[React面试题]核心算法的重构----Fiber
文章概叙
本文主要写的是对Fiber的一些介绍,没有很深的介绍,比如更新优先级之类的,纯粹是对Fiber的一些概念以及原理做一些介绍,让人有部分的了解。
写在前面
文章针对的是新手,所以我会尽量用简单的方法去描写这么一个过程,对于Fiber的文章,网上有很多很多,如果想要系统的学习,我强烈建议去看下React官网上的介绍以及一些大厂的文章!!
Virtual DOM

Virtual DOM,对React的开发者来说已经很熟悉了,虚拟DOM的设计思路,就是构建一个JavaScript对象,且该对象是根据DOM树作为参考。
当用户的界面第一次渲染时,React会创建一个节点树,每一个单独的节点,都代表了一个React元素(不是DOM对象),而由于在结构上所有的对象呈现一个树的形象,所以我们会称其为虚拟树,也就是我们的Virtual DOM。
当我们需要更新页面的时候,会遍历我们的树(也就是Virtual DOM 组成的VDom 树,下面称之为Vdom树)。然后与新的VDom树进行对比。
当得到我们的VDom树的变动之后,将其更新到页面上去。
而进行对比的过程,就称之为reconciliation。

VDom树的结构如下(大概的例子):
{
"type": "ul",
"props": {
"children": [
{
"type": "li",
"props": {
"children": "itema"
}
},
{
"type": "li",
"props": {
"children": "itemb"
}
}
]
}
}
对应我们的Dom树如下:
<ul>
<li>itema</li>
<li>itemb</li>
</ul>
在此设计下,我们就可以每次都将页面的更改保存在我们的VDom树中,最后调用方法去更新树,能够很有效地减少我们的页面更新,将所有的变动都在一次中去刷新。
链表结构?
此时,让我们走一条别的路,先讲解下后面会用到的链表结构。
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
在我们的理解上,链表结构就是由多个单独的节点组成,并且每一个节点会有一个指针,指向它的下一个节点。

在物理层次的存储上,由于链表是一个又一个的节点,所以可以做到见缝插针,无需将其与其他的同类型节点放在一起。(这儿与文章主题无关,不牵涉)。
既然知道了链表在内存中的不连贯性,我们也很容易得知—,链表有一个很严重的缺点----无法做到随机查询,必须要从链表的表头开始一个一个查询下去,才可以找到我们想要更改的那个节点,换句话来说。
链表结构最常用的查询方式是"遍历查询"
而链表也有一个很好的优点:“独立性”。
每一个节点都是一个单独的节点,而不是属于树状结构中的一部分~当我们要知道各个节点关系的时候,我们需要通过指针,还原他们的关系。
Fiber要解决的问题
正如上面章节所说,每一次做reconciliation的时候,我们是对比整个VDom树的。
而对比整个树的过程中,我们是无法做到"暂停"的,比如我们在代码中是用两个Object去对比,用一个递归函数去对比,而我们不会说去找个判断去停止递归函数…一般不会有人这么写…毕竟无法保证这个暂停的操作会导致什么奇怪的bug,比如某一个很后很后的元素,每次都更新不到。
既然我们是递归函数去对比两个VDom树的差异,那么一个页面上那么多的元素,势必会占用浏览器的资源,正如我在前面所说的,我们无法在一个深度递归中暂停,而一直占用了浏览器的资源,就有可能导致用户触发的事件得不到响应(比如输入框有时候卡卡的)。
基于上述的问题,React就重构了自己的核心算法,并推出了Fiber(React-Fiber)。
一个能将React的更新任务拆分成更小的任务,并且添加优先级排序。使用"requestIdleCallback"这个API ,将优先级较低的放在了浏览器的空闲时间中去操作,以达到让用户体验更加友好,也让页面更加丝滑的目的~
关于Fiber

