python面试pytorch面试
python面试
python中啥类型是不可更改的,啥类型是可以更改的
为什么Python执行速度慢,我们如何改进它?
自己总结:
1c语言属于编译型语言:
它的代码经过编译后再运行,执行速度快;不能跨平台,一般用于操作系统,底层开发;
2c是静态类型语言,在编译期间就确定数据类型的语言,与大多数的静态类型语言一样,在编译过程中就要声明数据类型。
3对象机制不同,c中没有对象这个概念,只有“数据的表示”,比如说如果有两个int变量a和b,可以使用ab来判断,但是如果两个字符串变量a和b,就不得不用strcmp来比较,a与b本质是指向字符串的指针,如果直接使用比较,那比较的实际是指针中存储的值地址。
4c语言分为4类,基本类型(包含整数类型,浮点类型)、枚举类型、void类型、派生类型。
1python属于解释性语言:
它的代码在运行时进行解释,执行速度慢;可以跨平台,适合软件的快速开发;
2python是一种动态类型语言(强类型语言),确定一个变量类型在第一次具体给它赋值的时候。
3对象机制,python中的所有数据,都是由对象或者对象之间的关系表示的,函数是对象,字符串是对象,每个东西都是对象的概念。每一个对象都有三种属性:实体,类型和值。(这个不是太懂)
4Number数字(整数、布尔型、浮点数和复数)、String字符串、List列表、Tuple元组、Sets集合、Dictionary字典
以下是C语言中四类类型的示例代码:
基本类型(包含整数类型,浮点类型):
