【总结】Dinky学习笔记
概述
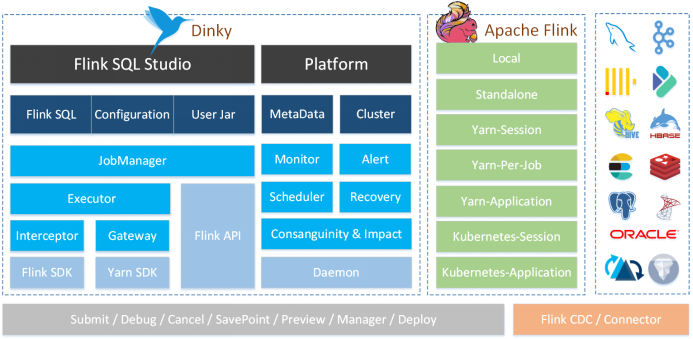
Dinky 是一个开箱即用、易扩展,以 Apache Flink 为基础,连接 OLAP 和数据湖等众多框架的一站式实时计算平台,致力于流批一体和湖仓一体的探索与实践
官网:Dinky
核心特性
- 沉浸式:提供专业的 DataStudio 功能,支持全屏开发、自动提示与补全、语法高亮、语句美化、语法校验、 调试预览结果、全局变量、MetaStore、字段级血缘分析、元数据查询、FlinkSQL 生成等功能
- 易用性:Flink 多种执行模式无感知切换,支持 Flink 多版本切换,自动化托管实时任务、恢复点、报警等, 自定义各种配置,持久化管理的 Flink Catalog
- 增强式:兼容且增强官方 FlinkSQL 语法,如 SQL 表值聚合函数、全局变量、CDC 整库同步、执行环境、 语句合并、共享会话等
- 一站式:提供从 FlinkSQL 开发调试到上线下线的运维监控及 SQL 的查询执行能力,使数仓建设及数据治理一体化
- 易扩展:源码采用 SPI 插件化及各种设计模式支持用户快速扩展新功能,如连接器、数据源、报警方式、 Flink Catalog、CDC 整库同步、自定义 FlinkSQL 语法等
- 无侵入:Spring Boot 轻应用快速部署,不需要在任何 Flink 集群修改源码或添加额外插件,无感知连接和监控Flink 集群
主要功能
- 沉浸式 FlinkSQL 数据开发:自动提示补全、语法高亮、语句美化、在线调试、语法校验、执行计划、MetaStore、血缘分析、版本对比等
- 支持 FlinkSQL 多版本开发及多种执行模式:Local、Standalone、Yarn/Kubernetes Session、Yarn Per-Job、Yarn/Kubernetes Application
- 支持 Apache Flink 生态:Connector、FlinkCDC、Table Store 等
- 支持 FlinkSQL 语法增强:表值聚合函数、全局变量、执行环境、语句合并、整库同步等
- 支持 FlinkCDC 整库实时入仓入湖、多库输出、自动建表、模式演变
- 支持 Flink Java / Scala / Python UDF 开发与自动提交
- 支持 SQL 作业开发:ClickHouse、Doris、Hive、Mysql、Oracle、Phoenix、PostgreSql、Presto、SqlServer、StarRocks 等
- 支持实时在线调试预览 Table、 ChangeLog、统计图和 UDF
- 支持 Flink Catalog、数据源元数据在线查询及管理
- 支持自动托管的 SavePoint/CheckPoint 恢复及触发机制:最近一次、最早一次、指定一次等
- 支持实时任务运维:上线下线、作业信息、集群信息、作业快照、异常信息、数据地图、数据探查、历史版本、报警记录等
- 支持作为多版本 FlinkSQL Server 以及 OpenApi 的能力
- 支持实时作业报警及报警组:钉钉、微信企业号、飞书、邮箱等
- 支持多种资源管理:集群实例、集群配置、Jar、数据源、报警组、报警实例、文档、系统配置等
- 支持企业级管理功能:多租户、用户、角色、命名空间等
安装部署
dinky版本:dlink-release-0.7.3.tar.gz
flink版本:支持的flink版本有flink1.11.0—flink1.17.0

前置条件:已安装flink(当前版本1.13.0)/已安装hadoop(当前版本3.1.3,因为可能使用到yarn模式)
安装步骤:
1.上传安装包并解压到指定目录:tar -zxvf dlink-release-0.7.3.tar.gz -C /opt/module/
2.重命名:mv dlink-release-0.7.3 dinky
3.初始化MySQL数据库(Dinky 采用 mysql 作为后端的存储库,部署需要 MySQL5.7 以上版本):
????????3.1连接到MySQL
????????3.2创建数据库:CREATE DATABASE dinky;
????????3.3创建用户dinky并允许远程登录:create user 'dinky'@'%' IDENTIFIED WITH mysql_native_password by 'dinky';('dinky'@'%'含义是允许远程登录;IDENTIFIED WITH mysql_native_password by 'dinky'含义是设置密码为'dinky'
????????3.4授权给用户dinky:grant ALL PRIVILEGES ON dinky.* to 'dinky'@'%';
? ? ? ? 3.5刷新MySQL的系统权限相关表,使设置生效:flush privileges;
? ? ? ? 3.6登录创建好的dinky用户,切换到dinky数据库并执行初始化sql文件:source /opt/module/dinky/sql/dinky.sql????????
![]()
?
dinky.sql用于初始化;
upgrade目录下存放了各版本的升级sql:

?4.修改配置文件:cd /opt/module/dinky/config,修改application.yml文件,将数据库地址改为:hadoop102:3306,数据库名称、用户名称、密码以及application名称改为dinky:

5.加载依赖:
? ? ? ? 5.1? 加载Flink依赖:Dinky 需要具备自身的 Flink 环境,该 Flink 环境的实现需要用户自己在 Dinky 根目录下:plugins/flink${FLINK_VERSION} 文件夹并上传相关的 Flink 依赖,例如:cp /opt/module/flink-1.13.0/lib/* /opt/module/dinky/plugins/flink1.13
? ? ? ? 5.2? 加载Hadoop依赖:Dinky 当前版本的 yarn 的 perjob 与 application 执行模式依赖 flink-shade-hadoop ,需要额外添加 flink-shade-hadoop-uber-3 包,因此将flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar上传到/opt/module/dinky/plugins目录下
6.上传jar包:使用 Application 模式时,需要将flink和dinky相关的包上传到HDFS
? ? ? ? 6.1? 创建HDFS目录并上传dinky的jar包
hadoop fs -mkdir -p /dinky/jar/
hadoop fs -put /opt/module/dinky/jar/dlink-app-1.13-0.7.3-jar-with-dependencies.jar /dinky/jar
? ? ? ? 6.2? 创建HDFS目录并上传flink的jar包:
hadoop fs -mkdir /flink-dist
hadoop fs -put /opt/module/flink-1.17.0/lib /flink-dist
hadoop fs -put /opt/module/flink-1.17.0/plugins /flink-dist
7.启停命令:进入dinky根目录:cd /opt/module/dinky
? ? ? ? 7.1? 启动:sh auto.sh start 1.13(需要指定版本号),默认端口为8888,web ui地址为:http://hadoop102:8888,默认用户名/密码为:admin/admin

? ? ? ? 7.2??停止:sh auto.sh stop(不需要指定版本号)

? ? ? ? 7.3? 重启:sh auto.sh restart 1.17
8.Flink设置:使用 Application 模式以及 RestAPI 时,需要修改相关Flink配置,将“提交FlinkSQL的Jar文件路径”修改为dlink-app包的路径:

集群注册
提交 FlinkSQL 作业时,首先要保证安装了 Flink 集群。Flink 当前支持的集群模式包括:
- Standalone 集群
- Yarn 集群
- Kubernetes 集群
以上集群的管理可以在Dinky Web UI的注册中心中进行设置:

目前dinky支持的集群类型有:

Flink 实例管理
Flink 实例管理适用于 Standalone,Yarn Session 和 Kubernetes Session这三种集群实例的注册,其他类型的集群只能查看作业信息;
先启动集群,再进行作业提交
1.注册Standalone集群
首先手动启动Standalone集群:
进入Flink根目录下,执行启动命令:bin/start-cluster.sh
集群启动之后在dinky页面点击”新建“,创建新的集群实例:

问题:即使在flink的配置文件
masters中配置了备用的JobManager列表为:
hadoop102:8081,hadoop103:8081这里的JobManager 高可用地址也只能填写
hadoop102:8081或者hadoop103:8081,而不能同时填写两个JobManager
创建完成后可以看到注册的集群状态正常:

点击FlinkWebUI可以进入flink的web UI界面:

(此时没有作业在运行)
2.注册Yarn Session集群
首先需要手动启动Yarn Session集群:
进入Flink的根目录下,执行:bin/yarn-session.sh -nm test
启动完成后可以看到JobManager的地址:

在浏览器中打开hadoop103:8088,可以看到当前已启动的一个application:

接下来在dinky中创建Yarn Session类型的集群:

这里的JobManager高可用地址即使填写错误也会自动修正
创建完成后可以看到集群状态正常:

集群配置管理
集群配置管理适用于 Yarn Per-job、Yarn Application 和 Kubernetes Application 这三种类型配置
点击创建集群,首先填写主要配置:

- 类型选择Flink On Yarn;
- Hadoop配置文件路径一般为:
${hadoop安装根目录}/etc/hadoop - ha.zookeeper.quorum即高可用配置,zookeeper的地址
- lib路径为相应版本的Flink lib内容,但需要提前上传至hdfs上
- Flink配置文件路径一般为:
${flink安装根目录}/conf
然后可以配置一些参数:
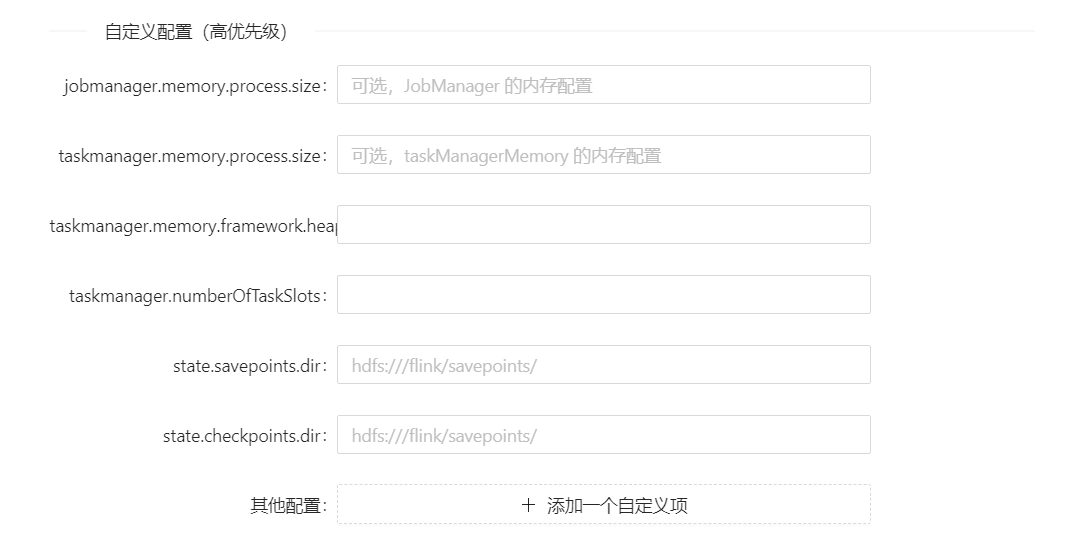
其优先级高于flink-conf.yaml文件中配置的参数;
最后填写基本配置信息:

点击”测试“按钮,测试链接成功后即可创建:

列表中即可看到可用的集群配置:

作业提交运行
案例内容:在dinky中创建FlinkSQL作业,编写SQL语句并提交到不同的集群中去运行
创建作业
首先在”数据开发“面板创建目录:

然后右键单击目录选择创建作业:

作业类型有很多种,这里选择FlinkSQL:

这里"别名"是必选项,可以填写中文
作业创建完成后可用看到代码编写及控制台界面:

配置信息
官网链接:作业基础配置 | Dinky
作业配置

(1)执行模式:可选项如下

(2)Flink集群配置:当执行模式不选择Local时会出现该配置
比如说执行模式选择Standalone,在集群配置中可以看到之前创建的Flink实例信息:

(3)FlinkSQL环境:选择当前任务的 FlinkSQL 执行环境,会提前执行环境语句,默认无

(4)其他信息:

Insert语句集:【增强特性】 开启语句集机制,将把多个 Insert 语句合成一个 JobGraph 再进行提交,Select 语句无效
执行配置

(1)预览结果:开启预览结果,将同步运行并返回数据结果

(2)打印流:开启打印流,将同步运行并返回含有 op 信息的 ChangeLog,默认不开启且返回最终结果 Table

(3)最大行数:设置table展示的预览数据的最大行数
(4)自动停止:数据达到最大行数后自动停止
提交运行
Flink SQL语句如下:
--创建源表 source
CREATE TABLE source(
id BIGINT,
name STRING
) WITH (
'connector' = 'datagen'
);
--创建结果表 sink
CREATE TABLE sink(
id BIGINT,
name STRING
) WITH (
'connector' = 'print'
);
--将源表数据插入到结果表
INSERT INTO sink
SELECT
id ,
name
from source;Local模式
点击"执行当前sql",在结果中可以看到数据:

Standalone模式

注意:切换执行模式之后必须先ctrl+s保存再点击"提交作业到集群",否则会将作业提交到上一次选择的集群中
然后到"运维中心"中可以看到正在运行中的任务:

点击进入该任务可以看到更多详细信息:

点击右上角FlinkWebUI可以进入Flink面板:


在Flink面板中点击找到TaskManager运行的机器,可以查看相应的日志信息:

点击Log,在stdout中可以看到相应的数据(前提是在【执行配置】中开启了【打印流】):

回到dinky的运维面板,在右上角可以选择对当前任务能够执行的操作:

但如果选择与SavePoint相关的操作必须提前配置,否则会报错;

(如果点击智能停止默认执行SavePoint停止)
如果没有配置SavePoint直接选择"普通停止"即可;
如下则作业已经成功停止:

Yarn Session模式

同样可以成功将作业提交到集群运行:

(其余内容和standalone模式完全一样)
Yarn Application模式

其余操作和standalone模式基本一致;
在使用该模式时出现了"异步提交失败"的情况,报错信息如下:
Caused by: java.io.IOException: Cannot find any jar files for plugin in directory [plugins/flink1.11]. Please provide the jar files for the plugin or delete the directory.