Fiber是对React核心算法的重构,在React16以上的版本中引入了Fiber架构。
注意哦,不是大名鼎鼎的React16.8,而是2017年的React版本(7年前…)
React-Fiber的核心是将一个任务拆分成一个很小很小的单位,在树状结构的VDom中,我们会将每一个节点都视为一个Fiber节点。且不再采用树状结构去维持他们的关系,而是采用了链表结构去记录与其相关的节点,也就是之前的章节所说的"通过指针去维持每一个fiber节点的关系"。比如一个Virtual Dom在使用虚拟树的时候,结构是如下的
{
"type": "li",
"props": {
"children": "itemb"
}
}
此时,我们需要在当前的结构下,添加上他的父级元素,子级元素以及兄弟元素等。在代码层次的体现上,大体结构如下:
{
"type": "li",
"id":"id",//元素的唯一标识
"props": {
"children": "itemb"
},
child:child_id//子元素的唯一id
parent:parent_id//父元素的唯一id
siblings:[]//兄弟元素的id以及关系
}
此时,我们就获得了一个由Dom树序列化过来的一维数组,我们将其反转成一个Dom树也是极其的方便,只需要根据fiber中的属性来确定其在VDom树中的位置。
而判断是否有有变化也很简单,我们只需要将两个Vdom都转化之后,再将每一个fiber节点都进行判断,遍历的逻辑也是先主脉,再记录下分叉点,后面遍历完这一脉之后再回来上一个分叉点再遍历一次。
fiber节点的具体属性不单单只有这么些,这儿只是希望大家有一个初步理解。
这种方法的原理也很简单,相当于Fiber将"a是c的孙子"转化为了"a是b的父亲,b是c的父亲”这样的结构,能更清晰看到关系。
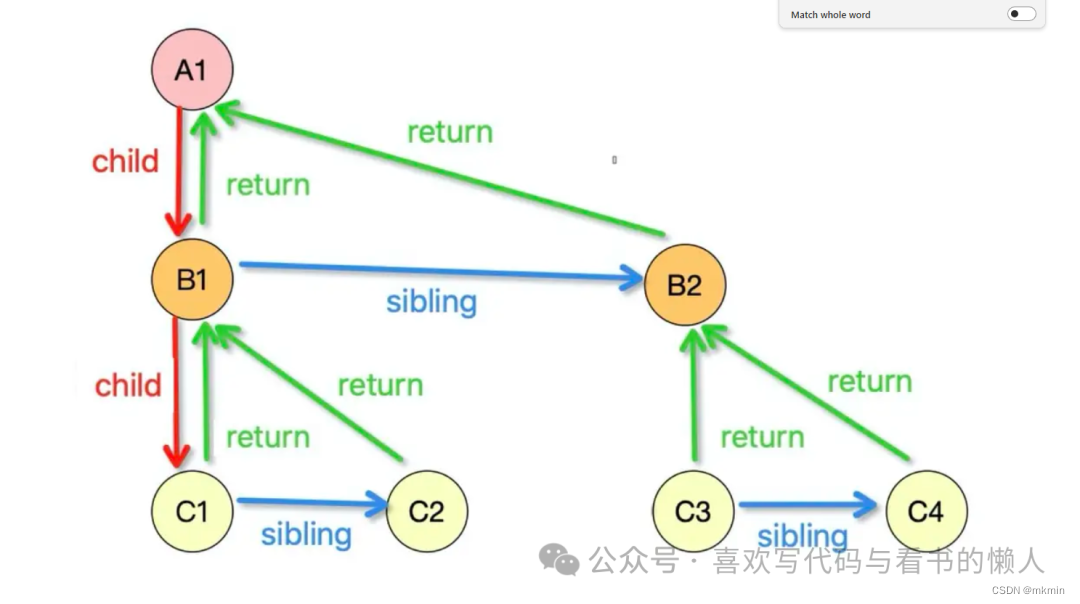
为了让大家大概的理解Fiber的设计思路,前面讲了一个大概的例子,但在面试的时候,我们不能这么说,我们需要从Fiber的执行过程讲起,也就是render阶段以及commit阶段。
render阶段
一个可以中断的阶段,找出所有节点的变更。
此阶段,会找出所有的节点变动,如新增、删除、属性变更等等。此时由于这些变动,会产生我们常常说到的副作用----Effect。
在此阶段的时候,会构建一个Fiber tree(也就是下图)
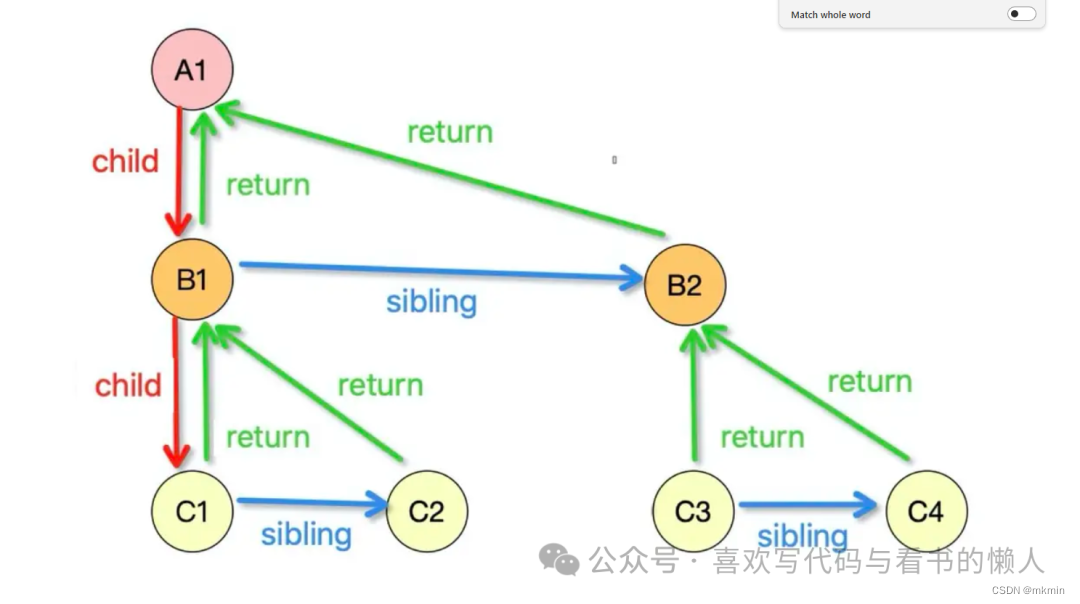
而以每一个Fiber 节点为单位,对任务进行拆分,一个fiber对应一个小任务,最后产生一个Effect List,我们也就可以根据Effect List去做对应的副作用操作。
