助力打造清洁环境,基于美团最新YOLOv6-4.0开发构建公共场景下垃圾堆放垃圾桶溢出检测识别系统
公共社区环境生活垃圾基本上是我们每个人每天几乎都无法避免的一个问题,公共环境下垃圾投放点都会有固定的值班时间,但是考虑到实际扔垃圾的无规律性,往往会出现在无人值守的时段内垃圾堆放垃圾桶溢出等问题,有些容易扩散的垃圾比如:碎纸屑、泡沫粒等等,一旦遇上大风天气往往就会被吹得遍地都是给垃圾清理工作带来负担。
本文的主要目的及时想要探索分析通过接入社区实时视频流数据来对公共环境下的垃圾投放点进行自动化的智能分析计算,当探测到异常问题比如:随意堆放垃圾、垃圾桶溢出等问题的时候结合一些人工业务预设的规则来自动通过短信等形式推送事件给相关的工作人员来进行及时的处置这一方案的可行性,博文主要是侧重对检测模型的开发实现,业务规则需要到具体的项目中去细化,这块就不作为文本的实践内容。
在前文中,我们已经陆续开发了相关的实践项目,感兴趣的话可以自行移步阅读即可:
《助力打造清洁环境,基于YOLOv3开发构建公共场景下垃圾堆放垃圾桶溢出检测识别系统》
《助力打造清洁环境,基于YOLOv4开发构建公共场景下垃圾堆放垃圾桶溢出检测识别系统》
《助力打造清洁环境,基于YOLOv5全系列模型【n/s/m/l/x】开发构建公共场景下垃圾堆放垃圾桶溢出检测识别系统》
本文紧接前文系列,主要是想要基于YOLOv6这一经典的模型来开发实践性质的项目,首先看下实例效果:

Yolov6是美团开发的轻量级检测算法,截至目前为止该算法已经迭代到了4.0版本,每一个版本都包含了当时最优秀的检测技巧和最最先进的技术,YOLOv6的Backbone不再使用Cspdarknet,而是转为比Rep更高效的EfficientRep;它的Neck也是基于Rep和PAN搭建了Rep-PAN;而Head则和YOLOX一样,进行了解耦,并且加入了更为高效的结构。YOLOv6也是沿用anchor-free的方式,抛弃了以前基于anchor的方法。除了模型的结构之外,它的数据增强和YOLOv5的保持一致;而标签分配上则是和YOLOX一样,采用了simOTA;并且引入了新的边框回归损失:SIOU。
YOLOv5和YOLOX都是采用多分支的残差结构CSPNet,但是这种结构对于硬件来说并不是很友好。所以为了更加适应GPU设备,在backbone上就引入了ReVGG的结构,并且基于硬件又进行了改良,提出了效率更高的EfficientRep。RepVGG为每一个3×3的卷积添加平行了一个1x1的卷积分支和恒等映射的分支。这种结构就构成了构成一个RepVGG Block。和ResNet不同的是,RepVGG是每一层都添加这种结构,而ResNet是每隔两层或者三层才添加。RepVGG介绍称,通过融合而成的3x3卷积结构,对计算密集型的硬件设备很友好。

简单看下实例数据情况:

