| std::mutex | 基础的mutex类 |
| std::recursive_mutex | 递归mutex类 |
| std::time_mutex | 定时mutex类 |
| std::recursive_timed_mutex | 定时递归mutex类 |
1.4.2 lock类
| std::lock_guard | 创建即加锁,作用域结束自动析构并解锁,无需手工解锁 不能中途解锁,必须等作用域结束才解锁 不能复制 |
| std::unique_lock | 创建时可以不锁定(通过指定第二个参数为std::defer_lock),而在需要时再锁定 可以随时加锁解锁 作用域规则同 lock_guard,析构时自动释放锁 不可复制,可移动 条件变量需要该类型的锁作为参数(此时必须使用unique_lock) |
1.4.3 lock和unlock函数
| std::lock() | 资源上锁 |
| std::unlock() | 资源上锁 |
| std::trylock() | 查看是否上锁,它有下列3种类情况: (1)未上锁返回false,并锁住; |
| std::call_once() | 如果多个线程需要同时调用某个函数,call_once 可以保证多个线程对该函数只调用一次。 |
1.4.4 std::mutex和lock、unlock的使用
? ? ? ? C++的互斥量在 <mutex>中,互斥量也叫互斥锁。互斥锁是一种同步原语,用于保护共享资源,防止多个线程同时访问。当一个线程拥有互斥锁时,其他线程必须等待该线程释放锁才能访问共享资源。
现在对1.3.1中的例子进行改进,如下:
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
std::mutex mtx;
int value = 0;
void handler_1()
{
mtx.lock();
cout << "Thread is created!" << endl;
for(int i = 0;i < 10000;i++)
{
value++;
}
mtx.unlock();
}
int main (int argc, char *argv[])
{
thread thd1 = thread(handler_1);
cout << "thd1 ID is: " << thd1.get_id() << endl;
thread thd2 = thread(handler_1);
cout << "thd2 ID is: " << thd2.get_id() << endl;
thd1.join();
thd2.join();
cout << "value: " << value << endl;
return 0;
}? ? ? ? 运行结果:
Thread is created!thd1 ID is:
139713576343296
thd2 ID is: 139713567950592
Thread is created!
value: 20000? ? ? ?分析代码可知,此时无论执行多少次程序,value的值始终是20000。
1.4.5?lock_guard的使用
#include <thread>
#include <mutex>
#include <iostream>
#include <unistd.h>
int value = 0;
std::mutex mtx; // protects g_i,用来保护g_i
void safe_increment()
{
const std::lock_guard<std::mutex> lock(mtx);
for (int i = 0;i < 10000;i++)
{
++value;
}
std::cout << std::this_thread::get_id() << ": " << value << '\n';
// mtx 自动解锁
}
int main()
{
std::cout << "main id: " <<std::this_thread::get_id()<<std::endl;
std::cout << "main: " << value << '\n';
std::thread t1(safe_increment);
std::thread t2(safe_increment);
t1.join();
t2.join();
std::cout << "main: " << value << '\n';
}? ? ? ? 运行结果:
main id: 140587614791488
main: 0
140587596809984: 10000
140587588417280: 20000
main: 200001.4.6??unique_lock 的使用
例子1:
#include <mutex>
#include <thread>
#include <iostream>
struct Person {
explicit Person(int num) : num_things{num} {}
int num_things;
std::mutex m;
};
void handler(Person &from, Person &to, int num)
{
// defer_lock表示暂时unlock,默认自动加锁
std::unique_lock<std::mutex> lock1(from.m, std::defer_lock);
std::unique_lock<std::mutex> lock2(to.m, std::defer_lock);
//两个同时加锁
std::lock(lock1, lock2);//或者使用lock1.lock()
from.num_things -= num; // 90 95
to.num_things += num; // 60 55
//作用域结束自动解锁,也可以使用lock1.unlock()手动解锁
}
int main()
{
Person acc1(100);
Person acc2(50);
std::thread t1(handler, std::ref(acc1), std::ref(acc2), 10);
std::thread t2(handler, std::ref(acc2), std::ref(acc1), 5);
t1.join();
t2.join();
std::cout << "acc1 num_things: " << acc1.num_things << std::endl;
std::cout << "acc2 num_things: " << acc2.num_things << std::endl;
}? ? ? ? 运行结果:
acc1 num_things: 95
acc2 num_things: 55例子2:
#include<iostream>
#include<thread>
#include<mutex>
using namespace std;
mutex m;
void handler1(int & a)
{
unique_lock<mutex> g1(m, defer_lock); //始化了一个没有加锁的mutex
g1.lock(); //手动加锁,注意,不是m.lock()
cout << "proc1函数正在改写a" << endl;
cout << "proc1函数a为" << a << endl;
a = a+2;