提示说在plugins/flink1.11这个文件夹中找不到相应的插件,回顾在"集群配置管理"中设置的集群配置,发现确实没有plugins相关的配置,推测该版本的dinky可能没有能够按照版本号来扫描对应的plugins文件夹从而选取合适的依赖,而是依次扫描plugins文件夹下所有目录:

从而导致虽然启动的版本是flink1.13,但使用的jar包是flink1.11的,因此按照提示删除flink1.11目录下所有内容,发现报错信息有所改变:

所以把除了flink1.13之外的目录全部删除即可
修改问题后作业可以正常提交:

(由于是提交作业时创建集群,因此作业提交速度会比较慢)
重要功能
1.持久化Catalog
dinky自己实现了 mysql-catalog,作用同 hive-catalog,可以持久化Flink元数据,在作业中无需再显式声明 DDL 语句
选择Catalog
在【作业配置】——【FlinkSQL环境】中选择:

默认提供了一个DefaultCatalog
需要注意这个DefaultCatalog和Flink内存中的Catalog并不一样;如果选择【FlinkSQL环境】为"无"才是使用Flink内存的Catalog;
查看Catalog
在左侧的【结构】目录中可以查看:

其中的my_catalog是dinky自己实现的mysql-catalog,而default_catalog是Flink内存中的Catalog
选择my_catalog下的默认数据库,可以看到已经创建的表:

右键单击对应的表可以查看表结构:

也可以通过show tables语句查看已有的表:

此时如果再次执行建表DDL,则会报错;
2.使用变量
定义变量
变量定义的语法为:key1 := value1;
例如:
var1:=source;
--创建源表 source
CREATE TABLE ${var1}(
id BIGINT,
name STRING
) WITH (
'connector' = 'datagen'
);
select * from ${var1};使用自定义的变量时需要开启【全局变量】:

否则在进行SQL检查时会报错;
执行上述SQL,结果如下:

变量定义正常生效;
查看变量
查看变量语法如下:
-- 查看所有变量
SHOW FRAGMENTS;
-- 查看单个变量
SHOW FRAGMENT var2;执行以下语句:
var1:=source;
SHOW FRAGMENTS;可以查看到所有的变量名称(但看不到变量的值):

执行以下语句:
var1:=source;
SHOW FRAGMENTS var1;才可以查看到变量var1的值:

全局使用变量
全局变量注册
上述方式定义的变量只适用于当前作业,所以如果想要在多个作业中使用同一个变量,需要将其注册为全局变量;
在【注册中心】—【全局变量管理】中进行注册:

注册成功后即可在作业中使用:

在FlinkSQLEnv中定义变量
dinky可以将FlinkSQL 封装为执行环境,供FlinkSQL任务使用,即为FlinkSQLEnv;也就是说在执行FlinkSQL任务之前先执行FlinkSQLEnv中的语句;
FlinkSQLEnv 场景适用于所有作业的SET、DDL语法统一管理的场景,当前FlinkSQLEnv 在SQL编辑器的语句限制在1000行以内
首先需要新建一个环境(和创建新作业流程相同,在类型中选择FlinkSQLEnv):

在环境中新建变量var3:

然后在作业中选中环境,即可使用其中定义的变量:

连接配置变量
连接配置变量一般用于设置一些数据源的配置信息,例如MySQL的主机名、端口号、用户名以及密码等等;
使用步骤如下:
1.创建数据源
【注册中心】—【数据源管理】—【新建】—【选择数据源】

这里选择MySQL数据源,首先输入基本信息:

然后设置Flink连接配置:

(作为一个变量值来使用)
接下来设置Flink连接模板(即自动生成建表语句的模板):

'connector' = 'mysql-cdc'
,${mysql102}
,'scan.incremental.snapshot.enabled' = 'true'
,'debezium.snapshot.mode'='latest-offset'
,'database-name' = '${schemaName}'
,'table-name' = '${tableName}'
- connector:Flink连接器,指定使用MySQL CDC连接器
- ${mysql102}:占位符,表示需要提供的MySQL的连接信息(即上面设置的Flink连接配置变量值)
- scan.incremental.snapshot.enabled = 'true':启用增量快照扫描功能,即只扫描自上次扫描以来发生变化的数据
- debezium.snapshot.mode='latest-offset':设置快照模式为“最新偏移量”,即从最新的数据偏移量开始扫描
- ${schemaName} :动态获取数据库
- ${tableName}:动态获取表名称
信息填写完毕后进行测试链接,然后保存即可:

2.数据源访问
在【元数据中心】中点击对应的数据源即可查看相关信息:
在【描述】部分可以看到字段信息和表信息:

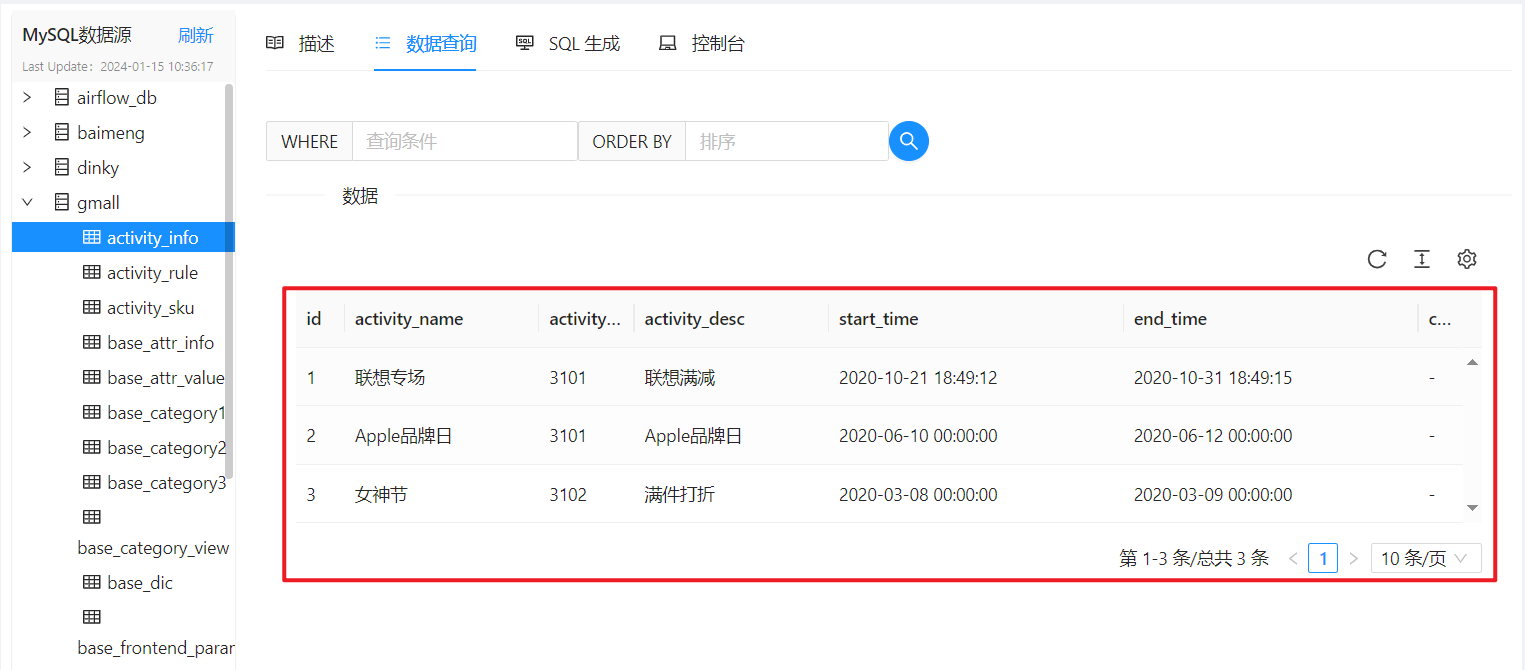
在【数据查询】部分可以看到表中的数据:
在【SQL生成】部分可以自动生成建表语句:

【FlinkDDL】即Flink语法的DDL语句,示例:
DROP TABLE IF EXISTS activity_info;
CREATE TABLE IF NOT EXISTS activity_info (
`id` BIGINT NOT NULL COMMENT '活动id'
,`activity_name` STRING COMMENT '活动名称'
,`activity_type` STRING COMMENT '活动类型(1:满减,2:折扣)'
,`activity_desc` STRING COMMENT '活动描述'
,`start_time` TIMESTAMP COMMENT '开始时间'
,`end_time` TIMESTAMP COMMENT '结束时间'
,`create_time` TIMESTAMP COMMENT '创建时间'
,PRIMARY KEY ( `id` ) NOT ENFORCED
) COMMENT '活动表'
WITH (
'connector' = 'mysql-cdc'
,${mysql102}
,'scan.incremental.snapshot.enabled' = 'true'
,'debezium.snapshot.mode'='latest-offset'
,'database-name' = 'gmall'
,'table-name' = 'activity_info'
);可以看到我们创建数据源时填写的Flink连接模板被拼接到建表语句的WITH语法中;
【SELECT】即查询语法:

【SQLDDL】即MySQL语法的DDL语句:

3.建表语句使用
复制【FlinkSQL】中生成的建表语句到作业中,然后开启【全局变量】:

点击【检查当前SQL】,可以看到配置信息已经导入进来:

3.ADD JAR
ADD JAR 语句用于将用户 jar 添加到 classpath;可作用于standalone、session和 application 模式
当连接器和第三方依赖过多时,经常容易导致 jar依赖冲突,ADD JAR可以选择性的识别添加到服务器,做到环境隔离
使用语法:ADD JAR '<path_to_filename>.jar'(与sql-client一致,参考:https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/table/sql/jar/)
示例:通过ADD JAR的方式添加mysql-cdc的jar包:
首先将flink-sql-connector-mysql-cdc-2.3.0.jar上传至hadoop102的/opt/software/jars路径下,
然后即可在作业中通过ADD JAR语法来将jar包导入到当前作业环境中:
add jar '/opt/software/jars/flink-sql-connector-mysql-cdc-2.3.0.jar'接下来即可执行连接器为mysql-cdc的Flink SQL,完整语句如下:
add jar '/opt/software/jars/flink-sql-connector-mysql-cdc-2.3.0.jar';
--数据源中自动生成的建表语句
DROP TABLE IF EXISTS activity_info;
CREATE TABLE IF NOT EXISTS activity_info (
`id` BIGINT NOT NULL COMMENT '活动id'
,`activity_name` STRING COMMENT '活动名称'
,`activity_type` STRING COMMENT '活动类型(1:满减,2:折扣)'
,`activity_desc` STRING COMMENT '活动描述'
,`start_time` TIMESTAMP COMMENT '开始时间'
,`end_time` TIMESTAMP COMMENT '结束时间'
,`create_time` TIMESTAMP COMMENT '创建时间'
,`operate_time` TIMESTAMP COMMENT '修改时间'
,PRIMARY KEY ( `id` ) NOT ENFORCED
) COMMENT '活动表'
WITH (
'connector' = 'mysql-cdc'
,${mysql102}
,'scan.incremental.snapshot.enabled' = 'true'
,'debezium.snapshot.mode'='latest-offset'
,'database-name' = 'gmall'
,'table-name' = 'activity_info'
);
CREATE TABLE print
WITH (
'connector' = 'print'
)
LIKE activity_info (EXCLUDING ALL);
insert into print select * from activity_info;这里的LIKE activity_info (EXCLUDING ALL);是Flink SQL的语法,意为创建一个与activity_info表结构一样的表,并且通过EXCLUDING语法来选择WITH中的配置项进行排除,EXCLUDING ALL即为排除所有配置选项;
执行结果如下(Web UI中的stdout):