#include <stdio.h>
int main() {
int num = 10;
float pi = 3.14;
printf("整数类型: %d\n", num);
printf("浮点类型: %f\n", pi);
return 0;
}
枚举类型:
#include <stdio.h>
enum Weekday {Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday};
int main() {
enum Weekday today = Wednesday;
printf("今天是星期:%d\n", today);
return 0;
}
void类型:
#include <stdio.h>
void printMessage() {
printf("这是一个无返回值的函数\n");
}
int main() {
printMessage();
return 0;
}
派生类型(数组类型和结构类型):
#include <stdio.h>
struct Student {
char name[20];
int age;
};
int main() {
int numbers[5] = {1, 2, 3, 4, 5};
struct Student stu = {"John", 20};
printf("数组类型: %d\n", numbers[2]);
printf("结构类型: %s, %d\n", stu.name, stu.age);
return 0;
}
以下是Python中常见数据类型的示例代码:
Number数字(整数、布尔型、浮点数和复数):
num = 10
is_true = True
pi = 3.14
complex_num = 2 + 3j
print("整数类型:", num)
print("布尔类型:", is_true)
print("浮点类型:", pi)
print("复数类型:", complex_num)
String字符串:
str1 = "Hello"
str2 = 'World'
print(str1 + " " + str2)
List列表:
list1 = [1, 2, 3, 4, 5]
list2 = ['apple', 'banana', 'orange']
print(list1)
print(list2)
Tuple元组:
tuple1 = (1, 2, 3, 4, 5)
tuple2 = ('apple', 'banana', 'orange')
print(tuple1)
print(tuple2)
Sets集合:
set1 = {1, 2, 3, 4, 5}
set2 = {'apple', 'banana', 'orange'}
print(set1)
print(set2)
Dictionary字典:
dict1 = {'name': 'John', 'age': 20}
dict2 = {'apple': 1, 'banana': 2, 'orange': 3}
