安装tesseract
发布时间:2024年01月15日
Tesseract OCR是一款由HP实验室开发由Google维护的开源OCR引擎,在字符识别领域发挥着举足轻重的作用。除了使用软件自带的中英文识别库,我们可以使用Tesseract OCR训练属于自己的字库。
下载地址:https://digi.bib.uni-mannheim.de/tesseract/
注意:3.0以上才支持中文
安装
这里选择语言包
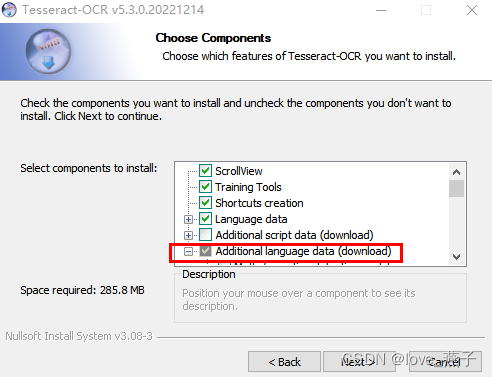
这里选择中文
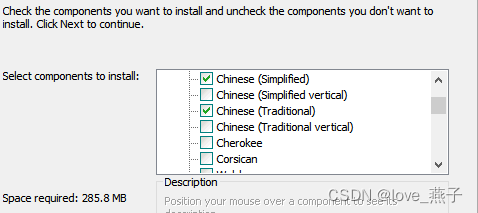
配置环境变量
1、在环境变量—用户变量path中添加Tesseract OCR路径和tessdata路径
D:\Program Files\Tesseract-OCR
D:\Program Files\Tesseract-OCR\tessdata
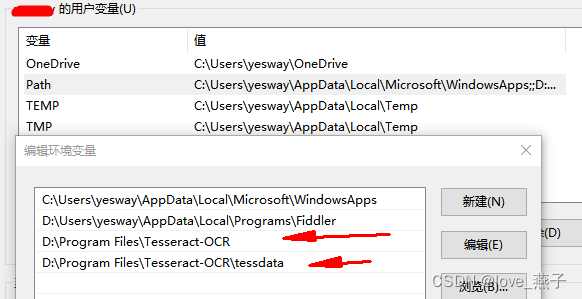
2、在环境变量—系统变量path中增加Tesseract OCR路径和tessdata路径
3、在环境变量–系统变量中添加TESSDATA_PREFIX变量,并添加变量值D:/Program Files/Tesseract-OCR/tessdata/
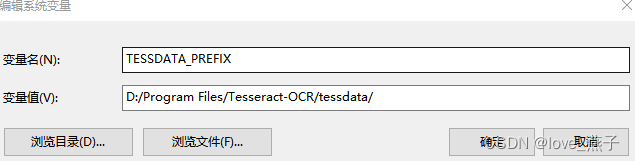
注意:这里的斜杠是反方向的
下载字库
要识别中文需要chi_sim.traindata字库,放到Tesseract-OCR中tessdata下,默认自带该字库,也可以在git中下载。
字库下载地址:https://github.com/tesseract-ocr/tessdata
测试
执行命令查看tessreact是否安装成功
tesseract -v

执行名称查看图片识别是否成功
tesseract test.png result -l chi_sim

在当前文件夹下就会生成一个result.txt可以查看结果。
文章来源:https://blog.csdn.net/u010833154/article/details/135599860
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Spring实战】10 Security 入门
- PyQt5多线程使用
- 如何查看iPad尺寸,这里提供两种办法
- 深入Pandas:数据分析的强大工具
- 转转交易猫自带客服多模板全开源完整定制版源码
- 数据处理大杀器:Python Collections 模块全攻略
- 中仕教育:省考联考可以报多个省份吗?
- 【ubuntu 22.04】安装中文版系统、中文语言包和中文输入法
- 启动redis出现Creating Server TCP listening socket 127.0.0.1:6379: bind: No error异常
- 掌动智能浅谈云网络流量分析的主要过程