cout << "proc1函数a+2为" << a << endl;
g1.unlock(); //临时解锁
cout << "尝试自动解锁" << endl;
g1.lock();
cout << "运行后自动解锁" << endl;
} //自动解锁
void handler2(int & a)
{
unique_lock<mutex> g2(m, try_to_lock); //尝试加锁,但如果没有锁定成功,会立即返回,不会阻塞在那里
cout << "proc2函数正在改写a" << endl;
cout << "proc2函数a为" << a << endl;
a = a+1;
cout << "proc2函数a+1为" << a << endl;
} //自动解锁
int main()
{
int a = 0;
thread t1(handler1, ref(a));
thread t2(handler2, ref(a));
t1.join();
t2.join();
cout << "最后a: " << a << endl;
return 0;
}? ? ? ? unique_lock支持所有权的转移:
mutex m;
{
unique_lock<mutex> T1(m,defer_lock);
unique_lock<mutex> T2(move(T1));//所有权转移,此时由T2来管理互斥量m
T2.lock();
T2.unlock();
T2.lock();
}1.5 条件变量(condition_variable)
C++条件变量是一种同步原语,用于在多线程编程中实现线程间的通信。它允许一个或多个线程等待某个条件成立,当条件成立时,唤醒等待的线程继续执行。
条件变量是利用线程间共享的全局变量进行同步的一种机制,主要包括两个动作:
1,一个线程等待条件变量的条件成立而挂起;
2,另一个线程使条件成立(给出条件成立信号)。
condition_variable条件变量可以阻塞(wait、wait_for、wait_until)调用的线程直到使用(notify_one或notify_all)通知恢复为止。
头文件<condition_variable>
- condition_variable
- ?condition_variable_any
相同点:两者都能与std::mutex一起使用。
不同点:前者仅限于与 std::mutex 一起工作,而后者可以和任何满足最低标准的互斥量一起工作,从而加上了_any的后缀。condition_variable_any会产生额外的开销。
注意:
1,一般只推荐使用condition_variable。除非对灵活性有硬性要求,才会考虑condition_variable_any。
2,condition_variable必须结合unique_lock使用
3,condition_variable是一个类,这个类既有构造函数也有析构函数,使用时需要构造对应condition_variable对象
例子1:(wait)
当前线程调用 wait() 后将被阻塞(此时当前线程应该获得了锁(mutex),不妨设获得锁 lck),直到另外某个线程调用 notify_* 唤醒了当前线程。
在线程被阻塞时,该函数会自动调用 lck.unlock() 释放锁,使得其他被阻塞在锁竞争上的线程得以继续执行。另外,一旦当前线程获得通知(notified,通常是另外某个线程调用 notify_* 唤醒了当前线程),wait()函数也是自动调用 lck.lock(),使得lck的状态和 wait 函数被调用时相同。
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
std::mutex mtx; // 互斥锁
std::condition_variable cv; // 条件变量
bool ready = false; // 全局标志位
void print_id(int id) {
std::unique_lock<std::mutex> lck(mtx);
while (!ready) { // 如果标志位为false,等待
cv.wait(lck); // 释放锁并等待条件变量唤醒
}
// 打印线程ID
std::cout << "thread " << id << ' ' << std::endl;
}
void go() {
std::unique_lock<std::mutex> lck(mtx);
ready = true; // 设置标志位为true
cv.notify_all(); // 唤醒所有等待的线程
}
int main() {
std::thread threads[10];
for (int i = 0; i < 10; ++i) {
threads[i] = std::thread(print_id, i);
}
std::cout << "10 threads ready to race...";
go(); // 通知所有线程开始比赛
for (auto& th : threads) {
th.join(); // 等待所有线程结束
}
return 0;
}? ? ? ? 运行结果:
10 threads ready to race...thread 6
thread 2
thread 4
thread 5
thread 7
thread 8
thread 9
thread 1
thread 3
thread 0 例子:(wait_for)
与std::condition_variable::wait() 类似,不过 wait_for可以指定一个时间段,在当前线程收到通知或者指定的时间 rel_time 超时之前,该线程都会处于阻塞状态。 而一旦超时或者收到了其他线程的通知,wait_for返回,剩下的处理步骤和 wait()类似。
#include <iostream> // std::cout
#include <thread> // std::thread
#include <chrono> // std::chrono::seconds
#include <mutex> // std::mutex, std::unique_lock
#include <condition_variable> // std::condition_variable, std::cv_status
std::condition_variable cv;
int value;
void read_value() {
std::cin >> value;
cv.notify_one();
}
int main ()
{
std::cout << "Please, enter an integer (I'll be printing dots): \n";
std::thread th (read_value);
std::mutex mtx;
std::unique_lock<std::mutex> lck(mtx);
while (cv.wait_for(lck,std::chrono::seconds(1))==std::cv_status::timeout) {
std::cout << '.' << std::endl;
}
std::cout << "You entered: " << value << '\n';
th.join();
return 0;
}? ? ? ? 运行结果:
Please, enter an integer (I'll be printing dots):
.