print(dict1)
print(dict2)

字符串是不可变的,即不能修改字符串中的单个字符。
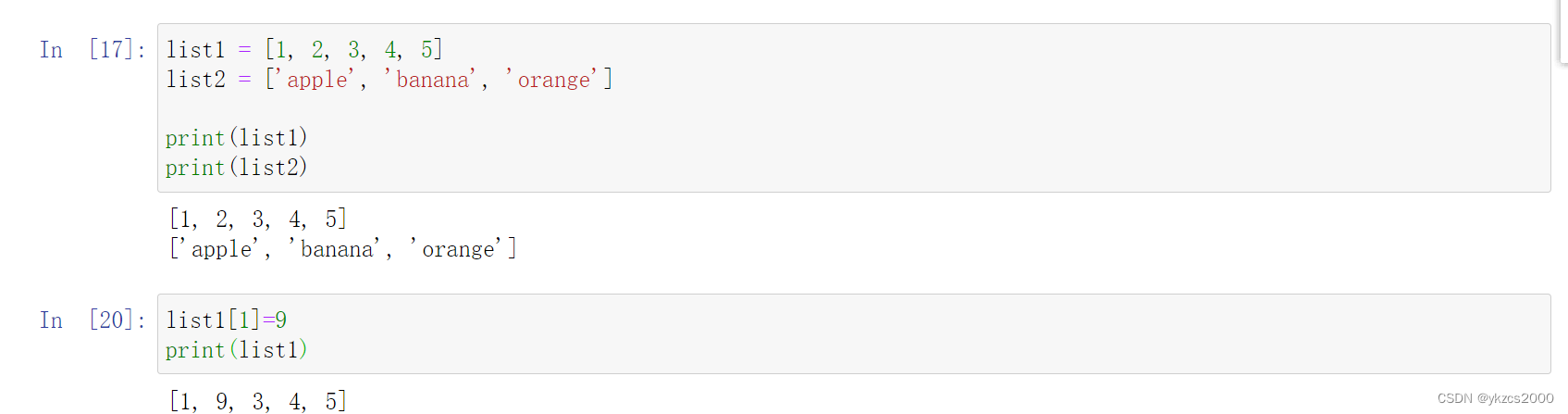
列表是可变的,可以通过索引进行访问、修改、添加、删除等操作。
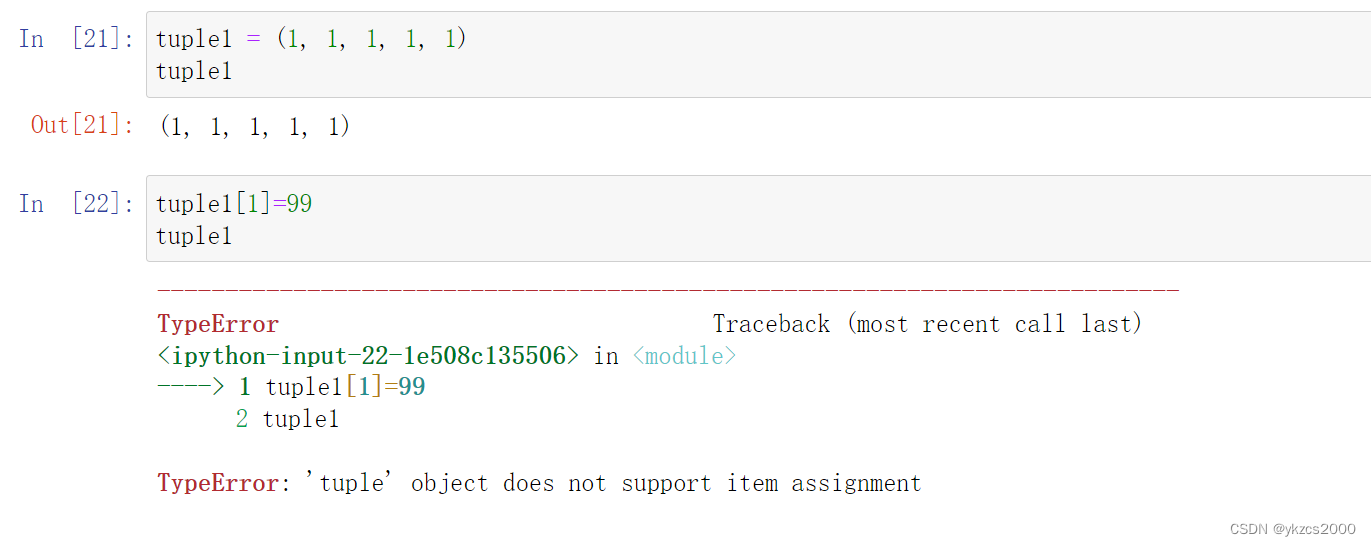
元组不可变

集合也是不可变的。
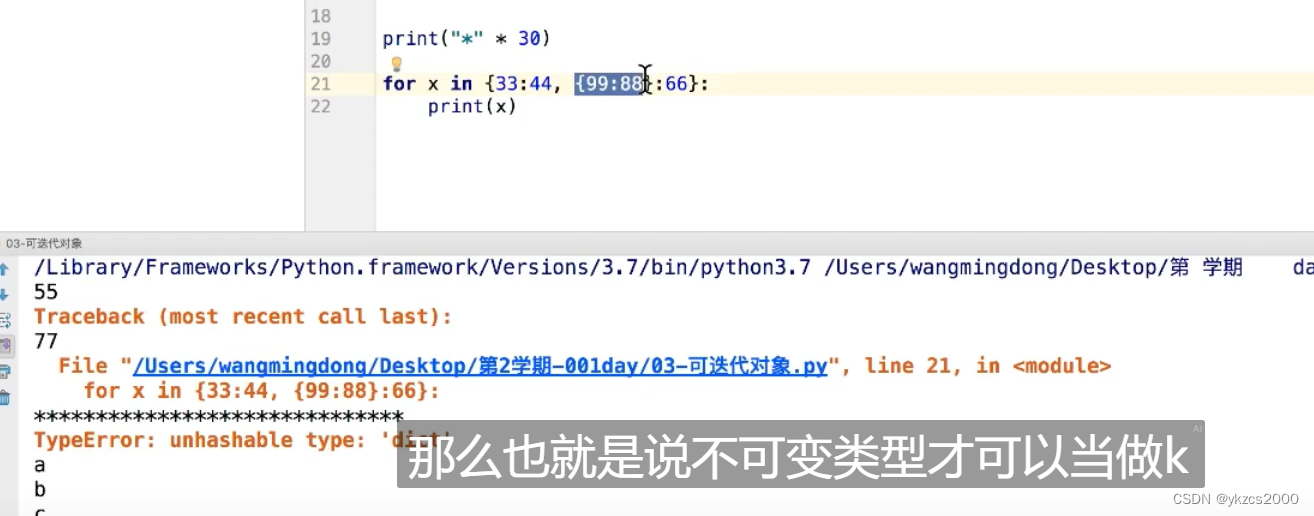
列表与字典不能当作字典的key
迭代器、生成器、装饰器
生成器


尝试:用迭代器来实现,但是次数不确定(这是一个难点);还有生成规律该写如哪个函数,写入next函数。

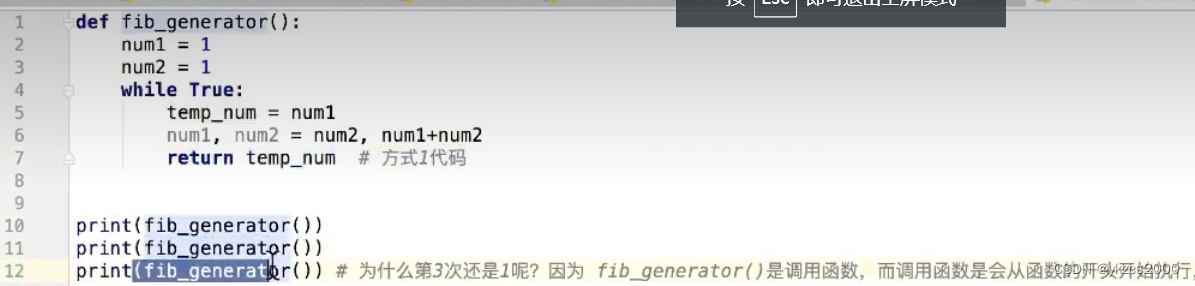
需要属性,属性跟着对象,只要不删除属性,对象还活着,这个值就永远存在,局部变量的话随着方法的结束就变了,就没了。就像上图中的self.x.迭代器还有这个功能,他没有存储想要的数据(下图是给出存储想要的数据),仅仅是存储生成数据的方法,减少空间的浪费,授人以鱼不如授人以渔。

什么是生成器
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。
通俗的理解:
在Python中,这种一边循环一边计算的机制,称为生成器:generator


生成器,其实是一种特殊的迭代器。(可迭代对象不一定是迭代器,迭代器一定是可迭代对象,迭代器不一定是生成器,迭代器根据上一次的生成数我就知道下一次的生成数,生成器(生成器不是记录生成数据的值,而是记录生成数据算法)也属于迭代器)
