tessreact训练字库
tessreact主要用于字符识别,除了使用软件自带的中英文识别库,还可以使用Tesseract OCR训练属于自己的字库。
一、软件环境搭建
使用Tesseract OCR训练自己的字库,需要安装Tesseract OCR和jTessBoxEditor(配套训练工具)。jTessBoxEditor需要jdk。要安装jTessBoxEditor之前先安装jdk
安装tessreact OCR:https://blog.csdn.net/u010833154/article/details/135599860
jTessBoxEditor下载地址:https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
获取样本
即需要识别的图片,越多越好;

Merge样本文件
打开jTessBoxEditor,Tools->Merge TIFF,选择图片的格式,然后打开所有样本文件,并将合并文件保存为num.font.exp0.tif
生成box文件
打开命令行并切换至num.font.exp0.tif所在目录,输入以下命令并生成名为num.font.exp0.box的文件。
tesseract num.font.exp0.tif num.font.exp0 batch.nochop makebox
【语法】:tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
lang为语言名称,fontname为字体名称,num为序号;在tesseract中,一定要注意格式。
字符矫正
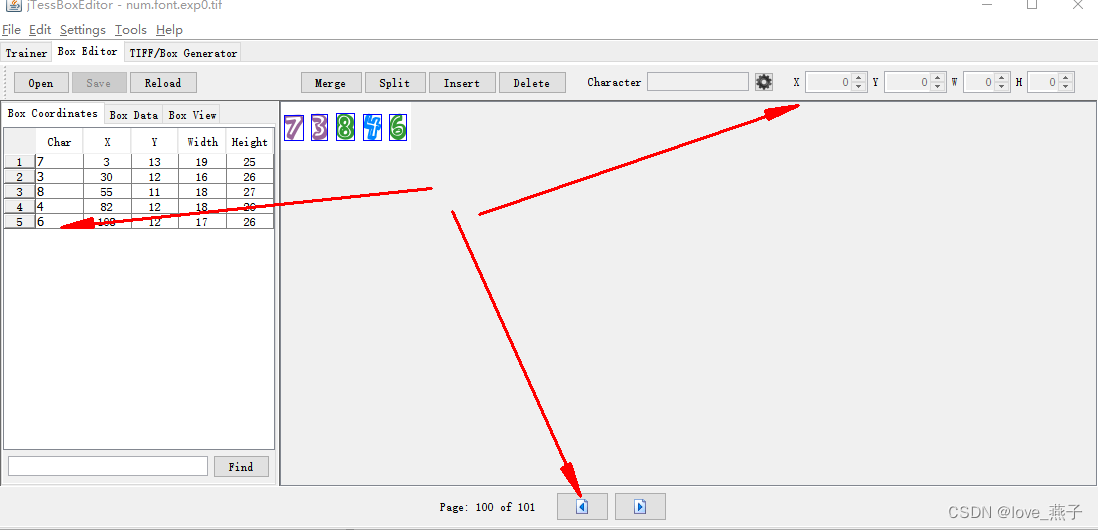
使用jTessBoxEditor—>Box Editor—>open,打开生成的box文件进行字符矫正
定义字符配置文件
在目标文件夹内生成一个名为font_properties.txt的文本文件,内容为
font 0 0 0 0 0
【语法】:< fontname> < italic> < bold> < fixed> < serif> < fraktur>
fontname为字体名称,italic为斜体,bold为黑体字,fixed为默认字体,serif为衬线字体,fraktur德文黑字体,1和0代表有和无,精细区分时可使用。
生成特征文件
echo Run Tesseract for Training..
tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train
echo Compute the Character Set..
unicharset_extractor.exe num.font.exp0.box
mftraining -F font_properties.txt -U unicharset -O num.unicharset num.font.exp0.tr
echo Clustering..
cntraining.exe num.font.exp0.tr
echo Rename Files..
rename normproto num.normproto
rename inttemp num.inttemp
rename pffmtable num.pffmtable
rename shapetable num.shapetable
echo Create Tessdata..
combine_tessdata.exe num.
echo. & pause
测试
将生成的num.traineddata文件放入到Tesseract-OCR下的tessdata文件夹下;
在cmd中进入待识别图片文件夹,执行以下代码:
tesseract test.png output -l num
识别结果就存放在当前文件夹下跌output.txt文件夹下;
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!