训练数据配置文件如下所示:
# Please insure that your custom_dataset are put in same parent dir with YOLOv6_DIR
train: ./dataset/images/train # train images
val: ./dataset/images/test # val images
test: ./dataset/images/test # test images (optional)
# whether it is coco dataset, only coco dataset should be set to True.
is_coco: False
# Classes
nc: 3 # number of classes
# class names
names: ['trash_over', 'garbage', 'trash_no_full']
默认我先选择的是最为轻量级的yolov6n系列的模型,基于finetune来进行模型的开发:
# YOLOv6s model
model = dict(
type='YOLOv6n',
pretrained='weights/yolov6n.pt',
depth_multiple=0.33,
width_multiple=0.25,
backbone=dict(
type='EfficientRep',
num_repeats=[1, 6, 12, 18, 6],
out_channels=[64, 128, 256, 512, 1024],
fuse_P2=True,
cspsppf=True,
),
neck=dict(
type='RepBiFPANNeck',
num_repeats=[12, 12, 12, 12],
out_channels=[256, 128, 128, 256, 256, 512],
),
head=dict(
type='EffiDeHead',
in_channels=[128, 256, 512],
num_layers=3,
begin_indices=24,
anchors=3,
anchors_init=[[10,13, 19,19, 33,23],
[30,61, 59,59, 59,119],
[116,90, 185,185, 373,326]],
out_indices=[17, 20, 23],
strides=[8, 16, 32],
atss_warmup_epoch=0,
iou_type='siou',
use_dfl=False, # set to True if you want to further train with distillation
reg_max=0, # set to 16 if you want to further train with distillation
distill_weight={
'class': 1.0,
'dfl': 1.0,
},
)
)
solver = dict(
optim='SGD',
lr_scheduler='Cosine',
lr0=0.0032,
lrf=0.12,
momentum=0.843,
weight_decay=0.00036,
warmup_epochs=2.0,
warmup_momentum=0.5,
warmup_bias_lr=0.05
)
data_aug = dict(
hsv_h=0.0138,
hsv_s=0.664,
hsv_v=0.464,
degrees=0.373,
translate=0.245,
scale=0.898,
shear=0.602,
flipud=0.00856,
fliplr=0.5,
mosaic=1.0,
mixup=0.243,
)
当然了也可以使用其他几个系列的模型,不同系列模型训练命令如下:
#yolov6n
python3 tools/train.py --batch-size 8 --conf configs/yolov6n_finetune.py --data data/self.yaml --fuse_ab --device 0 --name yolov6n --epochs 100 --workers 2
#yolov6s
python3 tools/train.py --batch-size 16 --conf configs/yolov6s_finetune.py --data data/self.yaml --fuse_ab --device 0 --name yolov6s --epochs 100 --workers 2
#yolov6m
python3 tools/train.py --batch-size 16 --conf configs/yolov6m_finetune.py --data data/self.yaml --fuse_ab --device 0 --name yolov6m --epochs 100 --workers 2
#yolov6l
python3 tools/train.py --batch-size 8 --conf configs/yolov6l_finetune.py --data data/self.yaml --fuse_ab --device 0 --name yolov6l --epochs 100 --workers 2
根据自己的需要选择使用合适的模型即可。
终端执行如下命令即可启动训练:
python3 tools/train.py --batch-size 8 --conf configs/yolov6n_finetune.py --data data/self.yaml --fuse_ab --device 0 --name yolov6n --epochs 100 --workers 2
训练日志输出如下:
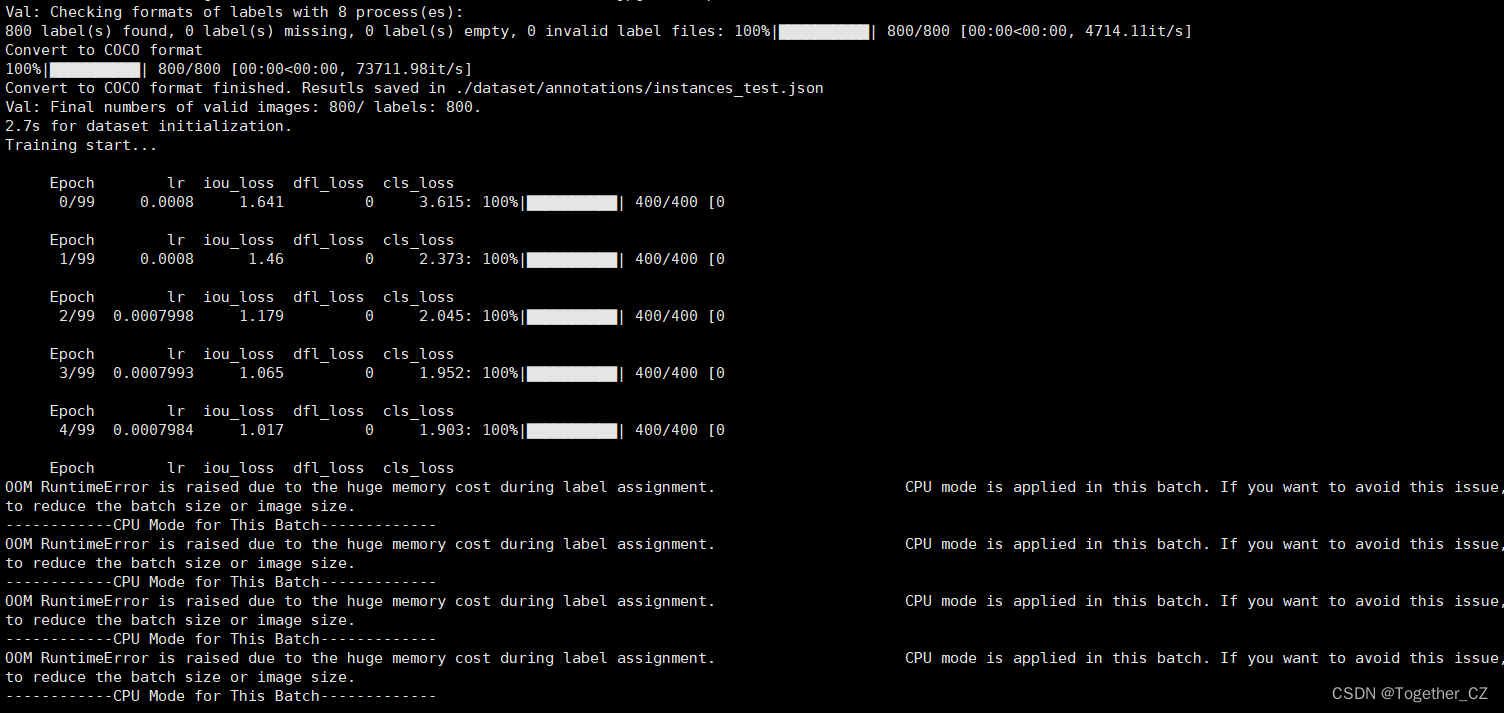



