Unprocessing Images for Learned Raw Denoising
发布时间:2023年12月25日
RWA Image Dataset:the Darmstadt Noise Dataset
Abstract
1、Introduction
1、传统图像去噪方法:分析图像属性、对噪声建模(传统方法好像总是这样,建立模型然后用数学方法贴近模型)
TBD:找传统的3-5种方法过一遍
2、深度学习图像去噪方法思路:学习有噪图像到无噪图像的映射。
TBD:深度学习方法的难点:成对数据集怎么获得?需要获得同一场景的有噪声和干净的图片,而且是raw图。
3、先前研究的共有认知:在有噪声的raw图上进行去噪,深度学习的性能好于传统方法。
4、现有方法多基于合成数据集去噪,原因是获得成对的数据成本代价极高。
- 长曝光,曝光后还需要后处理抵消相机运动+光线变化;
- 大批量数据;
- 不同相机噪声特性不同,导致构建的数据集泛化性存疑;
5、合成的训练数据对噪声的模拟不够真实,导致深度学习方法性能欠佳。——如何让合成的数据贴近真实?是本文试图解决的问题
- 对 ISP 的步骤建模,从而实现逆操作,实现从 sRGB → RAW 图
- 这篇文章在做 AIISP 的工作!
- 评估指标:对Darmstadt Noise Dataset 中的真实噪声raw图进行评估,我们的模型错误率降低了14%-38%,并且比以前的技术水平快9×-18×
2、Related Work
- 通常对图像噪声的假设:加性高斯白。
- 短曝光图像暗有噪声,长曝光图像明亮基本无噪声。
Amber:真看不懂
3、Raw Image Pipeline
3.1 Shot and Read Noise
- RAW 域噪声分布有规律可循,主要分为两大类:shot noise 和 read noise。shot noise主要和环境光照有关,一般满足泊松分布。 read noise 主要和 sensor 中的电路系统有关, 一般满足高斯分布。
- 对所有的图像强度都有数字增益和模拟增益,增益由相机决定,更准确的说,是‘用户/自动曝光算法’选择的 ISO 光强度的函数。
3.4 White Balance
- 相机记录的图像是照亮场景的灯光的颜色和场景中物体的材质颜色的产物。
- 白平衡会让一些照明弱下来,变得符合人的视觉习惯。
- 具体如何实现呢?估计蓝、红通道增益……没懂(TBD)
- 最朴素的思路:获得数字增益和白平衡增益,然后 rgb图除以增益,实现逆变换。实际实现有更多细节~~~
3.5 Gamma Compression
- 人对图像黑暗区域的渐变更敏感,所以伽马压缩通常用于将更多的动态范围分配给低强度像素。(MARK)
3.6 Tone Mapping
- 高动态范围图像需要极端的色调映射,但即使是标准的低动态范围图像也经常采用s形曲线处理,以匹配胶片的“特征曲线”。
4、Model
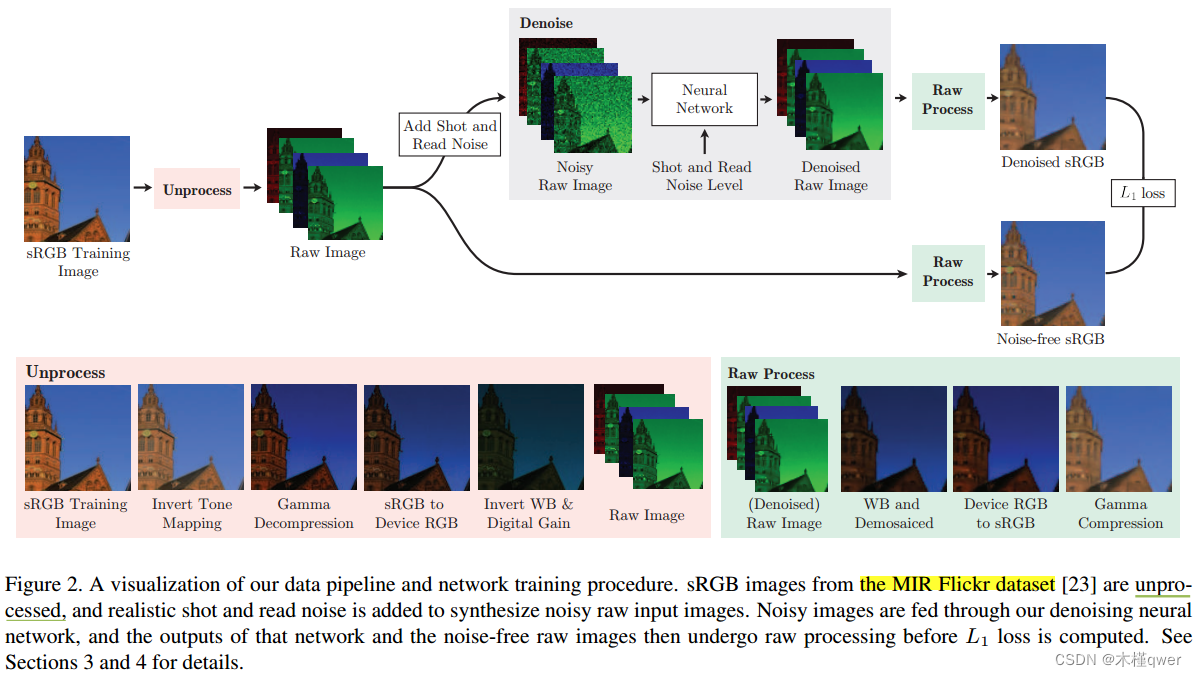
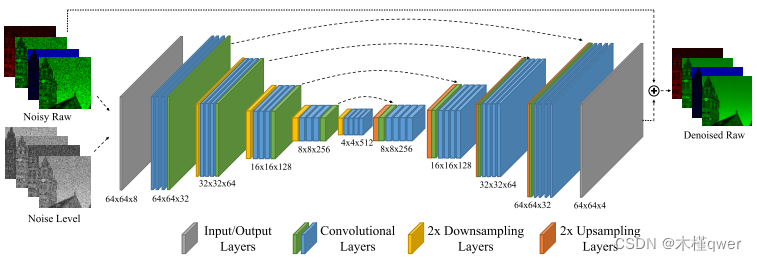
PUZZLE:四通道的噪声级别作为输入,这个噪声级别从哪儿来??
TBD:ablation study 效果看看
1、解决数据构造的问题。数据从哪里来?sRGB → RAW → 训练模型
Amber:所以它生成的数据是接近理想情况的吗?
2、深度学习的模型为什么效果好?
数据构造是关键! 模型是方法,数据是根本,数据和真实场景相似度越高,模型学到的信息越真实效果越好。
3、
读论文的简易做法
1、看有没有网友进行了论文要点提炼,先宏观的了解文章要点。
文章来源:https://blog.csdn.net/lwqian102112/article/details/135100554
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 英飞凌TC3xx之一起认识GTM(十三)详细说说GTM子模块ATOM(通道模式及应用举例: SOMC)
- 【数据结构】归并排序的非递归写法和计数排序
- 聊聊PowerJob的HttpProcessor
- C++用宏实现类成员反射
- 楼宇对讲、可视门铃案例分析
- postman案例
- RAG 详解
- 旧电脑追加内存条
- 【占用网络】OccNet: Scene as Occupancy 适用于检测、分割和规划任务 ICCV2023
- 87 滑动窗口解可获得的最大点数