至此,我们已经收集到了由fiber组成的一个链表,其中代表了我们的每一个更新,由于是树状的结构,所以每一个单独的更新中,我们都会有一个”第一个更新“(first Effect)还有”最后一个更新“(Last Effect)属性,因为我们需要知道自己是从哪儿走上分岔路口,具体的篇幅比较长,需要有一定的链表知识,建议在React的官网上查看,这儿只是整理出大概的思路。
而之所以能进行"停止",是因为我们可以记录到你上一次操作的是哪个filber,我们就可以下次从这儿继续开始,而整理数据并不需要花费多少的时间,所以我们就可以放在”requestIdleCallback“中去执行~
commit阶段
不可中断的阶段,执行所有的变更。
在render阶段中,我们获取到了所有的变动,而计算出来的副作用,就需要在这一个阶段中更新到我们的页面中,既然是更新页面了,势必不能只更新一部分,所以commit阶段是无法中断的。
假设,在上一阶段中,我们获取到了一个副作用链表,其中一个元素如下
{
"id": "1", //唯一id
"pid": "0", //父元素的id
"nextEffect_id": "2", //下一个effect的id
"type": "insert" //该节点的操作类型
}
我们就可以用一个递归去循环,该节点是属于"insert",则说明了该节点是新增,增加完该节点后,我们根据nextEffect_id去找到下一个fiber节点,然后再去做相对应的操作, 而当我们来到链表的最后一个节点,也就是没有nextEffect_id字段的时候,我们就应该调用一个更新页面的方法,去批量的更新视图了。
到了现在,我们的VDom树也更新了,我们的页面也刷新了,页面也没有那么卡了。
总结
说了那么多的废话,其实最简单的回答就是一句:React现在已经是使用了Fiber的时代。Fiber的出现,也让我们需要更需要了解什么是Effect,以及新的生命周期(只是说有一定的关系,不是说有必然关系!)
React-Fiber最主要的操作是将树状结构改成了链表结构。因为链表结构也更适合当前的版本。
在渲染页面的阶段没有太大的变化,依旧是找出不同,直接更新页面~
文章写得有点杂,为了适合新手读文章理解概念,所以删除了很多复杂的地方,会造成文章不连贯的感觉,建议看下React的发布会上对于Fiber的介绍补充下理解。

主要介绍前端开发的博客,由衷期望各位大佬们扫码关注
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!