.
10
You entered: 101.6 异步线程
1.6.1 std::future
C++中的异步线程可以通过std::async函数实现。std::async函数会创建一个新的线程来执行给定的可调用对象,并返回一个std::future对象,用于获取异步任务的结果。
例子:
#include <iostream>
#include <future>
#include <chrono>
int main() {
// 创建一个异步任务,执行一个耗时的操作
std::future<int> result = std::async(std::launch::async, []() {
std::this_thread::sleep_for(std::chrono::seconds(1)); // 模拟耗时操作
return 42; // 返回结果
});
// 在等待异步任务完成的同时,可以执行其他操作
std::cout << "Doing something else..." << std::endl;
// 获取异步任务的结果
int value = result.get();
std::cout << "Result: " << value << std::endl;
return 0;
}
1.6.2 std::shared_future
shared_future是C++17中引入的一个异步线程库,它允许多个线程共享一个异步任务的结果。shared_future是一个模板类,可以用于存储任何类型的结果。它提供了一种机制,使得多个线程可以等待异步任务完成并获取其结果。
使用shared_future的基本步骤如下:
- 创建一个异步任务,例如使用
std::async函数。 - 将异步任务的结果存储在一个
shared_future对象中。 - 在需要获取结果的线程中,调用
shared_future对象的wait()方法等待异步任务完成。 - 调用
shared_future对象的get()方法获取异步任务的结果。
#include <iostream>
#include <future>
#include <thread>
int main() {
// 创建一个异步任务,计算两个数的和
std::future<int> result = std::async([]() {
std::this_thread::sleep_for(std::chrono::seconds(2)); // 模拟耗时操作
return 42 + 84;
});
// 在主线程中等待异步任务完成
result.wait();
// 获取异步任务的结果
int sum = result.get();
std::cout << "The sum is: " << sum << std::endl;
return 0;
}
1.6.3 future 和 shared_future区别
future与shard_future的用途都是为了占位,但是两者有些许差别。future的get()成员函数是转移数据所有权;shared_future的get()成员函数是复制数据。
future对象的get()只能调用一次;无法实现多个线程等待同一个异步线程,一旦其中一个线程获取了异步线程的返回值,其他线程就无法再次获取。
shared_future对象的get()可以调用多次;可以实现多个线程等待同一个异步线程,每个线程都可以获取异步线程的返回值。
1.7 原子操作(atomic)
????????C++ atomic是C++11标准库中提供的一种用于多线程编程的原子类型,它可以保证对某个变量的操作是原子性的,即不会被其他线程打断。
C++ atomic类型提供了一些基本的原子操作,例如:
- load:读取一个原子变量的值。
- store:将一个值赋给一个原子变量。
- compare_exchange_weak:比较并交换原子变量的值,如果当前值等于预期值,则将其设置为新值。
- compare_exchange_strong:比较并交换原子变量的值,如果当前值等于预期值,则将其设置为新值,否则不进行任何操作。
- fetch_add:将原子变量的值加1。
- fetch_sub:将原子变量的值减1。
- fetch_and:将原子变量的值与给定值按位与。
- fetch_or:将原子变量的值与给定值按位或。
- fetch_xor:将原子变量的值与给定值按位异或。
使用C++ atomic类型可以有效地避免多线程并发访问共享数据时出现的竞争条件和数据不一致的问题,并且不会。
使用atomic的变量可以减少锁的使用,提高效率,并保证数据访问的一致性问题。
#include <iostream>
#include <atomic>
#include <thread>
#include <mutex>
#include <condition_variable>
#include "common.h"
namespace ATOMIC_DAY27
{
/*
