Spark---RDD(双值类型转换算子)
发布时间:2024年01月08日
1.RDD双值类型算子
RDD双Value算子就是对两个RDD进行操作或行动,生成一个新的RDD。
1.1 intersection
对源 RDD 和参数 RDD 求交集后返回一个新的 RDD
函数定义:
def intersection(other: RDD[T]): RDD[T]
//建立与Spark框架的连接
val rdd = new SparkConf().setMaster("local[*]").setAppName("RDD") //配置文件
val sparkRdd = new SparkContext(rdd) //读取配置文件
val data1: RDD[Int] = sparkRdd.makeRDD(List(1, 2, 3, 4))
val data2: RDD[Int] = sparkRdd.makeRDD(List(3, 4, 5, 6))
val dataRdd = data1.intersection(data2)
dataRdd.collect().foreach(println)
sparkRdd.stop(); //关闭连接
运行结果:

1.2 union
对源 RDD 和参数 RDD 求并集后返回一个新的 RDD
函数定义:
def union(other: RDD[T]): RDD[T]
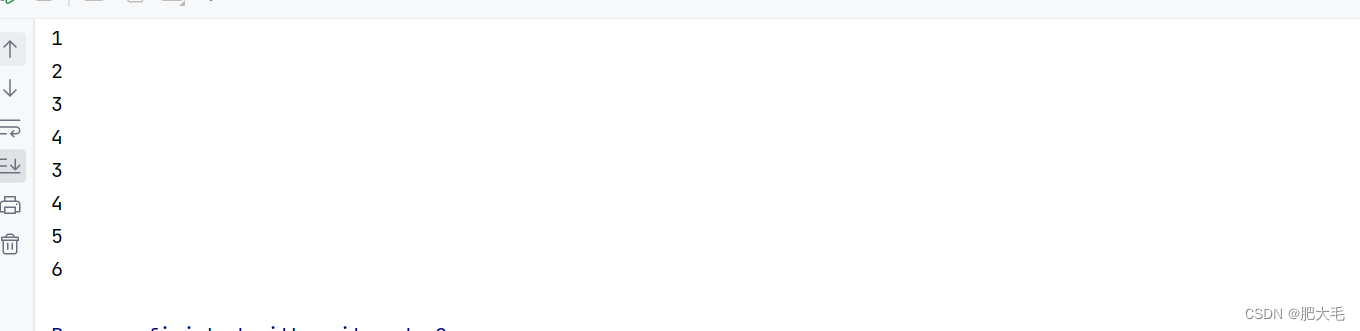
val data1: RDD[Int] = sparkRdd.makeRDD(List(1, 2, 3, 4))
val data2: RDD[Int] = sparkRdd.makeRDD(List(3, 4, 5, 6))
val dataRdd = data1.union(data2)
dataRdd.collect().foreach(println)
1.3 subtract
以一个 RDD 元素为主,去除两个 RDD 中重复元素,将其他元素保留下来。求差集
函数定义:
def subtract(other: RDD[T]): RDD[T]
val data1: RDD[Int] = sparkRdd.makeRDD(List(1, 2, 3, 4))
val data2: RDD[Int] = sparkRdd.makeRDD(List(3, 4, 5, 6))
val dataRdd = data1.subtract(data2)
dataRdd.collect().foreach(println)

1.4 zip
将两个 RDD 中的元素,以键值对的形式进行合并。其中,键值对中的 Key 为第 1 个 RDD中的元素,Value 为第 2 个 RDD 中的相同位置的元素。
函数定义:
def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)]
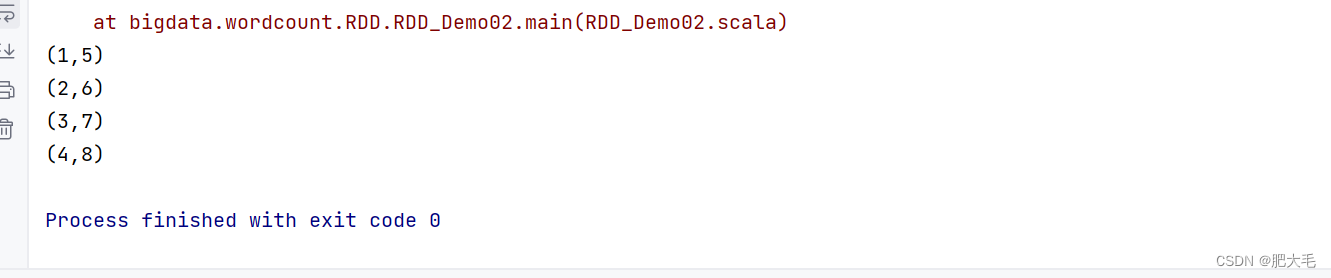
val data1: RDD[Int] = sparkRdd.makeRDD(List(1, 2, 3, 4))
val data2: RDD[Int] = sparkRdd.makeRDD(List(5,6,7,8))
val dataRdd = data1.zip(data2)
dataRdd.collect().foreach(println)
注意:如果两个RDD类型不一样,则会报错
val data1: RDD[Int] = sparkRdd.makeRDD(List(1, 2, 3, 4))
val data2: RDD[Int] = sparkRdd.makeRDD(List("hello", "scala", "hello", "Java"))
val dataRdd = data1.zip(data2)
dataRdd.collect().foreach(println)

文章来源:https://blog.csdn.net/weixin_47109902/article/details/135449869
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- BMS开发之面向对象思想(adbms1818)
- 数据挖掘实战-基于机器学习的电商文本分类模型
- 除了帆软BI,还有哪些值得关注的国产BI?
- 【vue滚动条插件vuescroll】【vue自定义滚动条】
- MQ入门—centos 7安装RabbitMQ 安装
- ctypes实现python和c之间的数据交互
- 万界星空低代码开发平台的优势
- 【论文简述】Multi-View Guided Multi-View Stereo(IROS 2022)
- 题目讲解(1到5)
- 每日一题——1295.统计位数为偶数的数字