中括号是列表推导式,小括号是元组推导式
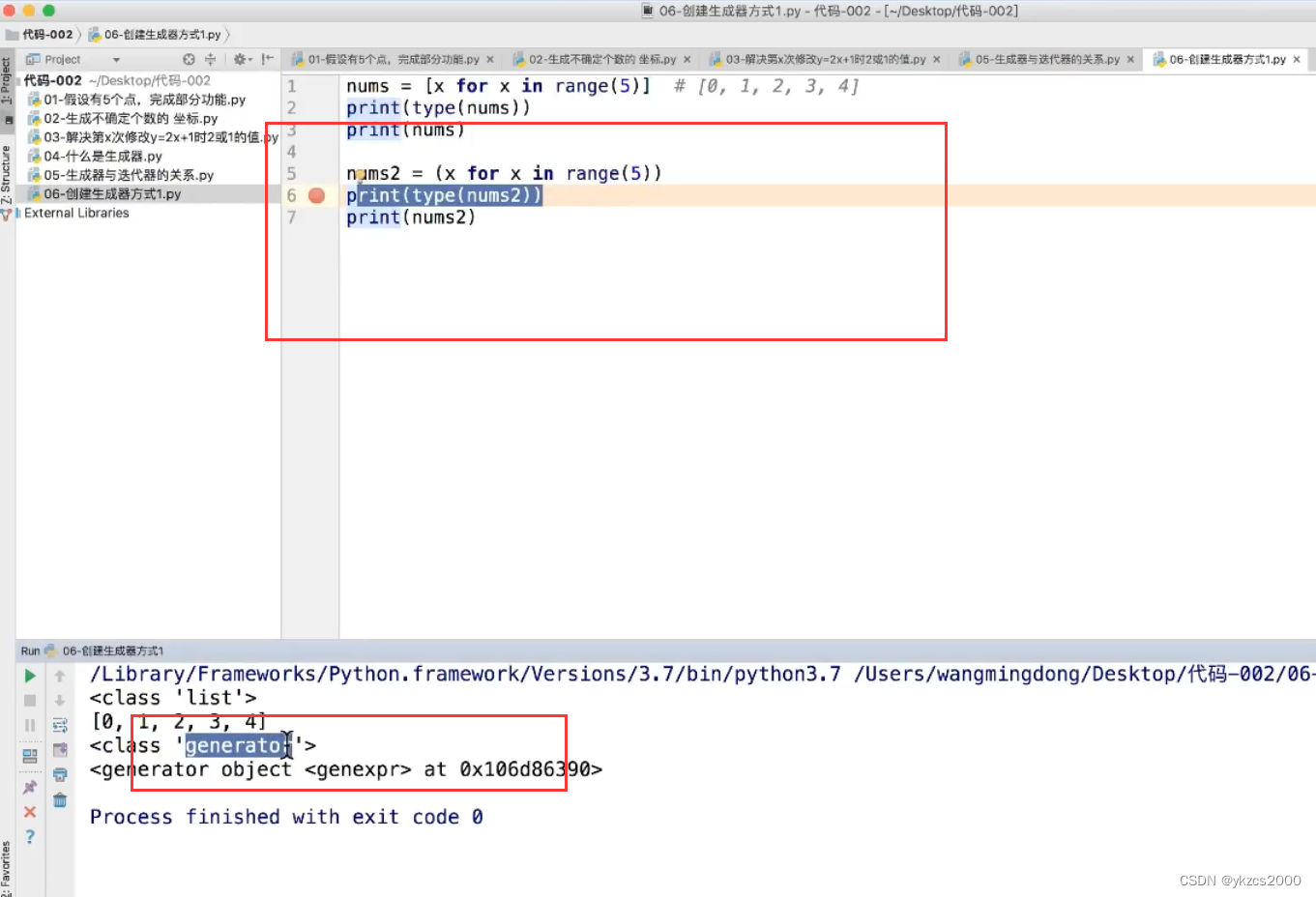
之前创建类,调用对象,打印时候也是像下面哪个一样。
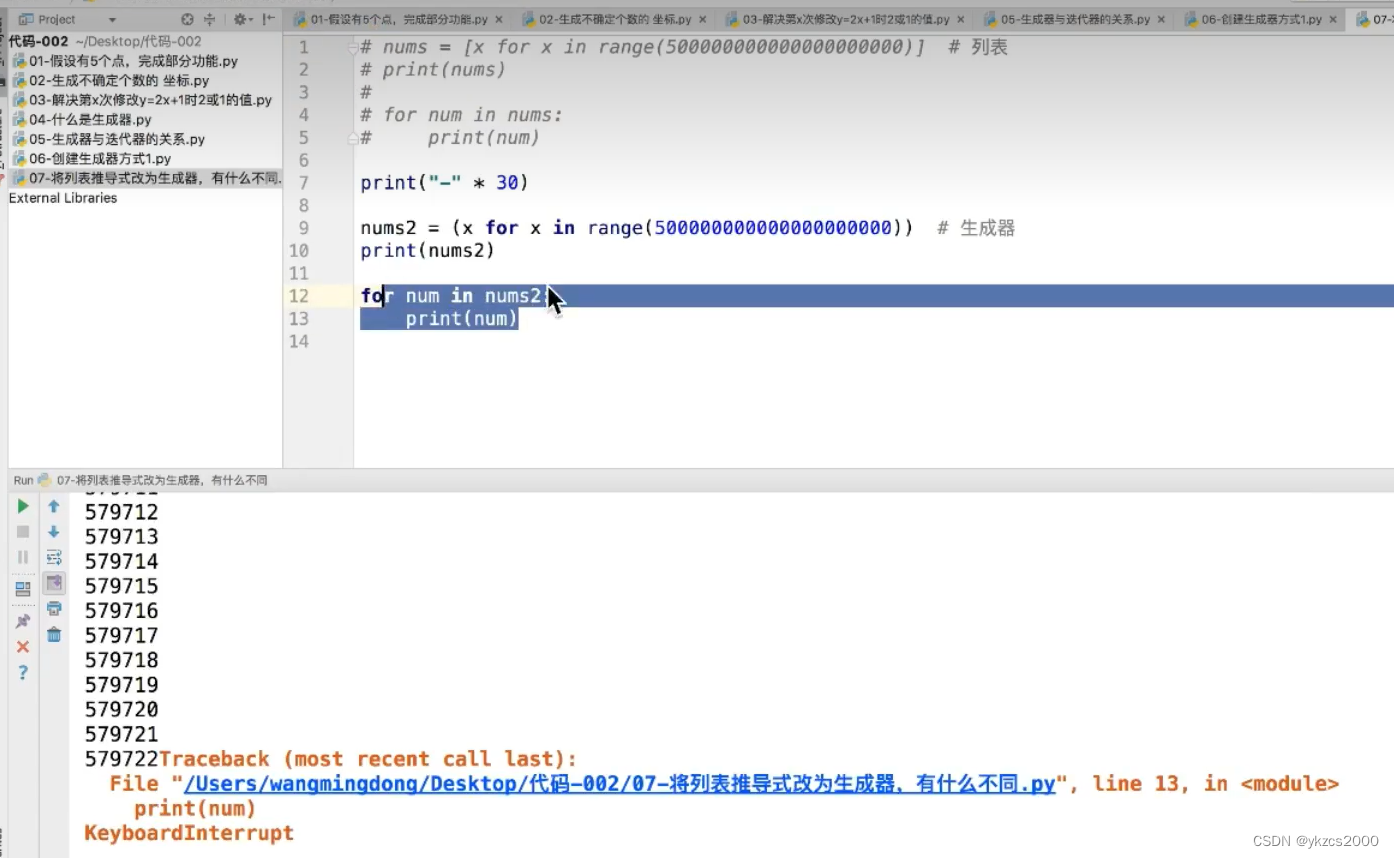
上面那个登录这么长时间没有效果,下面这个就直接好了。列表推导式是必须生成完成之后才可以使用,下面那个不是全部生成才调用,而是什么时候要用什么时候生成。生成器还有一个重要的关键字yield

装饰器:在不修改原函数的实现功能。仅仅是在调函数之前可以额外调用一部分功能。
def make_pencil(color):
def write(content):
print("正在使用(%s)色,写:%s" % (color, content))
return write
black_pencil = make_pencil("黑")
black_pencil("我是喝墨水长大的")
red_pencil = make_pencil("红")
red_pencil("这么巧,我也是,只不过是红墨水")
闭包用到的核心其实就是:在一个函数中返回另外一个函数的引用,只不过这个被返回的函数中用到了其他函数中的变量而已。说到底就是 只要用一个变量指向某个函数代码块,就可以调用它
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!