训练完成输出如下所示:
Inferencing model in train datasets.: 100%|?????| 50/50 [00:20<00:00, 2.44it/s]
Evaluating speed.
Evaluating mAP by pycocotools.
Saving runs/train/yolov6n/predictions.json...
Results saved to runs/train/yolov6n
Epoch: 99 | mAP@0.5: 0.8504197493162378 | mAP@0.50:0.95: 0.6347577838061667
Training completed in 5.716 hours.
loading annotations into memory...
Done (t=0.01s)
creating index...
index created!
Loading and preparing results...
DONE (t=0.57s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=5.45s).
Accumulating evaluation results...
DONE (t=0.92s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.635
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.850
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.707
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.183
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.401
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.670
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.420
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.750
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.775
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.489
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.600
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.800
感觉整体yolov6系列的模型使用下来最明显的体验就是对于显存的占用还是比较大的,同等量级的模型训练经常会出现OOM的警告信息。相较于yolov5的n系列模型yolov8的n系列模型,yolov6的n系列模型显然会消耗掉更大的显存资源,虽然官方项目兼容了CPU计算,当显存不足的时候会自动使用CPU来完成计算但是本质还是模型自身资源消耗太大的原因,另外一点就是yolov6的模型训练完成后没有像yolov5、yolov8之类的详细的指标评测信息,只有孤零零的权重文件,不利于学术性质的项目使用,除此之外yolov6模型训练会产生一个很大的记录日志的文件,如下:
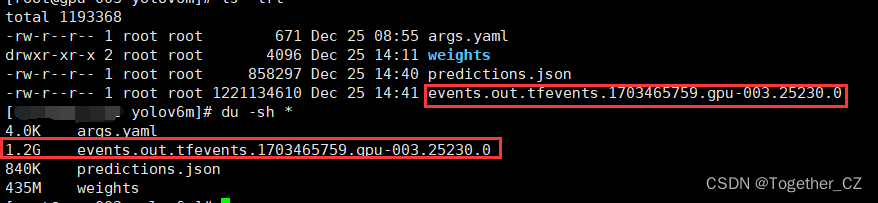
文件实在是太大了,这一点我觉得很理解不了,如果有懂行的欢迎来指导一下。
可能这些不足之处也是导致yolov6始终不温不火的原因吧。
离线推理实例如下所示:



在实际应用开发的时候可以考虑如何更好地基于目标检测模型的检测计算结果来产生业务上的有效事件,这里大都是需要结合业务需求来设定合理有效的规则和预警逻辑的,这里暂时不是本文的重点,感兴趣的话都可以自行动手尝试下!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Nacos持久化配置文件到Mysql(全图文).
- 文件的创建时间可以修改吗,怎么改?
- MyBatis关联查询(三、多对多查询)
- iOS 17.2系统获取IDFA时不弹窗问题
- ROS USB_cam功能包
- 工具系列:TimeGPT_(1)获取token方式和初步使用
- R语言【taxa】——as_taxon():转换为 taxon 对象
- C++小游戏(上)
- 探索Redis特殊数据结构:Stream在实际中的应用
- 数据结构之链表