中文乱码是由于yarn配置的原因
4.CDCSOURCE 整库同步
目前通过 FlinkCDC 进行整库同步会因为每张表都需要占用一个source,导致占用大量的数据库连接,对 Mysql 和网络造成压力
因此Dinky 定义了 CDCSOURCE 整库同步的语法,可以直接自动构建一个整库入仓入湖的实时任务,并且对 source 进行了合并,不会产生额外的 Mysql 及网络压力
具体采用的方法是只构建一个 source,然后根据 schema、database、table 进行分流处理,分别 sink 到对应的表
CDCSOURCE 语句用于将上游指定数据库的所有表的数据采用一个任务同步到下游系统;整库同步默认支持 Standalone、Yarn Session、Yarn Per job、K8s Session
使用语法
EXECUTE CDCSOURCE jobname
WITH ( key1=val1, key2=val2, ...)WITH 参数通常用于指定 CDCSOURCE 所需参数
常用参数如下:
| 配置项 | 是否必须 | 默认值 | 说明 |
| connector | 是 | 无 | 指定要使用的连接器,当前支持 mysql-cdc 及 oracle-cdc |
| hostname | 是 | 无 | 数据库服务器的 IP 地址或主机名 |
| port | 是 | 无 | 数据库服务器的端口号 |
| username | 是 | 无 | 连接到数据库服务器时要使用的数据库的用户名 |
| password | 是 | 无 | 连接到数据库服务器时要使用的数据库的密码 |
| scan.startup.mode | 否 | latest-offset | 消费者的可选启动模式,有效枚举为“initial”和“latest-offset” |
| database-name | 否 | 无 | 如果table-name="test\.student,test\.score",此参数可选。 |
| table-name | 否 | 无 | 支持正则,示例:"test\.student,test\.score" |
| source.* | 否 | 无 | 指定个性化的 CDC 配置,如 source.server-time-zone 即为 server-time-zone 配置参数。 |
| checkpoint | 否 | 无 | 单位 ms |
| parallelism | 否 | 无 | 任务并行度 |
| sink.connector | 是 | 无 | 指定 sink 的类型,如 datastream-kafka、datastream-doris、datastream-hudi、kafka、doris、hudi、jdbc 等等,以 datastream- 开头的为 DataStream 的实现方式 |
| sink.sink.db | 否 | 无 | 目标数据源的库名,不指定时默认使用源数据源的库名 |
| sink.table.prefix | 否 | 无 | 目标表的表名前缀,如 ODS 即为所有的表名前拼接 ODS |
| sink.table.suffix | 否 | 无 | 目标表的表名后缀 |
| sink.table.upper | 否 | 无 | 目标表的表名全大写 |
| sink.table.lower | 否 | 无 | 目标表的表名全小写 |
| sink.* | 否 | 无 | 目标数据源的配置信息,同 FlinkSQL,使用 ${schemaName} 和 ${tableName} 可注入经过处理的源表名 |
| sink[N].* | 否 | 无 | N代表为多目的地写入, 默认从0开始到N, 其他配置参数信息参考sink.*的配置. |
Flink CDC 和 Kafka 进行多源合并
环境配置
(1)启动kafka
(2)向Flink添加Dinky依赖:
将dinky根目录lib文件夹下的dlink-common-0.7.3.jar、dlink-client-base-0.7.3.jar以及plugins/filink1.13/dinky文件夹下的dlink-client-1.13-0.7.3.jar拷贝到flink的lib文件夹下:
cp /opt/module/dinky/lib/dlink-common-0.7.3.jar /opt/module/flink-1.13.0/lib/
cp /opt/module/dinky/lib/dlink-client-base-0.7.3.jar /opt/module/flink-1.13.0/lib/
cp /opt/module/dinky/plugins/flink1.13/dinky/dlink-client-1.13-0.7.3.jar /opt/module/flink-1.13.0/lib/拷贝成功:

(3)添加连接器依赖(Dinky和Flink都需要添加):flink-sql-connector-mysql-cdc-2.3.0.jar以及flink-sql-connector-kafka-1.17.0.jar
cp /opt/software/jars/flink-sql-connector-mysql-cdc-2.3.0.jar /opt/module/flink-1.13.0/lib
cp /opt/software/jars/flink-sql-connector-mysql-cdc-2.3.0.jar /opt/module/dinky/plugins
cp /opt/software/jars/flink-sql-connector-kafka-1.13.0.jar /opt/module/flink-1.13.0/lib
cp /opt/software/jars/flink-sql-connector-kafka-1.13.0.jar /opt/module/dinky/plugins/flink1.13(4)重启Yarn-Session集群:
Session和Standalone这种需要事先启动集群的模式,依赖发生改变,需要重启集群才能生效
(5)重启dinky
实时数据合并至一个Kafka Topic
执行SQL:
EXECUTE CDCSOURCE cdc1 WITH (
'connector' = 'mysql-cdc',
'hostname' = 'hadoop102',
'port' = '3306',
'username' = 'root',
'password' = 'hadoop',
'checkpoint' = '3000',
'scan.startup.mode' = 'initial',
'parallelism' = '1',
'table-name' = 'gmall\.activity_info,gmall\.activity_rule',
'sink.connector'='datastream-kafka',
'sink.topic'='dlinkcdc',
'sink.properties.transaction.timeout.ms'='60000',
'sink.brokers'='hadoop102:9092'
);注意:sinkProducer的超时时间默认为1个小时,但是kafka broker的超时时间默认是15分钟,kafka broker不允许sinkProducer的超时时间比他大,同时sinkProducer的超时时间要比checkpoint间隔大,否则会报错;
这里kafka broker的超时时间默认为15min;checkpoint的间隔为3s,因此将sinkProducer的超时时间设置为60s是合理的
在作业中提交,可以看到只有一个source:

在kafka中查看list:kafka-topics.sh --bootstrap-server hadoop102:9092 --list
可以看到新建的topic——dlinkcdc

在kafka中消费该topic:bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic dlinkcdc(消费全部数据)
可以看到数据已经成功同步:

修改其中一条数据【联想专场】为【联想专场test】,可以看到数据已经同步更新:

实时数据合并至对应Kafka Topic
不指定sink.topic,就是写入对应的Topic:
EXECUTE CDCSOURCE cdc1 WITH (
'connector' = 'mysql-cdc',
'hostname' = 'hadoop102',
'port' = '3306',
'username' = 'root',
'password' = 'hadoop',
'checkpoint' = '3000',
'scan.startup.mode' = 'initial',
'parallelism' = '1',
'table-name' = 'gmall\.activity_info,gmall\.activity_rule',
'sink.connector'='datastream-kafka',
'sink.properties.transaction.timeout.ms'='60000',
'sink.brokers'='hadoop102:9092'
);然后提交到集群运行,在Web UI中可以看到一个source对应两个sink:

然后查看kafka中的topic,可以看到每一张表对应一个topic:

此时可以单独消费某一张表中的数据;
有关如何实现Flink CDC 和 Kafka 的多源合并以及下游同步更新可以参考:
Flink CDC 和 Kafka 多源合并 | Dinky
5.UDF开发
新建UDF
(1)配置模板:在【配置中心】—【UDF模板配置】中:

(2)可以通过新建作业的形式创建UDF:

填写相关信息后成功创建作业:

在作业中注册UDF
新建Flink SQL作业:
通过create temporary function HashFunction as 'com.why.udf.HashFunction';将自定义的UDF注册到当前作业中,然后就可以在SQL中使用:
create temporary function HashFunction as 'com.why.udf.HashFunction';
CREATE TABLE sourceTable (
id int
) WITH (
'connector' = 'datagen'
);
CREATE TABLE sinkTable
WITH (
'connector' = 'print'
)
LIKE sourceTable (EXCLUDING ALL);
insert into sinkTable select HashFunction(id) from sourceTable;在Web UI中可以成功看到stdout信息:

0.7.3版本的dinky的UDF功能对于Flink1.16.0以上版本还不支持,因为从Flink1.16开始引入了用户类加载器,需要使用用户类加载器。未来版本0.8.0已经支持Flink1.16以上版本(详见:https://github.com/DataLinkDC/dinky/pull/1581)
6.用户管理
创建用户
在【认证中心】—【用户管理】中新建用户:

默认密码为123456
用户新建完成后需要绑定租户,否则登录会报错:

在【租户管理】中将用户分配到相应的租户中:

然后用户就可以登录了
登录成功后无法打开【认证中心】界面:

这是因为只有admin用户才能够进入【认证中心】界面,但该用户使用其他界面不受影响
当前版本(0.7.3)的dinky暂不支持【角色数据权限】和【命名空间管理】:

修改密码

如果忘记之前的密码,可以直接修改MySQL中的dlink_user表,密码是md5加密存储,直接用md5(新密码)的值,修改表里密码字段的值
7.报警管理
在0.6版本以后,用户可以创建报警实例及报警组,监控 FlinkSQL 作业;
一个报警组可以使用多个报警实例,用户就可以进一步收到报警通知;收到的报警通知类型如下:
- unknown
- stop
- cancel
- finished
目前Dinky支持的报警插件有:
- 钉钉告警 : WebHook
- 企业微信告警 : 包含应用+群聊
- 飞书告警 : WebHook
- 邮箱告警 : 通过邮件发送报警通知
邮箱告警实例
首先需要准备两个邮箱,一个邮箱用来发送告警信息,另一个用来接收信息;
1.开启POP3/SMTP服务
用于发送告警信息的邮箱需要POP3/SMTP服务,我这里使用的是网易邮箱:

开启成功后会出现一个授权码,一定要保存下来,后面要用;
2.新建报警实例
在【注册中心】—【报警管理】中新建报警实例:
填写基本信息:

邮件服务器地址如下:
POP3服务器: pop.163.com
端口号:110
SMTP服务器: smtp.163.com
端口号:25
IMAP服务器: imap.163.com
端口号:143
这里我是用的是SMTP服务器,端口号为25(这里的"收件人"其实应该填写端口号,placeholder有提示的)
开启邮箱验证:
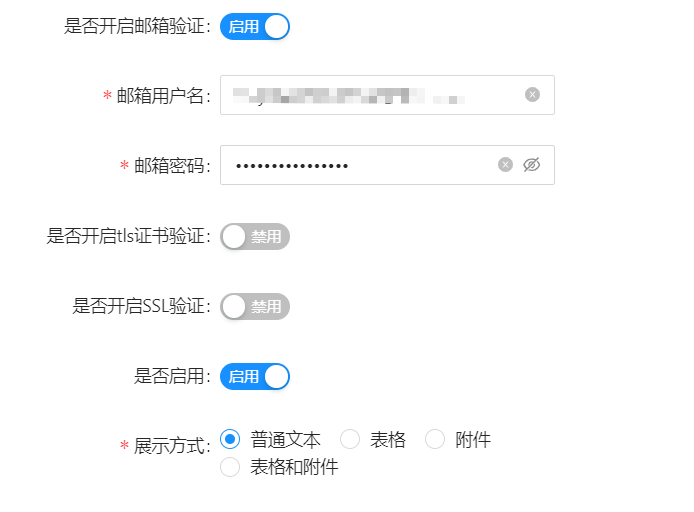
这里的邮箱即为发送告警信息的邮箱,密码为上面开通POP3/STMP服务提供的设备授权码
展示方式根据个人喜好填写即可
然后点击测试,会向收件人邮箱发送一封邮件内容如下:

测试通过后保存即可
3.新建报警组

报警实例需要添加到报警组中才可生效;
4.作业配置指定报警组
在【数据开发】—【作业配置】中选择告警组:

保存后点击【发布】:

发布后点击【上线】(上线后告警才能生效):

在【运维中心】中可以看到作业已经上线:

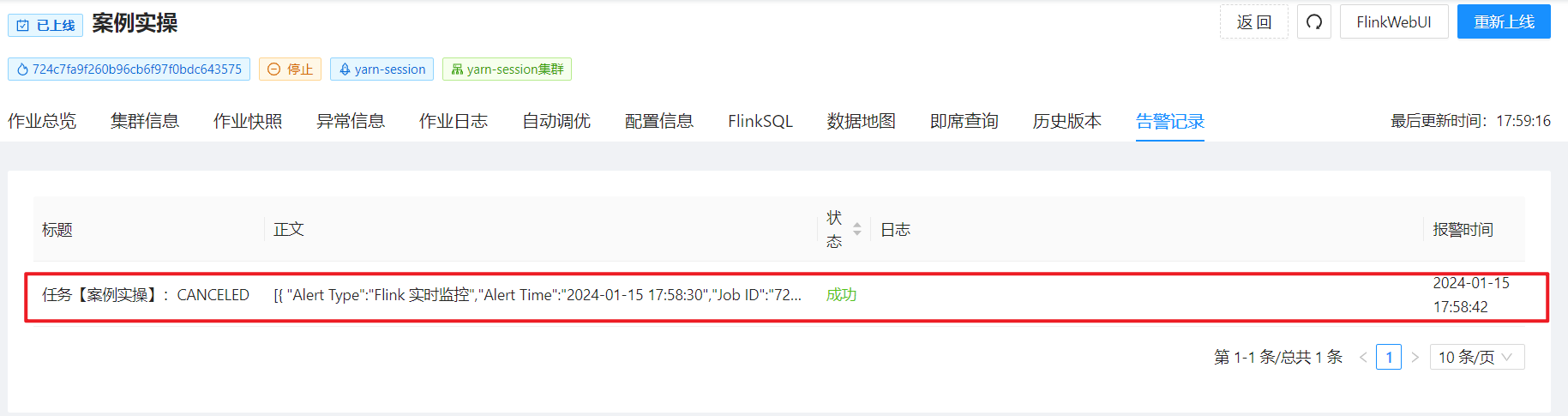
此时取消作业,会在邮箱中收到告警信息:

同时也可以在【运维中心】—【告警记录】中查看告警记录:
未完待续~
学习内容参考:尚硅谷大数据技术之Dinky(尚硅谷&Dinky官方联合推出)_哔哩哔哩_bilibili?
内容资料下载(尚硅谷官方网盘):百度网盘 请输入提取码
jar包搜索下载:Maven Repository: Search/Browse/Explore (mvnrepository.com)
pdf版本笔记下载:dinky(0.7.3)学习笔记资源-CSDN文库
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!