C++中的atomic是用于实现原子操作的类模板,它位于头文件中。原子操作是指在多线程环境下,一个操作是不可分割的,不会被其他线程打断。
atomic提供了一种简单、安全的方式来进行原子操作,避免了使用锁和互斥量等复杂的同步机制。
atomic支持以下几种类型的数据:
整数类型(如int、long、short、char等)
指针类型
用户自定义类型
*/
std::atomic<int> count(0); // 定义一个原子整数变量count,初始值为0
void increase() {
for (int i = 0; i < 10000; ++i) {
count.fetch_add(1, std::memory_order_relaxed); // 以relaxed内存序增加count的值
}
}
};
namespace NORMAL_DAY27
{
int count = 0;
void increase() {
for (int i = 0; i < 10000; ++i) {
count++;
}
}
};
int main() {
{
__LOG__("atomic");
using namespace ATOMIC_DAY27;
std::thread t1(increase); // 创建一个线程t1执行increase函数
std::thread t2(increase); // 创建一个线程t2执行increase函数
t1.join(); // 等待线程t1执行完毕
t2.join(); // 等待线程t2执行完毕
std::cout << "count: " << count << std::endl; // 输出count的值
}
{
__LOG__("normal");
using namespace NORMAL_DAY27;
std::thread t1(increase); // 创建一个线程t1执行increase函数
std::thread t2(increase); // 创建一个线程t2执行increase函数
t1.join(); // 等待线程t1执行完毕
t2.join(); // 等待线程t2执行完毕
std::cout << "count: " << count << std::endl; // 输出count的值
}
return 0;
}
? ? ? ? 运行结果:
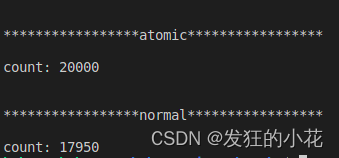
? ? ? ? 由结果分析可知,atomic的变量在不使用锁的情况下,保证了数据访问的一致性。
1.8 线程池
????????线程池是一种多线程处理形式,通常包含一组预先创建的线程和一个任务队列。在系统启动时,线程池会创建大量空闲的线程,并且一直存活着,等待新的任务到来。当有一个新的任务到来时,线程池中的一个线程会被选中来执行这个任务。任务完成后,该线程并不会被销毁,而是会继续留在线程池中,等待下一个任务的到来。
????????线程池内部主要由任务队列、一组线程以及一个管理者线程组成。其中,任务队列用于存放待执行的任务,线程组中的每个线程都负责执行任务队列中的任务,而管理者线程则负责管理工作队列和线程组。
此外,需要注意的是,线程池是消费者生产者模型的其中之一,这里面的线程同步很重要,稍不注意就会造成死锁。主要用的是互斥锁mutex。
使用线程池可以显著提高程序的性能。因为线程的创建和销毁需要消耗大量的系统资源,通过重复利用已创建的线程,可以大大减少这部分开销。此外,合理管理线程池中的线程数量也可以避免因线程过多而导致的资源竞争问题。
1.8.1 线程池的优势
-
降低资源消耗:通过重复利用已创建的线程,减少因线程创建和销毁造成的系统资源消耗。
-
提高响应速度:当任务到达时,线程池中已有空闲线程可以立即执行任务,无需等待线程的创建。
-
提高线程的可管理性:线程是稀缺资源,无限制地创建线程不仅会消耗系统资源,还可能降低系统的稳定性。使用线程池可以进行统一的分配、监控和调优,有效提升线程的管理效率。
-
实现某些与时间相关的功能:如定时任务,周期执行等。
-
隔离线程环境:一个线程专门执行耗时任务,另外一个线程执行响应要求高的任务。
🌈我的分享结束了🌈
如果我的分享也能对你有帮助,那就太好了!
若有不足,还请大家多多指正,我们一起学习交流!
📢未来的富豪们:点赞👍→收藏?→关注🔍
感谢大家的观看和支持!最后,?祝愿大家每天有钱赚!!!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 保姆月嫂企业网站建设的效果如何
- PyTorch|保存与加载自己的模型
- 强网杯2022GameMaster复现
- C语言实现扫雷游戏
- 父类,父类的分类、子类 同时重写方法,调用问题
- 智能配电房在线监测系统
- 百度侯震宇:AI原生与大模型将从三个层面重构云计算
- 黑客掌握的木马攻击运行的技巧之一开机启动并隐藏 cmd 窗口程序在后台运行
- configparser模块
- Spring ‘24:不容错过的Salesforce Flow 10大新功能!